



Introduction
How often have you wished you could just quickly undo a DML statement without having to go through the lengthy process of restoring your database backup?
Since SQL Server 2005, SQL Server allows you to make database snapshots which can be a real life-saver when your rookie DBA just executed his last update statement without adding the WHERE clause
In this article, I am going to tell you all about SQL Server database snapshots and how they can be used to help protect your database from unwanted DML statement executions
I will also show you how you can easily undo these accidental statements in case you don’t happen to have a suitable database snapshot on hand
What is a database snapshot
Database snapshots are an Enterprise only feature which made its debut in SQL Server 2005
A database snapshot is a view of what the source database looked like at the time at which the snapshot was created. This means that all the objects will be the same as what it was when the snapshot was taken and all of the data will be exactly as it was then
To use database snapshots to recover from an unwanted DML statement, you need to have a suitable snapshot in place
Snapshots can only be created by using a T-SQL statement. Here is an example of how to create a database snapshot
CREATE DATABASE AdventureWorks2012_SS14Sep2013 ON (NAME = [AdventureWorks2012_Data], FILENAME = 'D:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\ MSSQL\DATA\AdventureWorks2012_Data_SS_14Sep2013.ss') AS SNAPSHOT OF AdventureWorks2012
In order to be able to create a database snapshot, you will need CREATE DATABASE permissions as well as db_owner on the database you want to snapshot
How does a snapshot work
There is a lot of information available regarding the inner workings of a SQL Server database snapshot, so let me just give you the headlines
- When you create a snapshot a sparse file is created for each data file
- When data is modified in the source database for the first time, the old value of the modified data is copied to the sparse file
- If the same data is the subsequently changed again, those changes will be ignored and not copied to the snapshot
- When you query the snapshot, it first checks if the data is available in the snapshot. If it’s there it reads if from the snapshot. If it’s not there, I reads through to the source database and gets the data from there instead, because that means the data has not yet changed since the time the snapshot was taken
Sparse files
When a database snapshot is created, a sparse file is added for each database file in the database of which the snapshot was taken. A sparse file is basically an empty file. It does not contain any data until a change is made to the source database
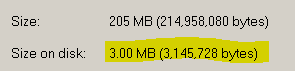
If you look at the file in Windows Explorer, it appears to have the same size as the actual data file

But if you then look at the properties of the file, you can see that this actual size is only 2.87MB. NTFS will allocate the required disk space gradually as it becomes required
Some interesting facts about sparse files:
- The maximum size a sparse file can grow to is the size of the original file at the time of the database creation
- Sparse files are limited to 16 GB on Windows 2008 and 64 GB on Windows 2003
- Sparse files grow in increments of 64 KB
- You can check if a file is a sparse file by executing the following code:
SELECT name,is_sparse FROM sys.database_files
Conditions
There are quite a few conditions to making database snapshots, here are a few things to keep in mind. This list is by no means exhaustive though
- Database snapshots depend on the source database. They can only be created on the same server as where the database resides (or the server to which the database is mirrored.)
- While there are snapshots present, you cannot drop the database or add any new files to it
- Once a database snapshot becomes suspect it cannot be saved. It just has to be deleted. This can happen if the snapshot runs out of space or reaches the maximum sparse file size limit
- You cannot create indexes on snapshots, they are strictly read only
- The user permissions are exactly the same as it was in the source database. You cannot grant a user access to a snapshot. You have to grant the access in the source database and then take another snapshot first before the user will be able to access it
What is the purpose of a database snapshot
I’m sure there are dozens or reasons why you might like to use a database snapshot, but here are my top 3
Read from your database mirror
One of the main reasons why you would want a snapshot is so that you can gain read access to your database mirror. This will allow you offload the ETL processing for your data warehouse from your production server
Protect yourself from user error
The quickest way to recover from an accidental DML statement is to select the modified data from the snapshot back into your database
The caveat to this is of course that you need a fairly recent snapshot, and you need to know exactly what data has been changed
Facilitates easy resets for test or training environments
When you have a case where each user must see the database as it was at a certain point in time, using the same server, database snapshots are definitely the way to go
For example, you have a training class to instruct users on how to configure an application. For each training class you want the configuration to be cleared from the database. Instead of restoring the entire database for each class, you can simply roll back to a database snapshot taken before the class began
To roll back to a snapshot the following script can be used
USE master GO ALTER DATABASE MYTEST SET SINGLE_USER WITH ROLLBACK IMMEDIATE GO RESTORE DATABASE MYTEST FROM DATABASE_SNAPSHOT = 'MYTEST_SS040620131300'; GO ALTER DATABASE MYTEST SET MULTI_USER GO
Keep in mind that when you roll back to a snapshot, you have to drop all other snapshots on for that database. If you don’t drop all other snapshots you will get the following error:
Msg 3137, Level 16, State 4, Line 2
Database cannot be reverted. Either the primary or the snapshot names are improperly specified, all other snapshots have not been dropped, or there are missing files.
