What is database refactoring?
Database refactoring is a change in a database schema with a goal to improve a database design and retain both informational and behavior semantics.
March 14, 2014



Database refactoring is a change in a database schema with a goal to improve a database design and retain both informational and behavior semantics.
March 14, 2014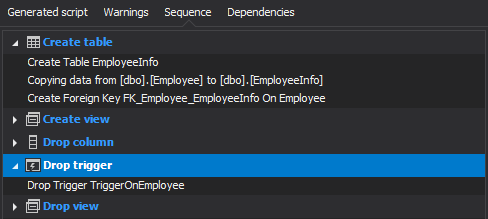
Splitting a table by moving set of columns into a new table is called vertical partitioning. Horizontal partitioning is having different tables with the same columns but contain different (distinct) sets of rows
March 10, 2014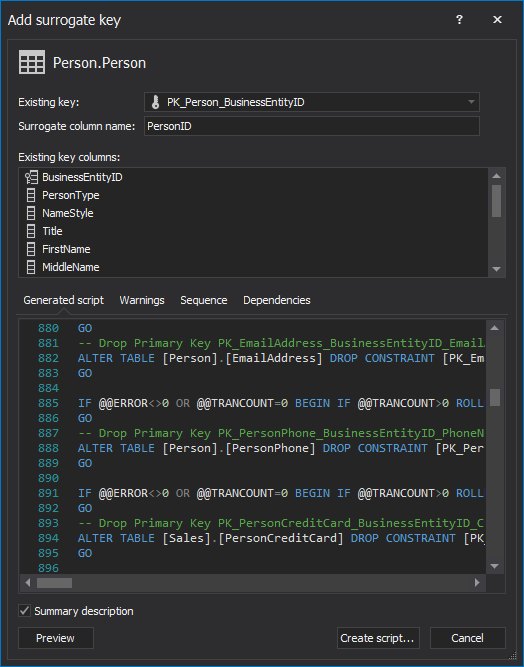
Replacing a natural key with a surrogate key is structural refactoring method of replacing an existing natural key with a surrogate key.
February 20, 2014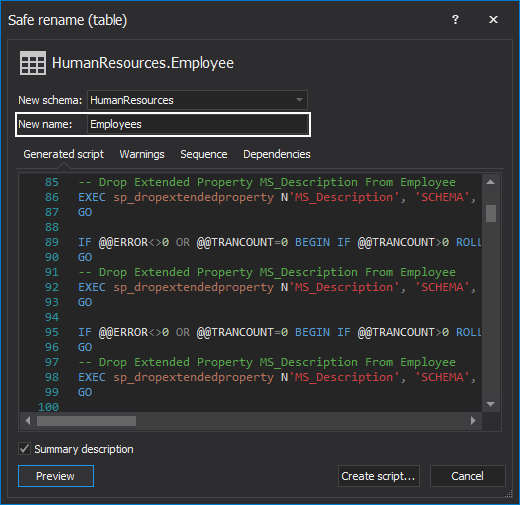
Rename table, Rename column, and Rename view are structural refactoring. The main purpose to apply Rename column, Rename table, and Rename view are increasing readability, adopting database naming conventions, or clarifying the meaning of an object. In the case of renaming objects, a cost of refactoring both database and external applications that access the database vs. an impact of the achieved readability, should be considered.
February 18, 2014In this article we’ll make an introduction in a series of articles on SQL database refactoring and solutions using ApexSQL Refactor a SSMS and VS add-in with 11 SQL database refactors
February 14, 2014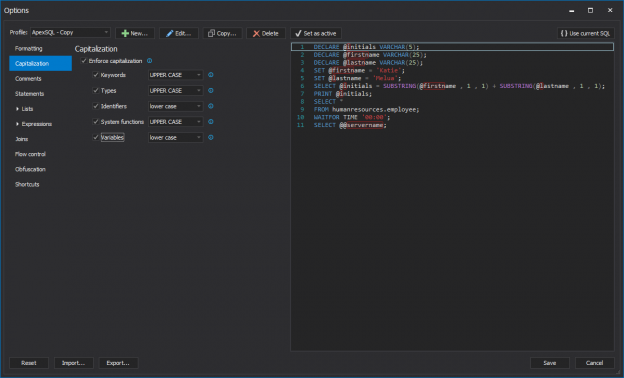
In this article, some most common guidance in naming conventions will be given and shown how ApexSQL Refactor, SQL formatting Visual Studio and SSMS add-in with nearly 200 formatting options, can help in achieving capitalization consistency among team members.
