



Se crea una nueva base de datos SQL y todo está configurado, pero necesitan algos datos para poder probarla. La pregunta sería: ¿qué fuente de datos utilizar para rellenar la base de datos de SQL Server con datos de prueba aleatorios?
Una fuente de datos comúnmente disponible es el archivo con formato CSV (valores separados por comas) que es ampliamente soportado. Entre sus usos más comunes está el mover datos tabulares entre programas que operan nativamente en formatos incompatibles (a menudo propietarios y/o indocumentados). Esto funciona porque muchos programas soportan alguna variación de CSV al menos como un formato de importación/exportación alternativo.
Se selecciona un archivo CSV que contiene los datos de prueba y luego se debe asignar e insertar los datos. ¿Cuáles son nuestras opciones?
Importar un archivo con formato CSV utilizando SQL Server Management Studio
Una opción es utilizar SQL Server Management Studio e importar un archivo con formato CSV directamente a la base de datos mediante la opción Importar datos. Esto se puede hacer de la siguiente manera:
-
Inicie sesión en su base de datos utilizando SQL Server Management Studio
-
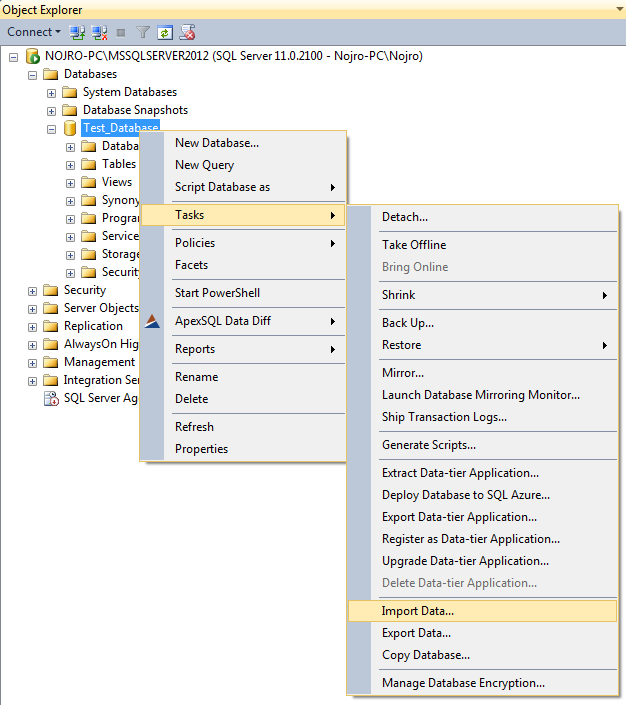
Haga clic con el botón derecho en su base de datos y seleccione Tasks ➜ Import Data, y haga clic en el botón Next
-
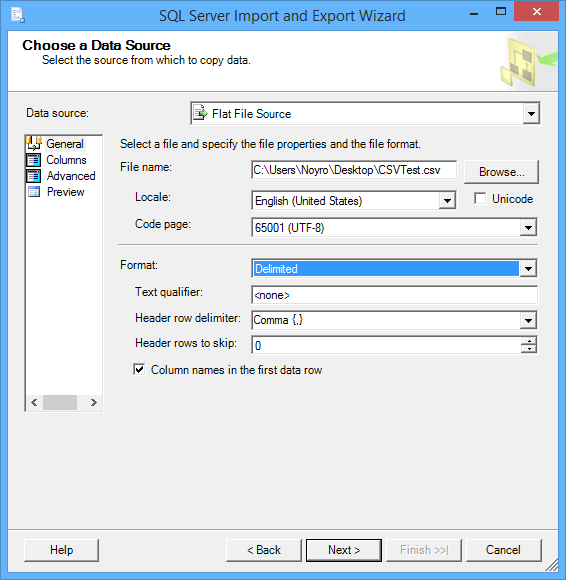
Para el origen de datos, seleccione Flat File Source. A continuación, utilice el botón Browse para seleccionar el archivo CSV. Cómo se pueden importar los datos se puede configurar antes de hacer clic en el botón Next