Msg 3013, Level 16, State 1, Line 2
RESTORE DATABASE is terminating abnormally.
What is the performance impact
The bad news is that database snapshots do have a performance impact, please see the best practices offered in the next section to help you to minimize the performance impact
Creating and maintaining indexes
The time is takes to create an index is much longer when there are database snapshots on the database. The more snapshots present on the source database the longer it takes
Even though the data itself does not change, the pages are still being moved around. Since snapshots operate at page level, the moved pages are copied to the snapshot
Impact of creating snapshots on the mirror database
Depending on the configuration of the database mirroring, having a lot of snapshots on your database mirror may also impact performance on your production server
Read performance of snapshots
The performance of the snapshots themselves can be quite poor. If you want to something about it, like creating an index, you have to create the index on the source database, and then make a new snapshot to reap the benefits
What are the best practices
When planning on using database snapshots as part of your data protection strategy, there are a couple of things to keep in mind:
Name snapshots logically
If an accidental DML statement occurred, it would be useful to know simply by looking at the name of the snapshot from which snapshot to recover the data
As such it is highly recommended to include the following in the name of your snapshot:
- The source database name
- The date it was taken
- The time it was taken
Do not put your snapshot files on the same disks as the data files
To avoid disk and file contention it would be better from a performance perspective to place the snapshot files on a different disk to the source database data files
Limit the number of snapshots
Database snapshots do have a performance impact. So try to limit the number of snapshots on your database. Snapshots can also grow fairly large, so having fewer will lessen your risk of running out of disk space. Since you can have multiple snapshots at a time, and each file can grow up to the size of the original database file, this really is something to keep any eye on
Don’t keep snapshots around for too long
As I mentioned earlier, sparse file have a size limit. When one of the snapshots files of a database snapshot hits the maximum file size the snapshot will no longer be available, and give you errors such as:
The operating system returned error 1450(Insufficient system resources exist to complete the requested service.) to SQL Server during a write at offset 0x000031abb4e000 in file with handle 0x00000F74. This is usually a temporary condition and the SQL Server will keep retrying the operation. If the condition persists then immediate action must be taken to correct it