February 13, 2014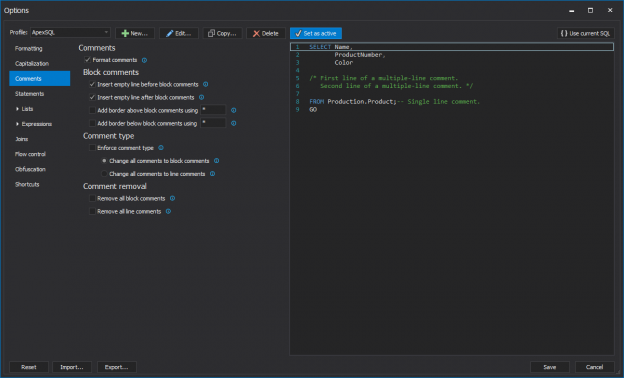
In this article, tips on T-SQL code commenting and improving productivity will be given, while using the ApexSQL Refactor’s Comments feature. ApexSQL Refactor is a SQL Server and Visual Studio SQL formatting add-in with nearly 200 formatting options.
The main purpose of comments is to document our code and write descriptions of what code is doing.
February 12, 2014This article describes some possibilities of formatting commas and spacing in T-SQL using ApexSQL Refactor SQL formatter with nearly 200 SQL formatting options.
Commas in T-SQL are used to format numbers, as list-separators, and value separators. When commas are used as separators, there is no specific rule for placing commas at the end of a line or at the beginning.
February 5, 2014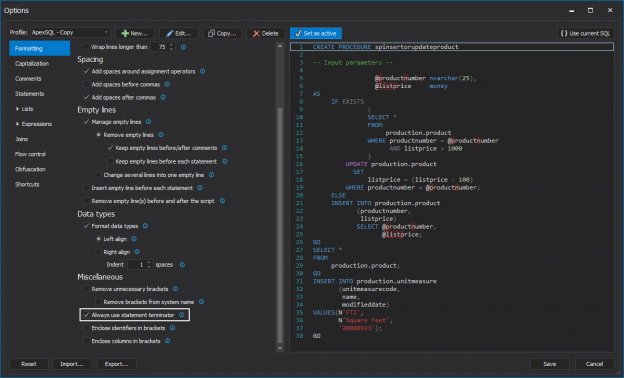
This article explains usage of a semicolon to terminate SQL statements and differences between the GO command and a semicolon.
January 20, 2014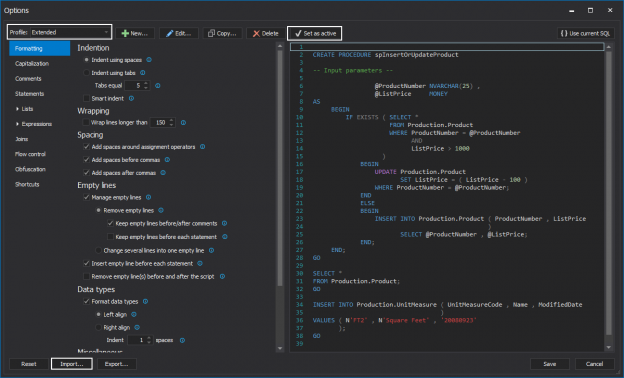
There is little formal guidance regarding SQL formatting and coding styles, but there is no universally accepted coding standard for SQL Server. In this article, though, implicit guidance will be followed from:
This article will describehow to implement these standards via ApexSQL Refactor.
January 8, 2014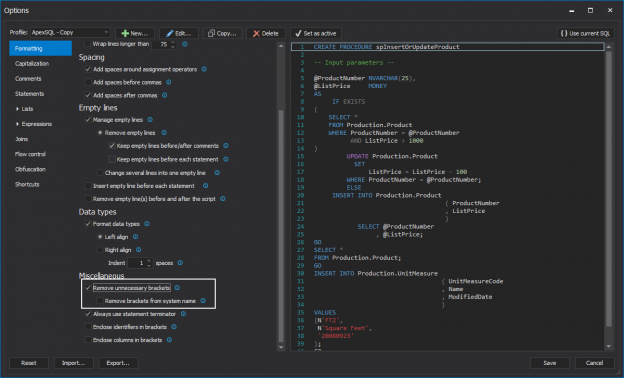
In this article, the rules for delimiting identifies and show how to avoid adding unnecessary delimited T-SQL identifiers will be discussed, when using ApexSQL Refactor SQL formatter.