-
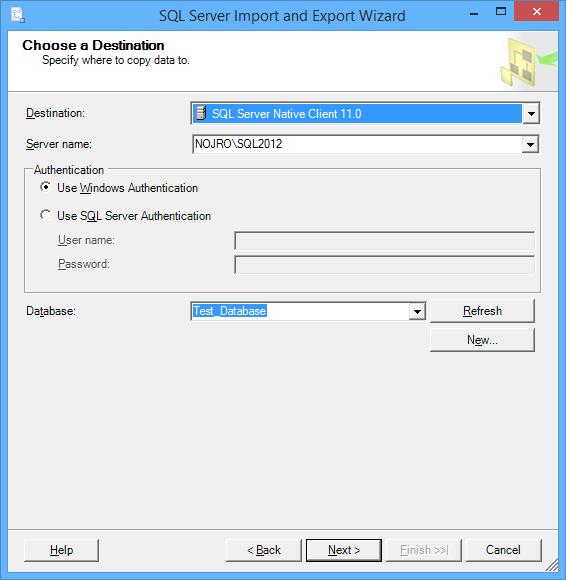
Para Destino, seleccione el proveedor de base de datos correcto (por ejemplo, para SQL Server 2012, puede utilizar SQL Server Native Client 11.0). Introduzca el Server name; seleccione Use SQL Server Authentication, ingrese el User name, Password y Base de datos antes de hacer clic en el botón Next.
-
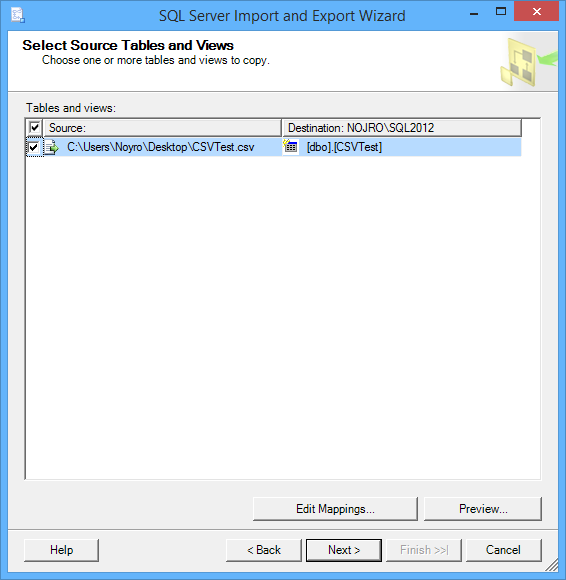
En la ventana Select Source Tables and Views, se puede configurar Edit Mappings antes de continuar.
-
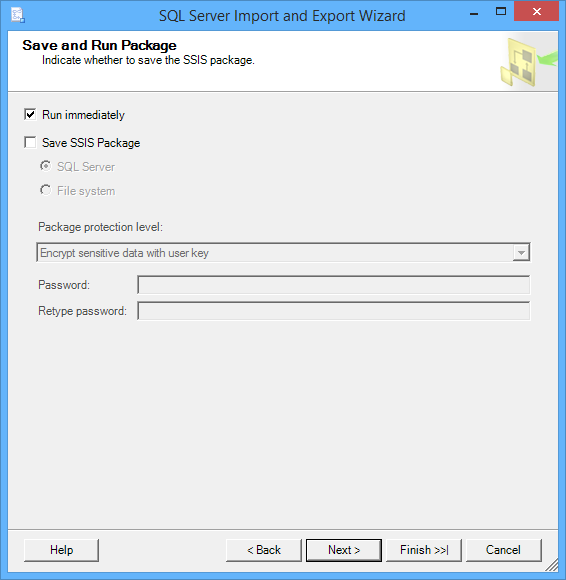
Seleccione Run immediately y haga clic en el botón Next
-
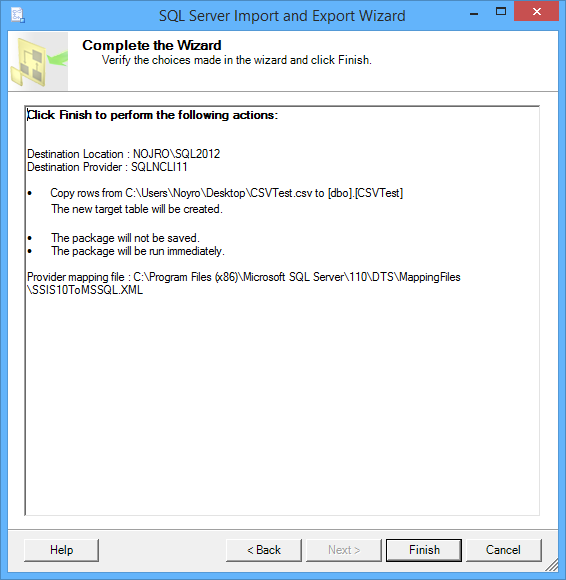
Haga clic en el botón Finish para ejecutar el paquete
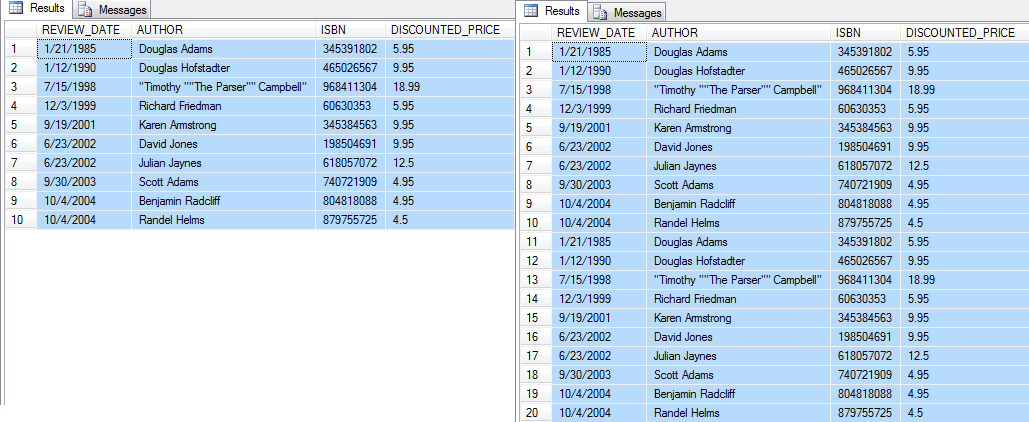
Esto es más fácil que crear un SQL insert manualmente, pero también tiene sus limitaciones. Si existe la necesidad de que miles de filas se rellenen y que el archivo CSV contenga cientos de filas de datos, no es suficiente. Esto podría solucionarse reimportando el mismo archivo CSV una y otra vez hasta que ya no sea necesario. El inconveniente de este método es que insertará grandes bloques de filas con los mismos datos, sin aleatorizarlos. La reimportación también puede ser tediosa, y sólo se puede mitigar creando un trabajo para automatizarla.
Scripts y programas de importación SQL personalizados
Otra opción sería crear una instrucción SQL insert. Los datos CSV de prueba son los siguientes:
REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE
1/21/1985,Douglas Adams,345391802,5.95