Or
The operating system returned error 665(The requested operation could not be completed due to a file system limitation) to SQL Server during a write at offset 0x000005bd3dc000 in file ‘MYTEST.mdf:MSSQL_DBCC8’
To avoid this type of error, try to keep your data files under the sparse file limit, by adding more files. That way this error can be avoided completely
Drop snapshots before index maintenance
Since snapshots affects the time it takes to perform index maintenance it’s recommended to drop snapshots before doing index maintenance or index creation if possible
How to recover from an unwanted DML statement when you don’t have a suitable snapshot
Ok, so you don’t have a recent snapshot, you don’t have time to restore a full backup. You really just want to find and roll back one stupid mistake that just happened, and ideally before the problems gets replicated elsewhere
This is where Apex SQL Log comes in. ApexSQL Log is a SQL Server transaction log reader tool, which can help you to recover from unwanted DML statements quickly and easily by reading the data in your online or backed up transaction logs , and creating an undo script to reverse the mistake
It can even identify multiple statements in a transaction and create an undo script for all of them. Which is something that might take quite a while to figure out if you had to reverse the mistake manually
For the purposes of this explanation I will use a very simplistic example
A user reports that the quantity of an item in one of his stores is incorrect. He does not know how it happened since he can’t see any sale in the system, he is not sure what the quantity was before it got changed, but he knows that this quantity was different yesterday and wants it changed back
Now if you had a database snapshot which was taken yesterday you could go and have a look at what the amount was and just change it back , but since you don’t have one , this is what you can do
-
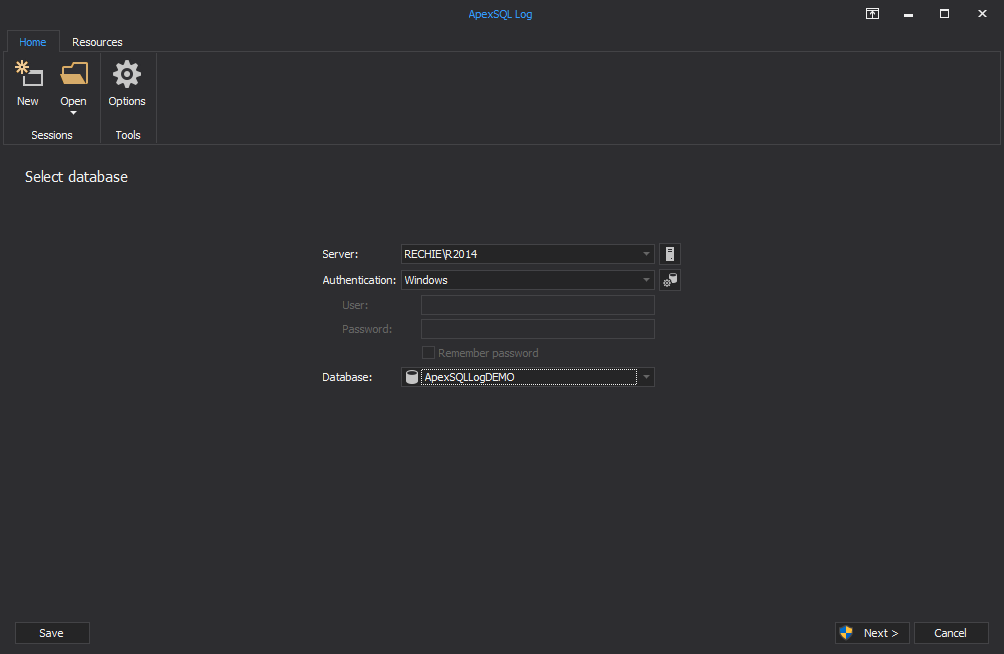
Use ApexSQL Log and open a session to the database in question:
-
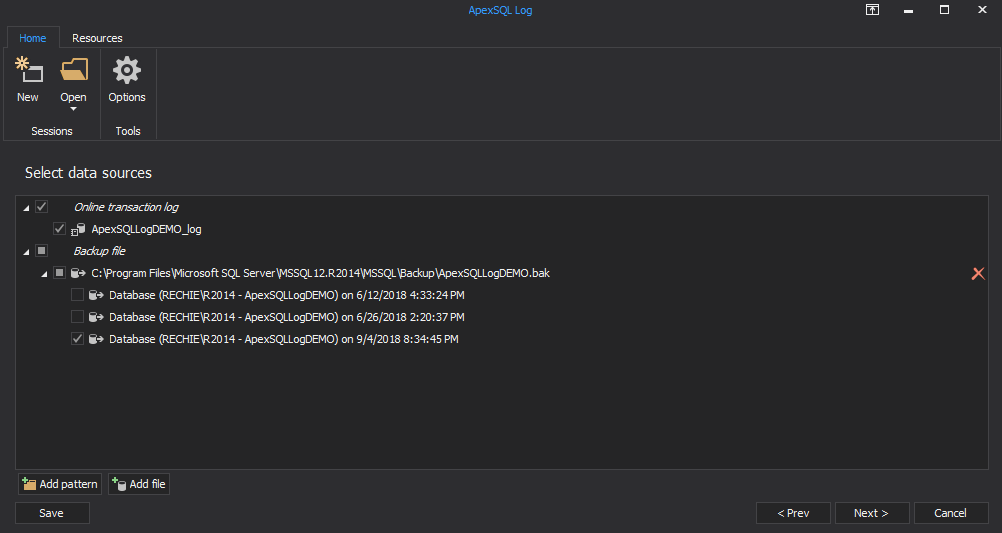
Select to include the online Log and all of the backups made in the last 24 hours
-
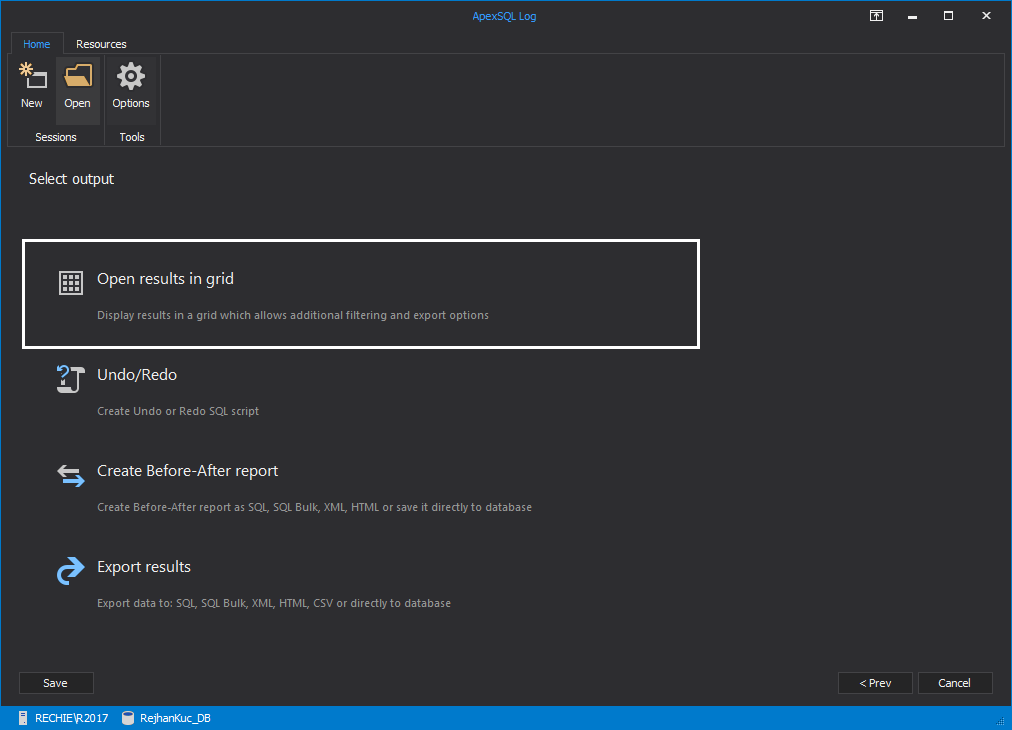
Select to open the results in grid view
-
Filter on the last 24 hours. Since the user knows that the value was still correct yesterday
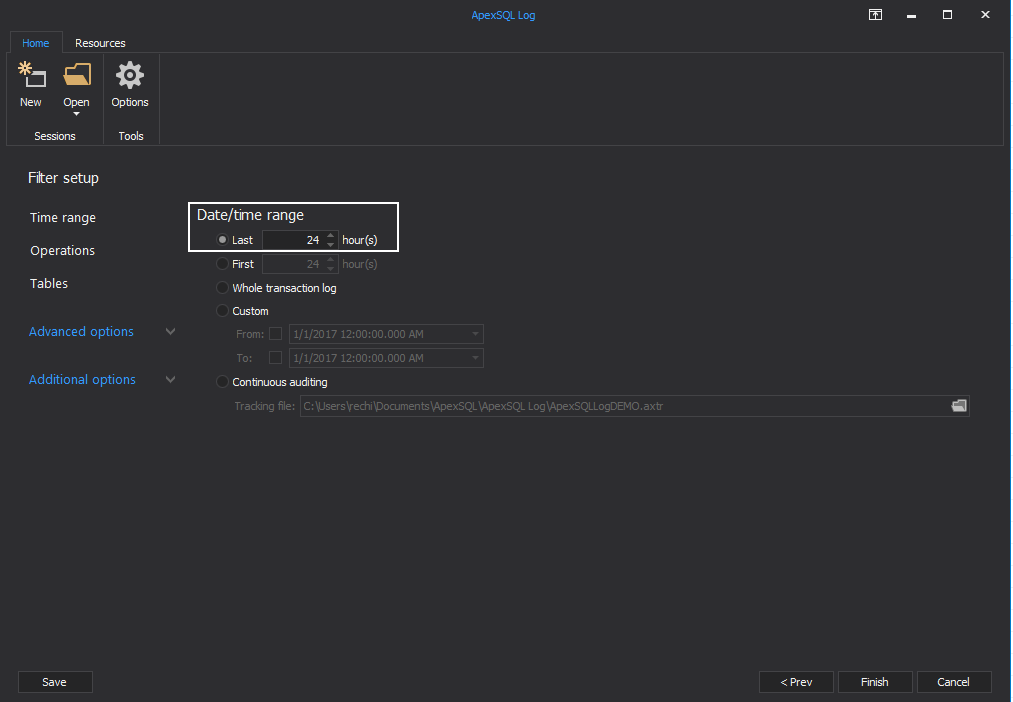
-
Look through the results until you find the update in question
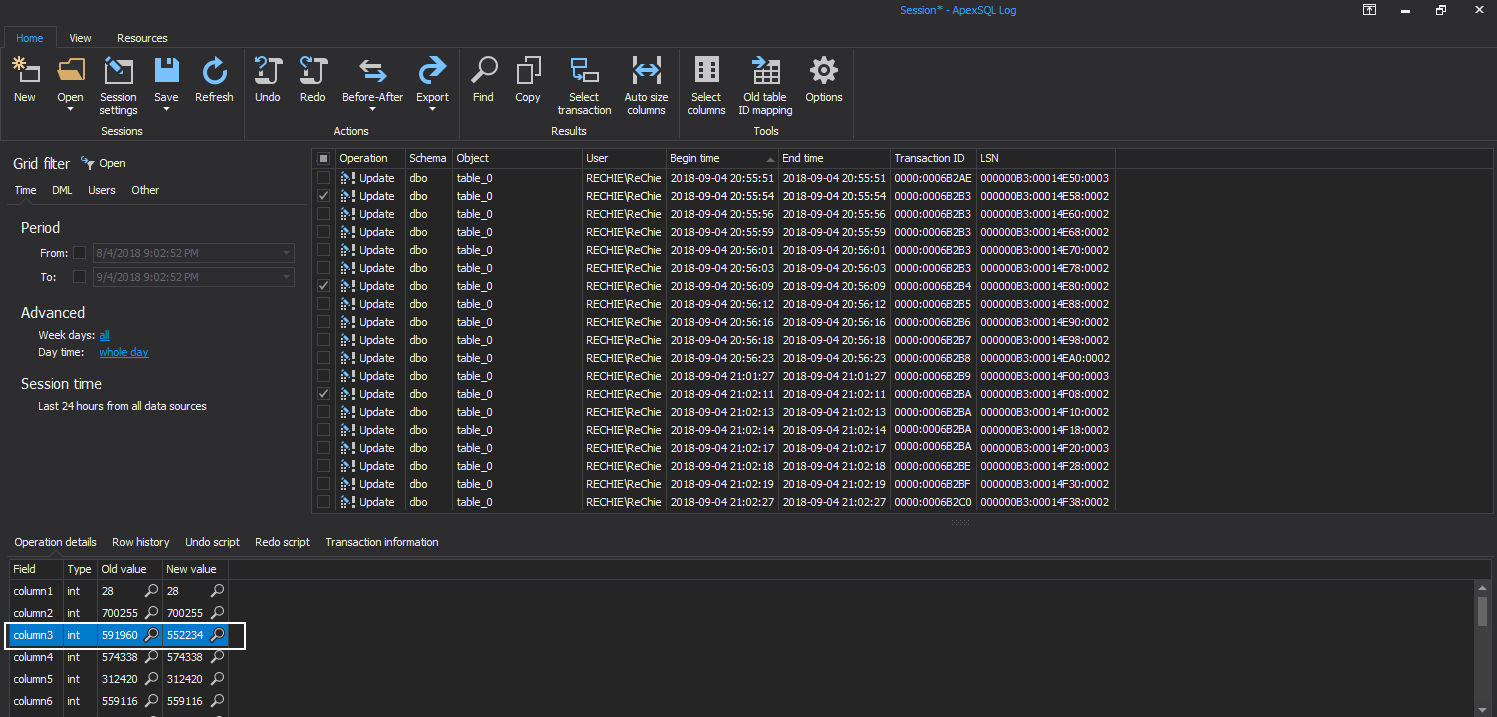
- As you can see the value has changed from being 100 to 1000
- But if you look closely you will see that there were other transactions with the same timestamp. So obviously whoever made the change did something else in the same transaction. This is something you would not be able to determine easily by just looking at a database snapshot
