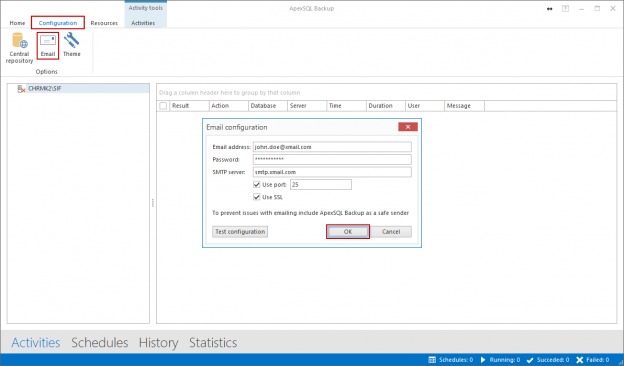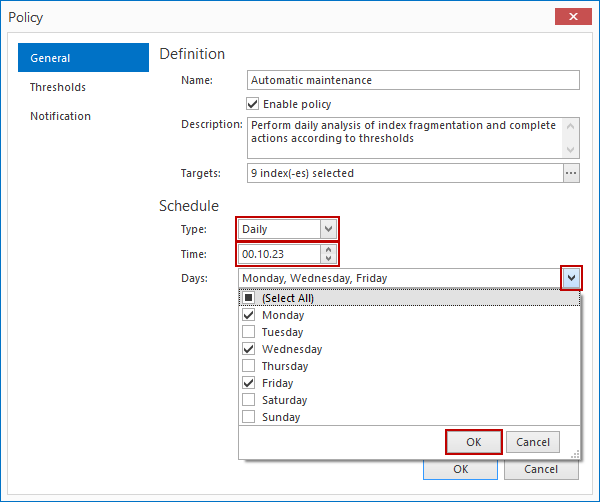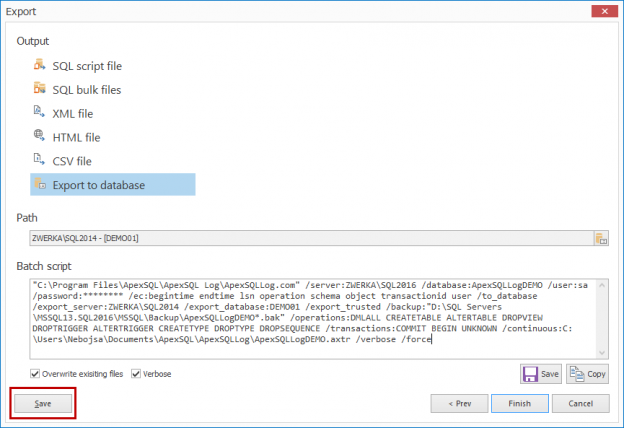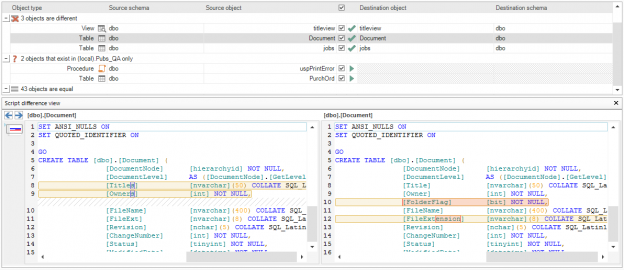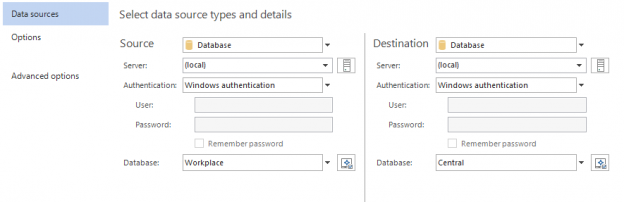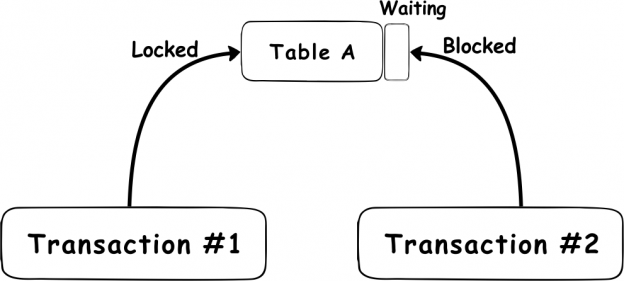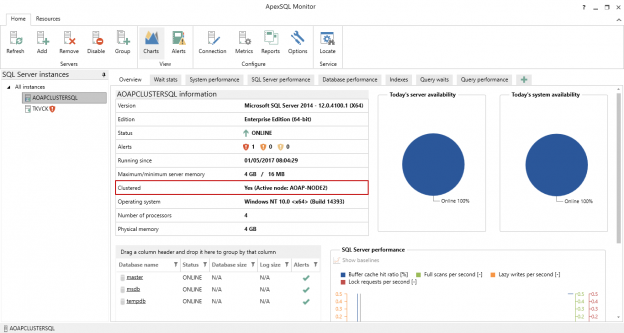
Vista general de los eventos de conmutación por error
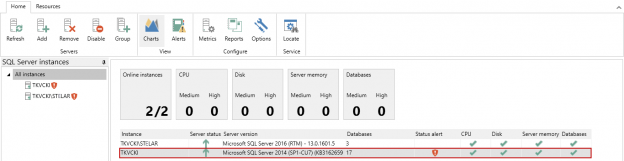
En general, los términos “conmutación por error” se refieren a cambiar de una máquina previamente activa, otro componente de hardware o red, a una pasiva (o sin uso), para sostener la disponibilidad y confiabilidadaltas. En la mayoría de casos, un evento de conmutación por error es un proceso automático, mientras que un evento similar, de cambio de servidor, requiere la intervención manual en el cambio entre elementos activos/pasivos.
diciembre 15, 2017