December 12, 2013
A “one-to-many” relationship is one of the most common relationship types as many real world scenarios can be represented using it. For instance, the same product can be sold by more than one supplier; a customer can have more than address, and so on.
May 21, 2013The first part of the series – SQL Formatting standards – Capitalization, Indentation, Comments, Parenthesis, explains the importance of having clean SQL code. In short, deciphering someone else’s code is time-consuming. Clean and neat SQL code can be read faster; SQL reviewing and troubleshooting is more efficient; joint development efforts are more effective; handing off projects from one team to another is smoother than for inconsistently written SQL.
As there are neither style nor standards to format SQL, it’s up to the team to create its own set of formatting standards. Here are some recommendations to format joins, value lists, code structure, arithmetic, comparison and logical operations.
April 4, 2013Nobody likes to read a wall of text, even when it’s just plain text. When it comes to reading code, the problem is even bigger. Code can have different formatting styles, which could make a job either easier or more difficult. It can make code difficult to decipher and understand. A clean and neat SQL is read faster than an inconsistently written SQL; SQL reviewing and troubleshooting is more efficient; joint development efforts are more effective; handing off projects from one team to another is smoother.
April 4, 2013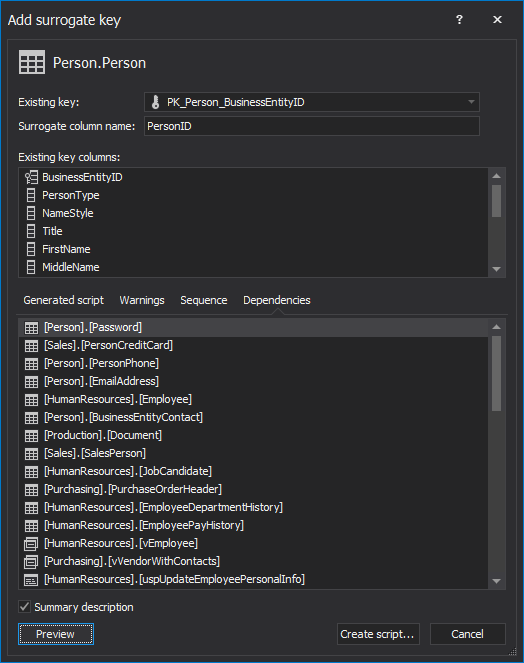
Determining just the right primary key for tables is one of the most important parts of a robust, high-quality database design. The key candidates and the keys themselves need to be picked with caution, as suboptimal choices can snowball out of control and leave the bloated, slow databases which require heavy maintenance and require massive amounts of work to meet changes in the business requirements. Therefore, due to the importance of the primary keys for the future behavior of the database, their impact on the database performance needs to be weighted as well. So, from a performance standpoint, should replacing complex natural keys with a surrogate key be considered?
April 4, 2013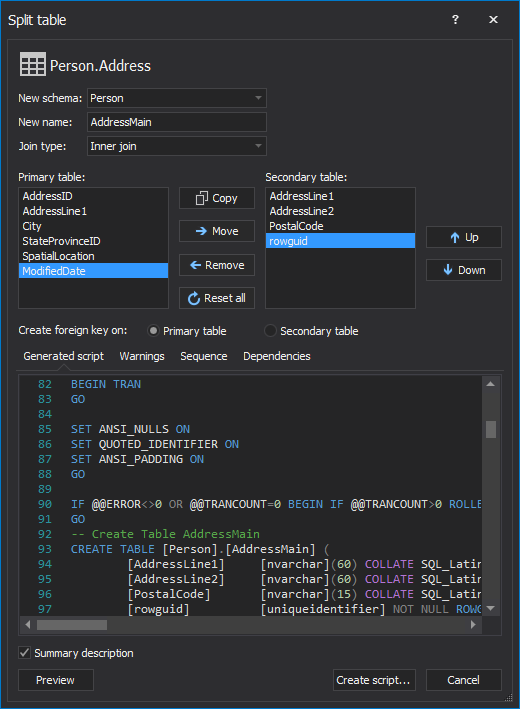
In most cases, splitting a table into two tables containing different columns is required in order to address database design changes, business requirements or even adding domain restrictions retroactively (for example, isolating currencies in a separate table and enforcing referential integrity via a foreign key to ensure that only valid currencies can be stored in the database). However, splitting tables may actually offer additional performance benefits to the database.