1/12/1990,Douglas Hofstadter,465026567,9.95
12/3/1999,Richard Friedman,60630353,5.95
9/19/2001,Karen Armstrong,345384563,9.95
6/23/2002,David Jones,198504691,9.95
El SQL para insertar estos datos en la tabla sería así:
INSERT INTO Sales (REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE) VALUES ('1/21/1985','Douglas Adams','345391802','5.95'); INSERT INTO Sales (REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE) VALUES ('1/12/1990','Douglas Hofstadter','465026567','9.95'); INSERT INTO Sales (REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE) VALUES ('12/3/1999','Richard Friedman','60630353','5.95'); INSERT INTO Sales (REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE) VALUES ('9/19/2001','Karen Armstrong','345384563','9.95'); INSERT INTO Sales (REVIEW_DATE,AUTHOR,ISBN,DISCOUNTED_PRICE) VALUES ('6/23/2002','David Jones','198504691','9.95');
Una de las maneras más fáciles de hacer esto es importar el CSV en Excel y con algunas fórmulas que concatenaron los elementos de datos con fragmentos SQL, se podrían crear instrucciones de inserción completas para cada fila. Simplemente copie la fórmula para procesar todas las filas. A continuación, copie las instrucciones de inserción resultantes directamente en SSMS para ejecutar. Este es un método sencillo y eficaz para un pequeño número de filas, pero se debe crear una hoja de cálculo para cada tabla y volver a importar los datos debería hacerse de forma manual. Esto requiere un conocimiento bastante amplio de las fórmulas de Excel.
Otro método simple, pero más extensible, es utilizar un lenguaje de script como PERL o VBScript para abrir programáticamente el archivo CSV y a continuación realizar un bucle a través de los datos en la memoria y construir cadenas de SQL individuales para exportar al archivo. Con algunas mejoras, tales scripts podrían hacerse lo suficientemente genéricos para abrir cualquier tabla e incluso incluir algunas personalizaciones y opciones.
Para comenzar, esto requiere amplios conocimientos de programación. Para crear un script sólido que sea útil en la mayoría de las situaciones y que no tenga que ser modificado con frecuencia se requiere esfuerzo de programación adicional, lo que fácilmente puede llevar horas de esfuerzo. Una mejor alternativa, para proporcionar un enfoque completo listo para usar a este problema, sería importar los datos en una tabla de base de datos y utilizar una herramienta comercial de SQL data scripting como ApexSQL Script para crear las inserciones de datos. Una vez que los datos CSV son importados, se puede crear un proyecto en ApexSQL Script para grabar todos los datos, repetidamente, con un solo clic del ratón.
Aún así, el scripting repetitivo de los datos de la base de datos no es un enfoque ideal para generar datos de prueba, en los cuales el objetivo es aleatorizar y ampliar el conjunto de datos, no sólo copiarlos
Las bases de datos modernas operan con grandes cantidades de datos, y esto hace que estas opciones sean ineficaces para rellenar dichas bases de datos con datos si el propósito es simular un entorno real para las pruebas.
Otra solución para rellenar la base de datos con grandes cantidades de datos aleatorios utilizando el archivo CSV es una herramienta de terceros, diseñada específicamente para crear datos de prueba en SQL Server, ApexSQL Generate.
Importar un archivo CSV utilizando ApexSQL Generate
