



El propósito del índice de SQL Server es básicamente el mismo que su pariente lejano – el índice de libros – le permite llegar a la información rápidamente, pero en lugar de navegar en un libro, indexa una base de datos SQL Server.
Los índices SQL Server son creados en un nivel de columna en tablas y vistas. Su meta es proveer una manera rápida de localizar datos basados en los valores dentro de las columnas indexadas. Si un índice es creado en la clave primaria, cuando sea que se realice una búsqueda de una fila de datos basada en uno de los valores de clave primaria, SQL Server localizará el valor buscado en el índice, y luego usará ese índice para localizar la fila completa de datos. Esto significa que SQL Server no tiene que realizar un escaneo completo de tablas cuando está buscando una fila en particular, lo cual consume muchos más recursos y tiempo.
Los índices relacionales pueden ser creados incluso antes que haya datos en la tabla especificada, o incluso en tablas y vistas en otra base de datos.
CREATE INDEX MyIndex ON MyTable (Column1);
Más acerca de CREATE INDEX Transact-SQL puede ser encontrado en MSDN.
Después de que los índices son creados, se someterán a un mantenimiento automático de parte del Motor de la Base de Datos SQL Server cuando sea que se ejecutan operaciones insert, update o delete en los datos subyacentes.
Incluso así, estas modificaciones automáticas continuamente dispersarán la información en el índice a través de la base de datos – fragmentando el índice en el tiempo. El resultado – los índices ahora tienen páginas donde el orden lógico (basado en el valor de clave) difiere del orden físico dentro del archivo de datos. Esto significa que hay un alto porcentaje de espacio libre en las páginas de índice, y que SQL Server tiene que leer un número superior de páginas cuando se escanea cada índice. También, el orden de las páginas que pertenecen al mismo índice se mezcla y esto añade más trabajo a SQL Server cuando está leyendo un índice – especialmente en términos de IO.
El impacto de la fragmentación del Índice en SQL Server puede variar de una eficiencia mermada de las consultas para servidores de impacto bajo en el desempeño, al punto donde SQL Server para completamente de usar los índices y recurre a una última solución – escaneos completos de tablas para cada consulta. Como se mencionó anteriormente, los escaneos completos de tablas impactarán drásticamente en el desempeño de SQL Server y esta es la alarma final para remediar la fragmentación de índice en SQL Server.
La solución para los índices fragmentados es volver a generar o reorganizar los índices.
Pero antes de considerar el mantenimiento de los índices, es importante responder dos preguntas principales:
1. ¿Cuál es el grado de fragmentación?
2. ¿Cuál es la acción apropiada? ¿Reorganizar o volver a generar?
Detectando fragmentación
Generalmente, para resolver cualquier problema es esencial primero que nada localizarlo y aislar el áre afectada antes de aplicar el remedio correcto.
La fragmentación puede ser fácilmente detectada corriendo la función de sistema sys.dm_db_index_physical_stats, la cual retorna el tamaño y la información de fragmentación para los datos e índices en la tabla o vista, todos los índices en una tabla o vista específicas, o versus todos los índices en todas las bases de datos:
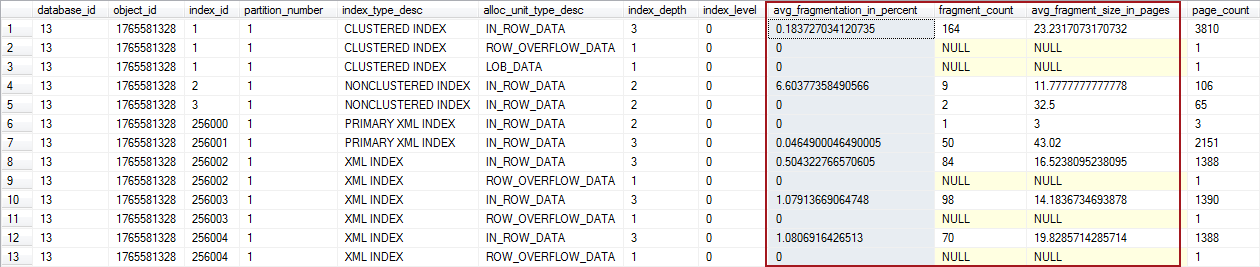
Los resultados retornados después de ejecutar los procedimientos incluyen la siguiente información:
- avg_fragmentation_in_percent – porcentaje promedio de páginas incorrectas en el índice
- fragment_count – número de fragmentos en el índice
- avg_fragment_size_in_pages – número promedio de páginas en un fragmento en un índice
Analizando resultados de detección
Después de que la fragmentación ha sido detectada, el siguiente paso es determinar su impacto en SQL Server y qué curso de acción tomar.
No hay información exacta acerca de la cantidad mínima de fragmentación que afecta a SQL Server en una manera específica para causar congestión del desempeño, especialmente dado que los ambientes SQL Server varían grandemente de un sistema a otro.
De todas maneras, hay una solución generalmente aceptada basada en el porcentaje de fragmentación (avg_fragmentation_in_percent column de la función previamente descrita sys.dm_db_index_physical_stats function).
- La fragmentación es menos que 10% – no se necesita desfragmentación. Es generalmente aceptado que in la mayoría de los ambientes la fragmentación de índice es menos que 10% a penas, y el impacto en el desempeño de SQL Server es mínimo.
- La fragmentación está entre 10-30% – se sugiere realizar una reorganización del índice.
- La fragmentación es superior a 30% – se sugiere volver a generar el índice.
Aquí está el razonamiento detrás de los márgenes anteriores, los cuales le ayudarán a determinar si usted debería volver a generar el índice o reorganizarlo:
La reorganización del índice es un proceso donde SQL Server recorre el índice existente y lo limpia. Generar de nuevo el índice es un proceso pesado donde el índice es borrado y luego recreado desde cero con una estructura enteramente nueva, libre de los fragmentos amontonados y espacios en blanco.
Mientras la reorganización del índice es una operación pura de limpieza que deja el estado del sistema como está sin bloquear tablas y vistas afectadas, el proceso de generar de nuevo el índice bloquea la tabla afectada por todo el periodo de generación lo cual puede resultar en tiempos largos de desconexión que no son aceptables en algunos ambientes.
Con esto en mente, es claro que generar el índice de nuevo es un proceso con una solución ‘más fuerte’, pero viene con un precio – posibles largos bloqueos en las tablas indexadas.
Por otro lado, la reorganización del índice es un proceso ‘liviano’ que resolverá la fragmentación de una manera menos efectiva, dado que el índice limpio siempre será segundo respecto de uno nuevo creado desde cero. Pero reorganizar el índice es mucho mejor desde el punto de vista de la eficiencia, ya que lo bloquea la tabla indexada afectada durante el curso de la operación.
Los servidores con periodos regulares de mantenimiento (por ejemplo, el mantenimiento regular los fines de semana) deberían casi siempre optar por generar de nuevo el índice, independientemente del porcentaje de fragmentación, dado que estos ambientes difícilmente serán afectados por los bloqueos de tabla impuestos por la generación del índice debido a los periodos regulares y largos de mantenimiento.
Cómo reorganizar y volver a generar el índice:
Usando SQL Server Management Studio:
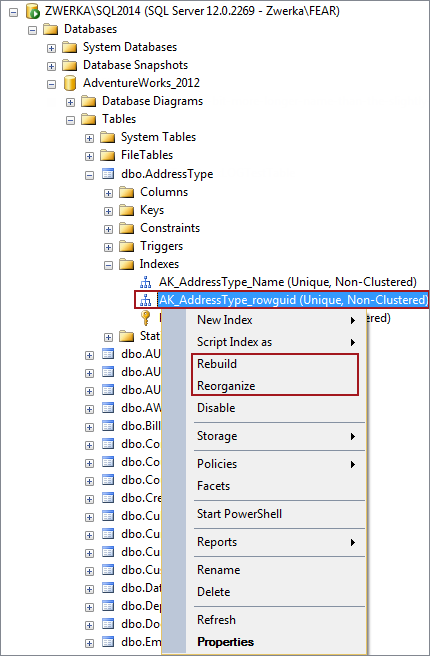
- En el panel Object Explorer expanda el servidor SQL Server y luego el nodo Databases
- Expanda la base de datos específica con el índice fragmentado
- Expanda el noto Tables y la tabla con el índice fragmentado
- Expanda la tabla específica
- Expanda el nodo Indexes
-
Haga clic derecho en el índice fragmentado y seleccione la opción Rebuild (Volver a generar) o Reorganize (Reorganizar) en el menú contextual (dependiendo de la acción deseada):
- Haga clic en el botón OK y espere a que se complete el proceso
Reorganizar índices en una tabla usando Transact-SQL
Provea los detalles apropiados de la base de datos y la tabla y ejecute el siguiente código en SQL Server Management Studio para reorganizar todos los índices en una tabla específica:
USE MyDatabase; GO ALTER INDEX ALL ON MyTable REORGANIZE; GO
Volver a generar índices en una tabla usando Transact-SQL
Provea los detalles apropiados de la base de datos y la tabla y ejecute el siguiente código en SQL Server Management Studio para volver a generar todos los índices en una tabla específica:
USE MyDatabase; GO ALTER INDEX ALL ON MyTable REBUILD; GO
Traductor: Daniel Calbimonte
agosto 23, 2016