April 4, 2013Database performance is a challenge for every developer and DBA. Even when some improvements are made, there is always a question – is there anything else that can be done.
There might be. Some of the performance improvement techniques are not code related – a proper indexing strategy, adding memory, using different disks for data files, log files, and database backups, using faster disks, optimizing tempdb performance.
April 4, 2013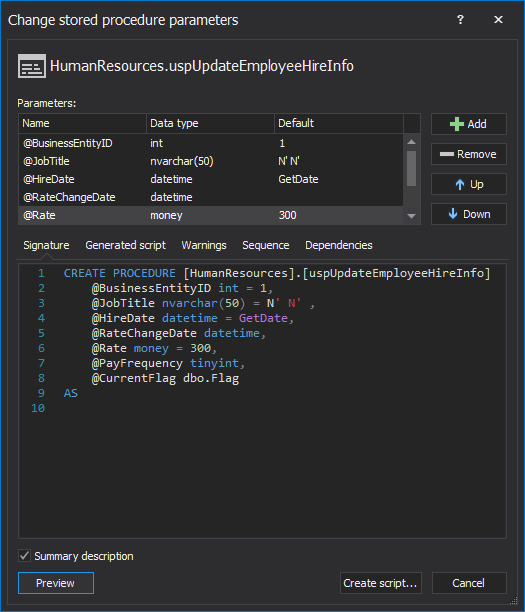
Changing the parameters of a SQL function or a stored procedure is easy – simply ALTER the function or the procedure and add or remove parameters, change the names or data types of the existing parameters and even set default parameter values. However, changing a parameter safely, in most cases, is anything but easy
April 4, 2013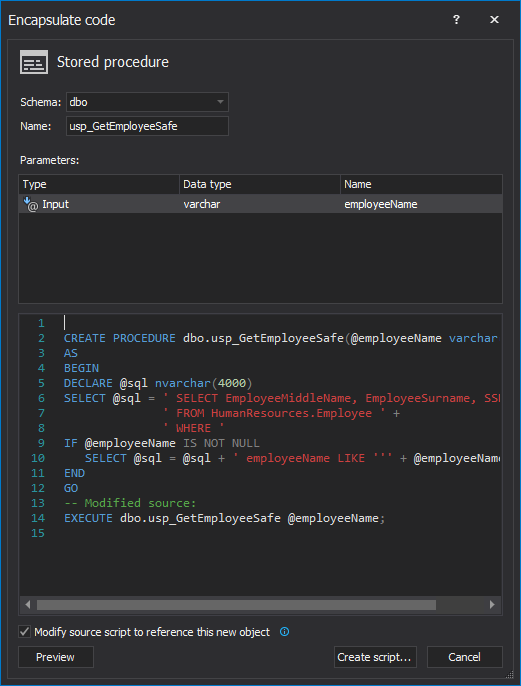
Although SQL Server’s stored procedures help with code security by hiding the implementation of the business logic and even protecting against some kinds of SQL injection attacks — primarily those that use an operator such as AND or OR to append commands onto a valid input parameter value, simply wrapping the code into a stored procedure doesn’t mean that applications, database and SQL Server are safe from all types of SQL injection attacks. So, how to make stored procedures bulletproofed against SQL injections?
April 4, 2013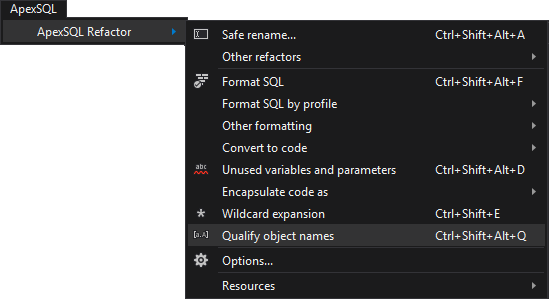
In addition to replacing the * wildcard in SELECT statements with an explicit list of column names, fully qualifying all SQL object’s names in SQL queries will boost their performance.
April 4, 2013






© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy