



Dividir una tabla moviendo un conjunto de columnas a una nueva taba es llamado particionamiento vertical. El particionamiento horizontal es tener diferentes tablas con las mismas columnas, pero conteniendo diferentes (distintos) conjuntos de filas.
¿Por qué dividir una tabla en SQL?
Muy a menudo, las razones para dividir una tabla verticalmente son relacionadas al desempeño y/o la restricción del acceso a datos. Teniendo una tabla donde la mayor parte de las aplicaciones externas acceden a un conjunto de datos más a menudo (por ejemplo, el nombre de la persona, SSN, etc.) mientras que otros datos (por ejemplo, la imagen de la persona) son requeridos menos a menudo, usted puede mejorar el desempeño dividiendo la tabla y moviendo las columnas menos accedidas a otra tabla. Esto mejorará el tiempo para recuperar los datos desde la tabla, especialmente en casos de aplicaciones que seleccionan todas las columnas de una tabla. Otro ejemplo de particionamiento vertical de tablas es restringir el acceso a alguna información dentro de una tabla (por ejemplo, salario, contraseña, información de ingreso, etc.). Dividiendo una tabla y moviendo las columnas que desea proteger usted puede asignar diferentes derechos de acceso a una tabla que contiene datos sensitivos.
División vertical de tablas
Mostraremos un ejemplo de particionamiento vertical de la tabla Employee para restringir el acceso a la columna Salary.
La estructura actual de la tabla Employee es mostrada aquí:
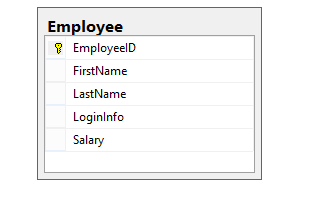
Para implementar la refactorización de división de tablas SQL, usted necesita hacer lo siguiente:
-
Introduzca una nueva tabla usando CREATE TABLE. También puede que encuentre útil usar una tabla existente que pueda ser adecuada para mover ahí las columnas.
Aquí, introduciremos una tabla EmployeeInfo con información acerca del salario del empleado y los detalles de ingreso:
CREATE TABLE EmployeeInfo ( LoginInfo varchar(20) PRIMARY KEY, Salary varchar (20) )
-
Copie los datos desde la tabla Employee a la tabla EmployeeInfo.
INSERT INTO EmployeeInfo (LoginInfo, Salary) SELECT DISTINCT LoginInfo, Salary FROM Employee
-
En el period de transición, en el caso de un ambiente de múltiples aplicaciones, usted necesitará introducir desencadenadores en la tabla Employee para mantener las columnas que pertenecen a la tabla común sincronizada. Los desencadenadores deben ser invocados por cualquier cambio a la tabla Employee.
Los desencadenadores en la tabla Employee:
CREATE TRIGGER TriggerOnEmployee ON Employee AFTER INSERT, UPDATE AS BEGIN INSERT INTO dbo.EmployeeInfo ( LoginInfo, Salary ) SELECT i.LoginInfo, i.Salary FROM INSERTED i END CREATE TRIGGER TriggerOnEmployeeDelete ON dbo.Employee AFTER DELETE AS DELETE FROM dbo.EmployeeInfo WHERE LoginInfo IN ( SELECT d.LoginInfo FROM DELETED d) GO
-
Cree la relación referencial entre tablas:
ALTER TABLE Employee ADD CONSTRAINT fk_Login FOREIGN KEY ( LoginInfo ) REFERENCES EmployeeInfo ( LoginInfo ) GO
-
Elimine la columna Salary de la tabla Employee:
ALTER TABLE Employee DROP COLUMN Salary GO
La tabla particionada tendrá la siguiente estructura:
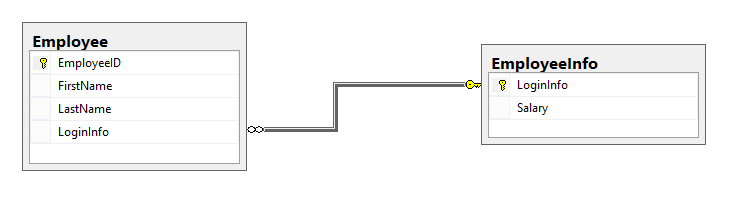
Usted también necesitará rescribir todos los procedimientos, vistas y objetos dependientes, así como aplicaciones externas que acceden y referencian la tabla para reflejar los cambios. Si hay consultas que involucran columnas de ambas nuevas tablas, el motor de procesamiento de consultas requeriría combinar dos particiones de las tablas para recuperar los datos. En este ejemplo, tenemos la vista EmployeeView que recupera todas las columnas de la tabla Employee, y rescribiremos esta vista usando INNER JOIN para obtener los datos desde ambas tablas:
Antes:
CREATE VIEW EmployeeView AS SELECT * FROM dbo.Employee
Después:
ALTER VIEW dbo.EmployeeView AS SELECT Employee.EmployeeID, Employee.FirstName, Employee.LastName, Employee.LoginInfo, EmployeeInfo.Salary FROM ( dbo.Employee INNER JOIN dbo.EmployeeInfo ON Employee.LoginInfo = EmployeeInfo.LoginInfo ) GO
Usando ApexSQL Refactor, un aditamento de refactorización de VS y SSMS con características de refactorización de bases de datos, usted puede dividir una tabla usando la característica Split Table. Elija una tabla desde Object Explorer y desde el menú ApexSQL Refactor seleccione la característica Split Table.