ApexSQL Generate es una Herramienta para generar datos SQL, que tiene la capacidad de generar rápidamente millones de filas, utilizando varias fuentes de datos, con una variedad de generadores de datos.
Una de sus características es generar grandes cantidades de datos aleatorios del archivo CSV importado. El punto de partida es importar un archivo CSV con datos de prueba y rellenar columnas con él. Esto se puede hacer de la siguiente manera:
-
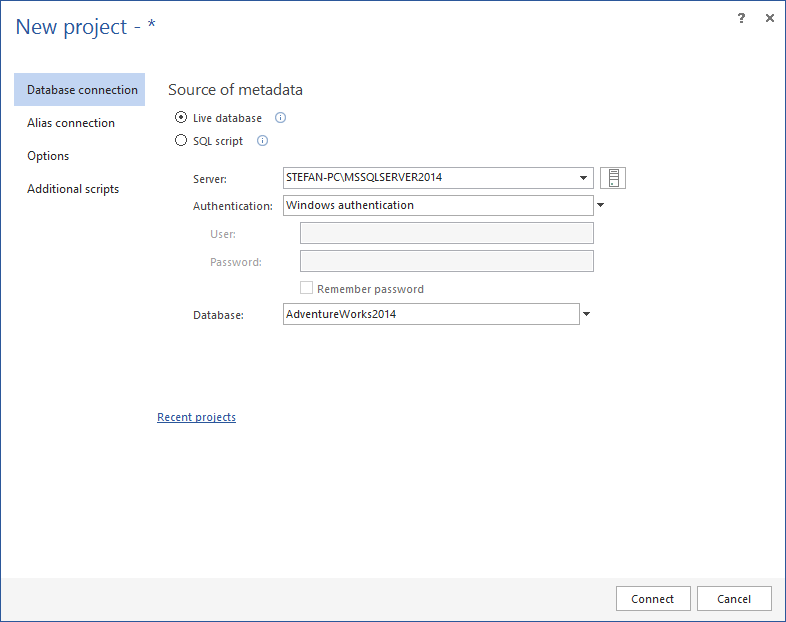
Conectarse a una base de datos utilizando la conexión de base de datos o la Conexión alias
-
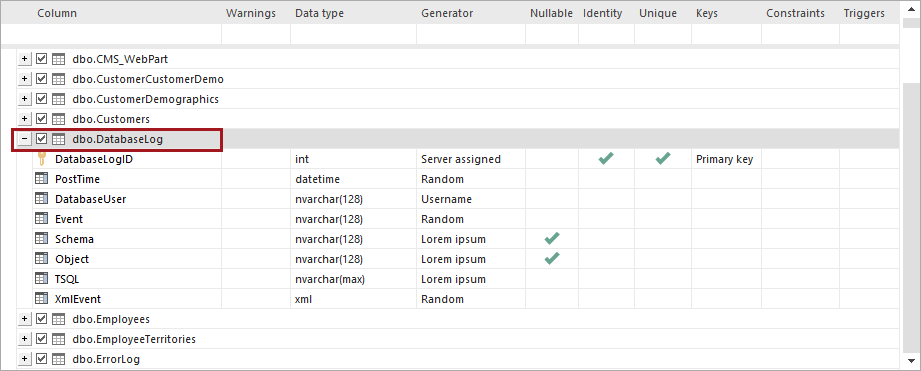
En la cuadrícula principal, seleccione la tabla para la que se generarán los datos de prueba y en las Generation options, establezca el número de filas que se generarán
-
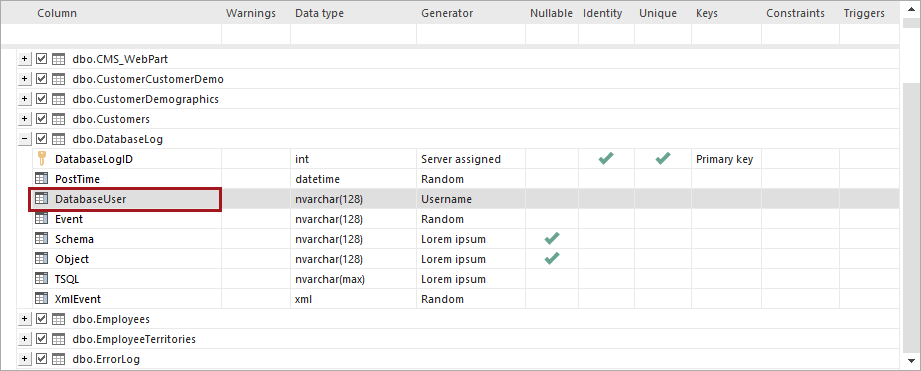
A continuación, seleccione la columna que va a rellenar con los datos
-
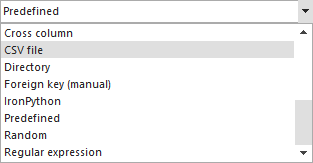
En la Lista de generadores, seleccione el archivo Desde generador From CSV file
-
Examine y seleccione el archivo CSV que va a importar utilizando el icono de carpeta, defina el delimitador utilizado en el archivo CSV escribiéndolo en el cuadro Delimiter y seleccione qué columna con datos del archivo CSV se utilizará ingresando el índice de la columna en el cuadro Column index o mediante los botones de flecha de selección. Si la primera fila de datos en un documento CSV representa el encabezado de la columna, se puede excluir marcando la opción Skip first row
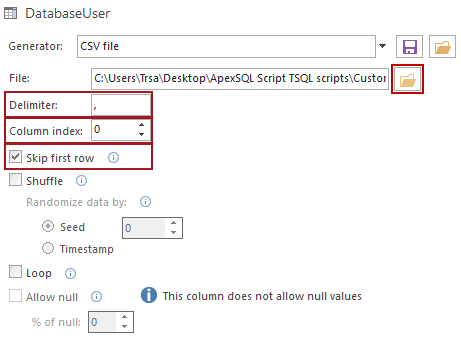
Este proceso se puede repetir para cada columna, si es necesario, utilizando el mismo archivo CSV como origen de datos, o puede importarse un nuevo archivo CSV para cada columna. Pero esto sólo importa un número limitado de filas disponibles en el archivo CSV y, por lo general, el objetivo es rellenar miles de filas, utilizando cientos de filas, con datos aleatorios. Por lo tanto, otra característica es necesaria para lograr esto.
