



Desafío
Muy a menudo, es un gran desafío mantener todas las bases de datos SQL localizadas en diferentes SQL Servers en sincronización. A medida que el tiempo pasa, muchos cambios de esquema y datos son hechos en las bases de datos de QA diariamente, los cuales requieren estar en sincronía con las bases de datos de Producción.
Para mantener todo en sincronización, debería hacer un sistema que sea gatillado o programado para realizar la comparación de todas las bases de datos SQL y sincronizar aquellas donde se detectan cambios. Este sistema debería también estar al tanto de cualquier dependencia durante la sincronización para mantener la integridad de la base de datos SQL.
Solución
Una herramienta de terceros, ApexSQL Diff, puede ser usada como una solución para este desafío, ya que puede comparar y sincronizar bases de datos SQL en línea, repositorios de control de versiones, instantáneas, copias de seguridad y carpetas de scripts. También, ApexSQL Data Diff puede ser usado para comparación de datos y sincronización de bases de datos, copias de seguridad y proyectos de control de versiones.
Durante un proceso, tanto ApexSQL Diff como ApexSQL Data Diff pueden comparar una fuente contra una base de datos SQL de destino, pero si es combinado con un script PowerShell, un sistema puede ser creado, el cual comparará y sincronizará una lista de bases de datos SQL en diferentes servidores, al igual que creará reportes, salidas y resúmenes para cada comparación.
En el siguiente ejemplo, el proceso completo será mostrado acerca de cómo comparar y sincronizar automáticamente esquemas para múltiples bases de datos SQL Server, pero ambos scripts para configurar el sistema para comparación y sincronización de esquemas y datos puede ser descargado de nuestro repositorio GitHub.
Definiendo carpetas
Lo primero, que también será el inicio del script PowerShell, es crear la función que verificará si las carpetas que contendrán los reportes creados, las salidas y los resúmenes, existen, y si estas carpetas no existen, las creará:
#existence check for Reports, Outputs, or Summaries folders, and if they don’t exist they will be created function FolderCheckAndCreate { param ( [string] $folderRoot, [switch] $reports, [switch] $outputs, [switch] $summaries ) $locations = $rootFolder #location will be set using the corresponding switch if ($reports -eq $true) { $locations += "\Reports" } if ($outputs -eq $true) { $locations += "\Outputs" } if ($summaries -eq $true) { $locations += "\Summaries" } #create none existing folder and return folder’s path if (-not (Test-Path $locations)) { New-Item -Path $locations -ItemType Directory -Force | Out-Null } return $locations }
Definiendo variables de localización
La siguiente parte es definir las variables que reconocerán la ruta actual, y configurarla como la carpeta raíz.
#variables for the current path recognition $pathCurrent = (Split-Path $SCRIPT:MyInvocation.MyCommand.Path) #system’s root folder $folderRoot = "pathCurrent"
En este caso, si una carpeta es creada en el escritorio y este script PowerShell es corrido desde ahí, la ruta actual usará la raíz de esa carpeta como el punto de inicio para crear todas las carpetas necesarias.
Luego, definamos la variable para la localización de la instalación de ApexSQL Diff. En el ejemplo siguiente, la localización de instalación por defecto es usada:
#location where ApexSQL Diff is installed $appLocation = "ApexSQLDiff.com"
La siguiente variable define el archivo de resumen de la ejecución, que será mostrado cuando todas las base de datos SQL sean comparadas y sincronizadas:
$executionSummary = "$folderRoot\ExecutionSummary.txt" Clear-Content -Path $executionSummary
La siguiente variable define la localización del archivo txt que contiene la lista de todos los SQL Servers y nombres de bases de datos que serán comparados:
#location of the txt file with server and database names $locationServersDatabases = "$pathCurrent\servers_databases.txt"
En una línea, este archivo txt contiene el nombre del servidor fuente y la base de datos, y el servidor destino y base de datos. El sistema irá a través de cada línea y correrá la comparación y sincronización para cada una:
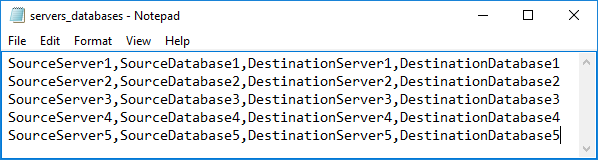
En este caso, la autenticación de Windows fue asumida. De todas maneras, la autenticación de SQL Server puede ser usada también, y usted puede encontrar más acerca de las maneras de administrar credenciales de inicio de sesión/base de datos.
Creando el sistema de sincronización de esquema
La siguiente fase en el script PowerShell es crear la función que irá a través de cada línea del archivo txt mencionado previamente:
foreach($line in [System.IO.File]::ReadAllLines($locationServersDatabases)) {
Ahora definamos las variables para los servidores fuente y destino, junto con la localización de todos los archivos de salida y sus nombres:
#defining variables for source and destination servers and databases $server1 = ($line -split ",")[0] $database1 = ($line -split ",")[1] $server2 = ($line -split ",")[2] $database2 = ($line -split ",")[3] #defining variables for location of all output files $locationReports = FolderCheckAndCreate "$folderRoot\$server2" -Reports $locationOutputs = FolderCheckAndCreate "$folderRoot\$server2" -Outputs $locationSummaries = FolderCheckAndCreate "$folderRoot\$server2" -Summaries #defining variables for date stamp and names for all output files $cleanServerName1 = ($server1 -replace "\\",".") $cleanServerName2 = ($server2 -replace "\\",".") $stampDateTime = (Get-Date -Format "MMddyyyy_HHMMss") $nameReport = "$cleanServerName2.$database2.SchemaReport_$stampDateTime.html" $nameOutput = "$cleanServerName2.$database2.SchemaLog_$stampDateTime.txt" $nameSummary = "$cleanServerName2.$database2.SchemaSummary_$stampDateTime.txt"
La siguiente variable definirá todos los interruptores necesarios de ApexSQL Diff CLI, como los servidores y bases de datos de fuente y destino, el archivo de salida, el reporte HTML y el reporte de resumen:
#defining variable for ApexSQL Diff CLI switches $schemaSwitches = "/s1:""$server1"" /d1:""$database1"" /s2:""$server2"" /d2:""$database2"" /ot:html /hro:d e s t is /on:""$locationReports\$nameReport"" /suo:""$locationSummaries\$nameSummary"" /out:""$locationOutputs\$nameOutput"" /sync /f /v /rece
En la siguiente parte, la expresión en PowerShell iniciará el proceso de comparación y sincronización del esquema para la primera línea:
#initiation of the schema comparison and synchronization process (Invoke-Expression ("& `"" + $appLocation +"`" " +$schemaSwitches)) $returnCode = $lastExitCode
La siguiente parte es “responsable” de utilizar el “código de no diferencia”, remueve todos los archivos de salida si no hay diferencias y provee un código de retorno de error correspondiente si cualquier error es encontrado:
#differences in schema are detected if($returnCode -eq 0) { #synchronize databases and create a report "`r`nSchema differences are found and a report is created. Return code is: $lastExitCode" >> "$locationOutputs\$nameOutput" } elseif($returnCode -eq 102) { #the newly created report will be removed, as no differences are found if(Test-Path "$reportsLocation\$reportName") { Remove-Item -Path "$locationReports\$nameReport" -Force:$true -Confirm:$true Remove-Item -Path "$locationSummaries\$nameSummary" -Force:$true -Confirm:$true Remove-Item -Path "$locationOutputs\$nameOutput" -Force:$true -Confirm:$true } "`r`nDifferences are not detected and the latest output files are deleted. Return code is: $lastExitCode" >> "$locationOutputs\$nameOutput" } #an error is encountered else { "`r`nAn error is encountered. Return error code is: $lastExitCode" >> "$locationOutputs\$nameOutput" "Failed for server: $server2 database: $database2. Return error code is: $lastExitCode" >> $executionSummary #the output file will be opened, as an error is encountered } }
Al final, el archivo de resumen de Ejecución será mostrado con un mensaje de que todo fue exitosamente sincronizado o con mensajes correspondientes para cada servidor destino y base de datos que no fue sincronizada exitosamente:
if ([System.IO.File]::ReadAllLines($executionSummary).Count -eq 0) { "Synchronization was successful for all data sources or no differences were detected" > $executionSummary } Invoke-Item -Path $executionSummary
Configurar la alerta de correo electrónico
Adicionalmente al sistema previamente descrito de comparación y sincronización de esquema, podemos configurar un sistema de alertas de correo electrónico, de manera que un correo electrónico con los resultados correspondientes sea enviado para notificar acerca del resumen de la ejecución cuando finalice el proceso de ejecución.
Programación del sistema
Después de que todo el sistema esté automatizado usando el script PowerShell y ApexSQL Diff, puede ser corrido ejecutando el script PowerShell con un clic. El siguiente paso es generar un programa para que el script PowerShell corra este sistema cada noche a las 2AM, por ejemplo. Para saber más acerca de la generación de programas, vea el artículo acerca de las maneras de programar herramientas ApexSQL.
Revisando los resultados del sistema
Ahora, cuando todo esté configurado, programado, revisemos lo que fue creado durante el proceso de ejecución:
- El script ejecutará la comparación y sincronización para todas las bases de datos que fueron establecidas en el archivo txt, una por una, como se especifica en las líneas.