-
Click on the update and select the “Select transaction” operation in the main menu

- This will highlight all the rows which were a part of that transaction
-
Then click on the “Undo” button

-
This will create a script to undo all the statements which was issued as part of that transaction
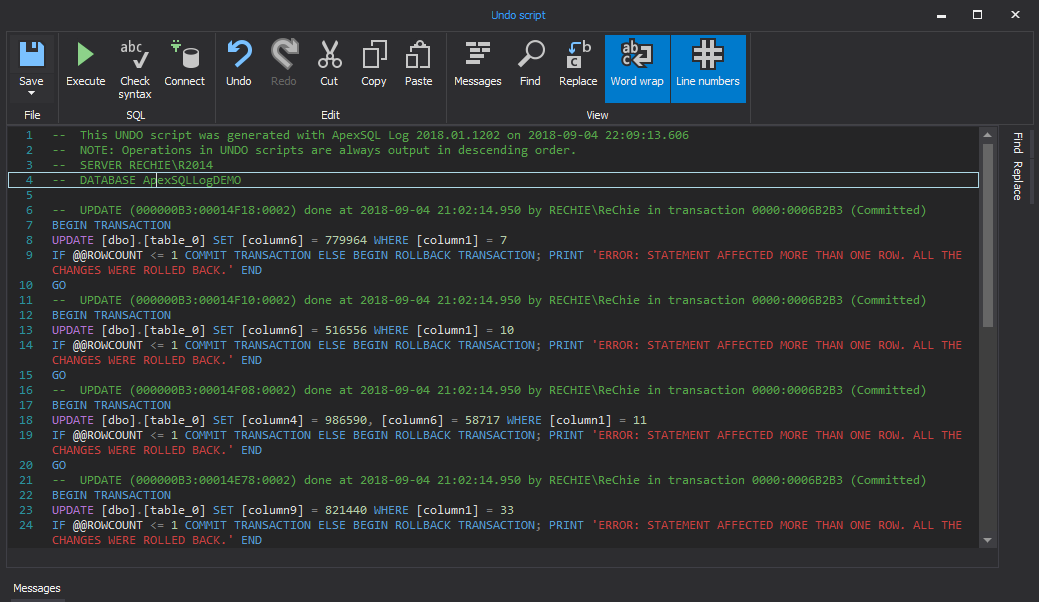
-
In conclusion
Microsoft has made great strides in simplifying the way DBA’s protect their data. With a proper strategy in place, and a little bit of luck, DBA’s are now able recover from unwanted DML statements without reverting to restoring a backup
If you have a recent snapshot you will be able to find what the original value was and revert back to it. Unfortunately having the snapshot cannot tell you what other actions were performed in the same transaction or who did it, unlike ApexSQL Log. So even though database snapshots are really helpful, I would still recommend keeping a good Log reader tool around for the times where your strategy fails you
Useful resources:
Database Snapshots (SQL Server)
View the Size of the Sparse File of a Database Snapshot (Transact-SQL)
View a Database Snapshot (SQL Server)
Downloads
Please download the script(s) associated with this article on our GitHub repository.
Please contact us for any problems or questions with the scripts.
October 22, 2013