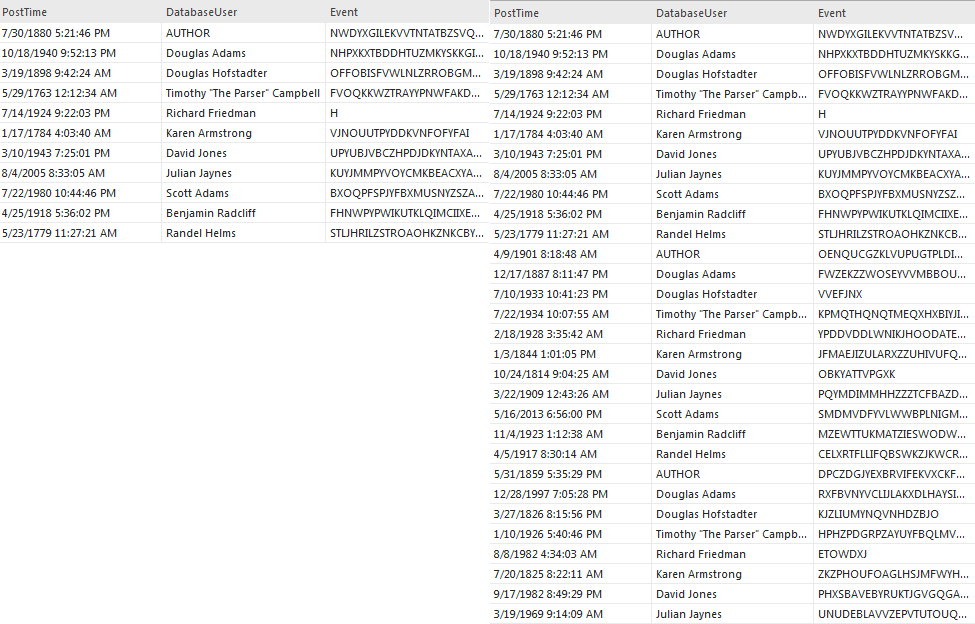
Para lograr este objetivo se utiliza la opción Loop. Esta opción copiará automáticamente los datos importados sucesivamente hasta que todas las filas que se generen se rellenen con datos. Con la opción Loop marcada, se crean bloques grandes de los mismos datos para rellenar las filas establecidas para la generación de datos de prueba. Esto permite que se expandan subconjuntos de datos más pequeños, pero el problema de los bloques de datos estáticos y predecibles permanece. Idealmente, los datos de la prueba serán aleatorizados.