-
Tres carpetas serán automáticamente creadas en la carpeta raíz: Reportes (Reports), Salidas (Outputs) y Resúmenes (Summaries).
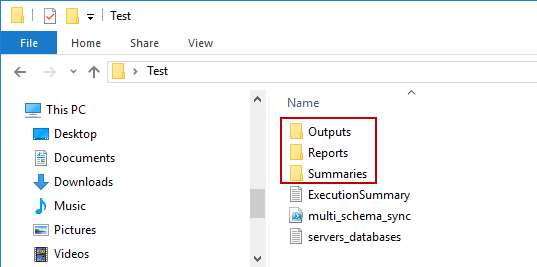
-
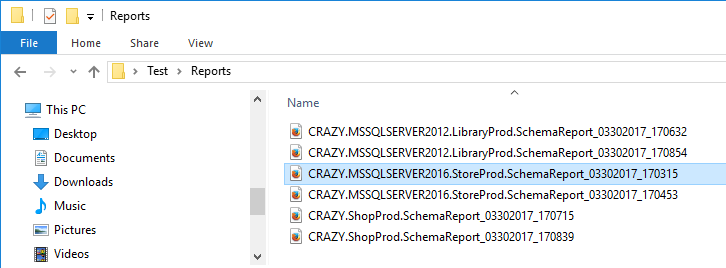
os siguientes archivos de salida serán creados en la carpeta correspondiente:
-
Reportes HTML con marca de datos y nombrados (el servidor destino y la base de datos estarán en el nombre) que contendrán las diferencias de la comparación.
Ejemplo de nombre de un reporte HTML:
DestinationServer1.DestinationDatabase1.SchemaReport_03302017_170352.html
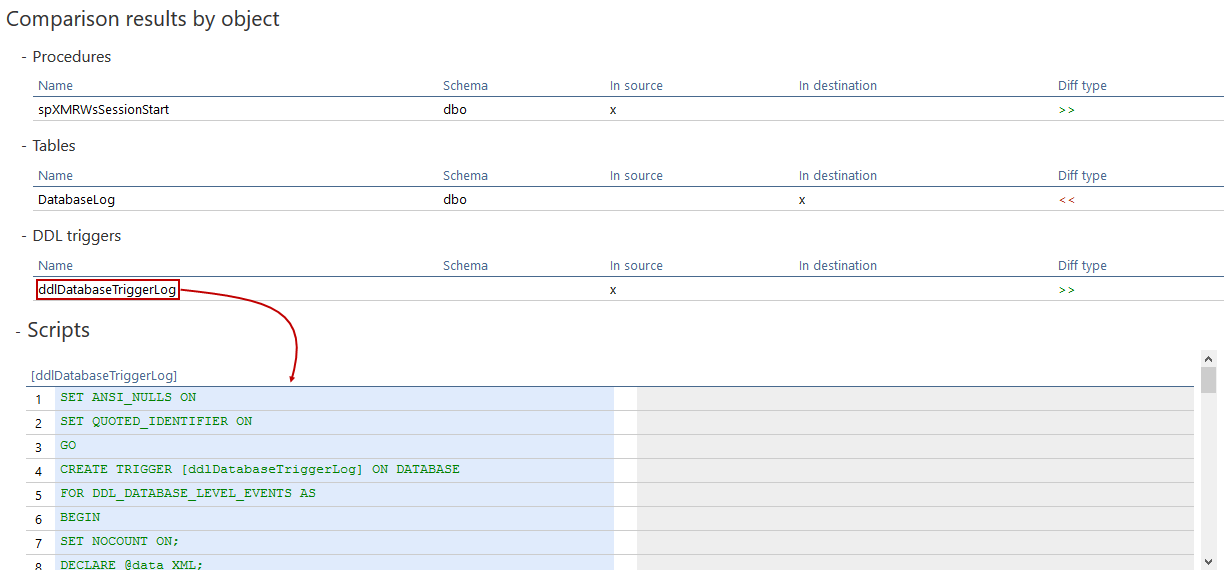
Cuando esté abierto, el reporte HTML contendrá resúmenes de Comparación y resultados de Comparación por objeto, donde los scripts pueden ser revisados también:
-
Resúmenes de sincronización con marca de datos y nombrados (el servidor destino y la base de datos estarán en el nombre) que contendrán el conteo de objetos que fueron actualizados/añadidos/eliminados.
Ejemplo de nombre de resumen:
DestinationServer1.DestinationDatabase1.SchemaSummary_03302017_170445.txt
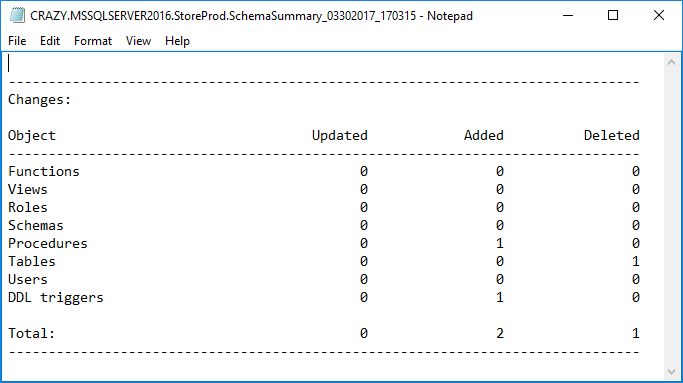
Cuando cualquiera de estos resúmenes de esquema es abierto para revisar, este contendrá una tabla con cambios que fueron hechos y, en este ejemplo, un procedimiento y un desencadenador DDL fueron añadidos a la base de datos destino, mientras que una tabla eliminada de la base de datos destino:
-
Registros con marca de datos y nombrados (el servidor destino y la base de datos estarán en el nombre) que contendrán el proceso completo desde la línea de comandos.
Ejemplo de nombre de registro de salida:
DestinationServer1.DestinationDatabase1.SchemaLog_03302017_170452.txt
Si ExecutionSummary.txt provee un error para un elemento específico de DestinationServer.DestinationDatabase, podemos fácilmente rastrear el archivo de salida específico, abrirlo y revisar cuál fue el problema:
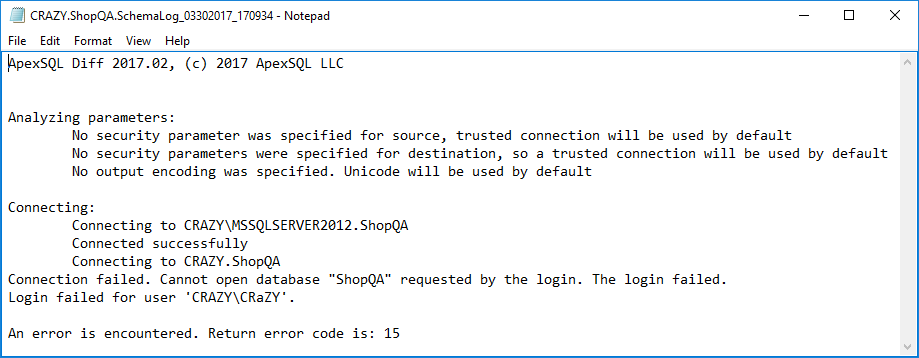
Después de seleccionar la base de datos “ShopQA” en el servidor “CRAZY”, se determina que la base de datos fue erróneamente nombrada, ya que debería ser “ShopProd” y, por lo tanto, obtenemos el mensaje mostrado arriba.
Para aprender más acerca de los códigos de error comunes que se retornan, revise el artículo acerca del Uso general e interruptores comunes de línea de comandos para herramientas ApexSQL
-
Reportes HTML con marca de datos y nombrados (el servidor destino y la base de datos estarán en el nombre) que contendrán las diferencias de la comparación.
- Para cada comparación, 3 salidas potenciales son administradas:
- Hay diferencias – las fuentes de datos serán sincronizadas y todos los archivos de salida serán creados.
- No se detectan diferencias – todos los archivos de salida creados serán removidos, ya que no hay nada que mostrar.
- Un error ocurrió – el error estará disponible para revisar en el archivo de salida en el resumen de Ejecución.
-
Una vez que todo el proceso es completado, ExecutionSummary.txt será abierto y contendrá dos posibles informaciones:
-
Un error fue encontrado durante la ejecución y el mensaje correspondiente es mostrado:
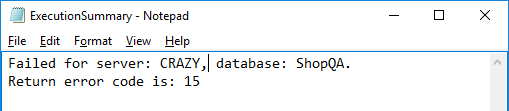
Después de analizar este problema en el archivo de registro correspondiente de registro correspondiente
-
Si no se encontraran problemas y todo estuviera exitosamente comparado y sincronizado, el siguiente mensaje será mostrado al final:
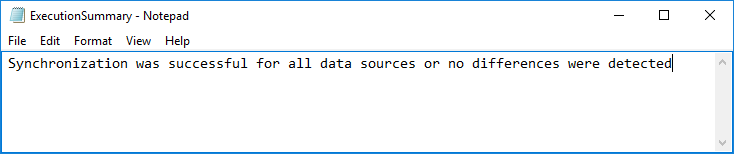
-
Un error fue encontrado durante la ejecución y el mensaje correspondiente es mostrado:
Downloads
Por favor descargue los scripts asociados con este artículo en nuestro repositorio GitHub.
Por favor contáctenos para cualquier problema o pregunta acerca de los scripts.
diciembre 8, 2017