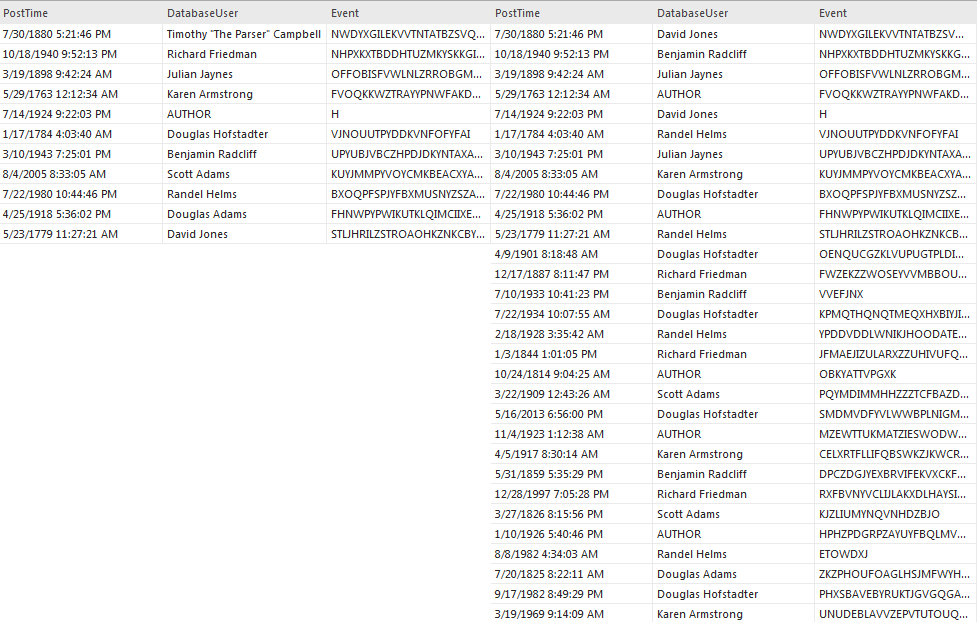
La aleatorización se logra utilizando la opción Shuffle. Las filas existentes con los datos de prueba generados se reordenan aleatoriamente después de comprobar esta opción. El efecto de aleatorización será más pronunciado a medida que aumenta el número de filas.
Después de configurar todas las opciones, el proceso de generación de datos se puede ejecutar mediante el botón Generate en la ventana principal.
Guardar y repetir el proyecto
Si hay necesidad de repetir el proceso de generación, o los datos necesitan ser actualizados, la selección y los ajustes se pueden guardar en un archivo de proyecto que se utilizará más tarde.
Después de seleccionar las tablas para las que se generarán los datos de prueba, establecer el número de filas que se generarán y asignar las columnas con datos del archivo CSV, estas opciones se pueden guardar con el botón Save as de la ventana principal.
Restaurar un proyecto guardado puede realizarse seleccionando el proyecto de la lista de proyectos recientes en la ventana New project o mediante el botón Open en la ventana principal.
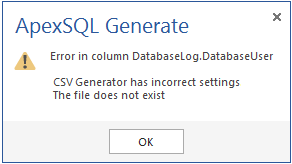
Una vez seleccionado el archivo de proyecto, la aplicación se volverá a conectar a la base de datos restaurando todas las configuraciones que implican el proceso de generación de datos de prueba, que se han establecido para tablas y generadores de datos para columnas. También se restaurarán los enlaces que conducen a los orígenes de datos externos utilizados en la generación de datos de prueba, señalando sus ubicaciones en el momento de guardar el archivo de proyecto. Si la ubicación del archivo CSV se cambia después de restaurar el archivo de proyecto, la aplicación no permitirá la generación de datos mostrando la siguiente advertencia.
Si se exporta un conjunto diferente de datos al archivo CSV, utilizando el mismo nombre de archivo, la aplicación importará automáticamente esos datos de acuerdo con la configuración del proyecto guardado. Esto se basa en la validez del enlace al archivo CSV utilizado.
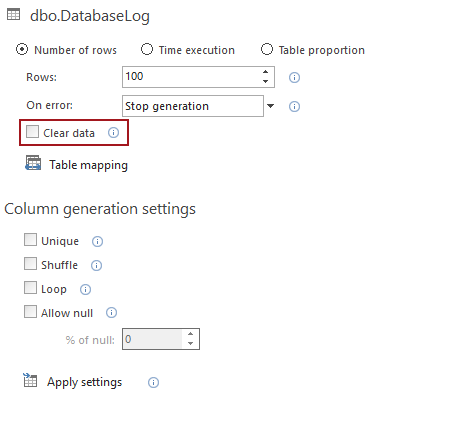
Sin embargo, para garantizar que los nuevos datos se generen sin trazas de los datos de prueba generados previamente, debe utilizarse la opción Clear data en Generation options. Esta opción elimina todos los datos antes de que se generen los nuevos datos. Se puede configurar para eliminar los datos de toda la base de datos, o para las tablas específicas elegidas, la selección se realiza en las Generation options adecuadas.
Fuentes útiles:
Generate test data using SQL
Populating a SQL server test database with random data
Generating SQL server test data with Visual Studio
febrero 23, 2017