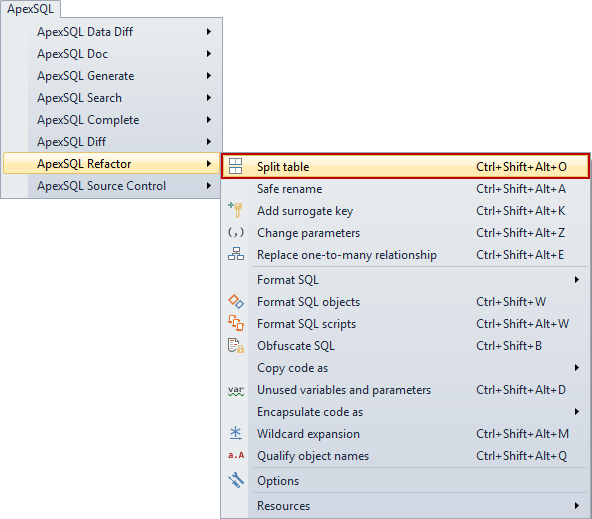
Usted también puede hacer clic derecho en una tabla en el panel de Object Explorer y seleccionar el comando Split Table desde el menú contextual ApexSQL Complete. Usaremos la tabla Employee de nuevo:

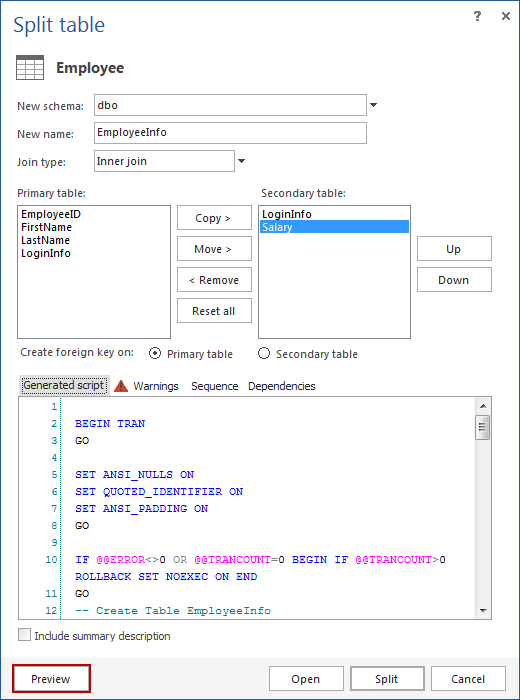
En el diálogo Split Table usted necesita ingresar un nombre para la nueva tabla que está creando. La llamaremos EmployeeInfo como en el ejemplo previo.
También, usted necesita especificar si desea que se cree una clave foránea en la tabla primaria o secundaria. En este ejemplo, eso determina que esta división de tabla es para una relación uno a uno, y configuraremos la clave foránea en la tabla primaria.
Usted necesita mover las columnas que desea a la otra partición. Una columna necesita ser copiada desde la tabla primaria para mantener la integridad referencial de las tablas particionadas. Copiaremos LoginInfo para integridad referencial, y moveremos la columna Salary.
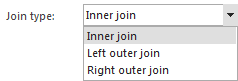
ApexSQL Refactor ofrece la opción de elegir el tipo de sentencia JOIN. Como previamente mencionamos, esto es necesario si usted tiene consultas que recuperan datos de todas las columnas las cuales ahora serán particionadas en dos tablas:
Cuando usted configure el particionamiento, haga clic en Preview para ver el script creado:
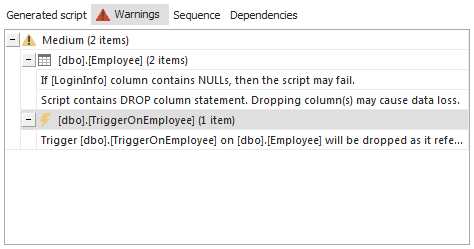
La sección Warnings le informará de cualquier problema potencial debido a la división de la tabla:
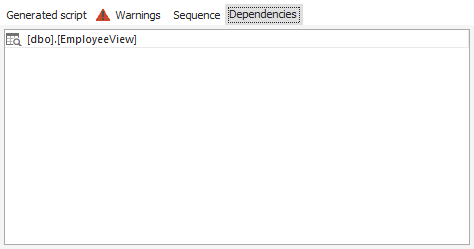
Todas las dependencias serán listadas en la sección Dependencies, que en este caso es la vista EmployeeView que recupera todas las columnas de la tabla:
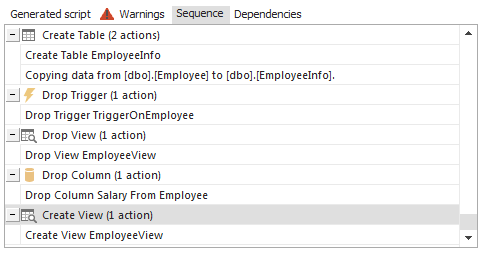
La sección Sequence le dará los pasos exactos en el proceso de dividir su tabla, la cual le mostrará las acciones de refactorización en el orden en que ocurren:
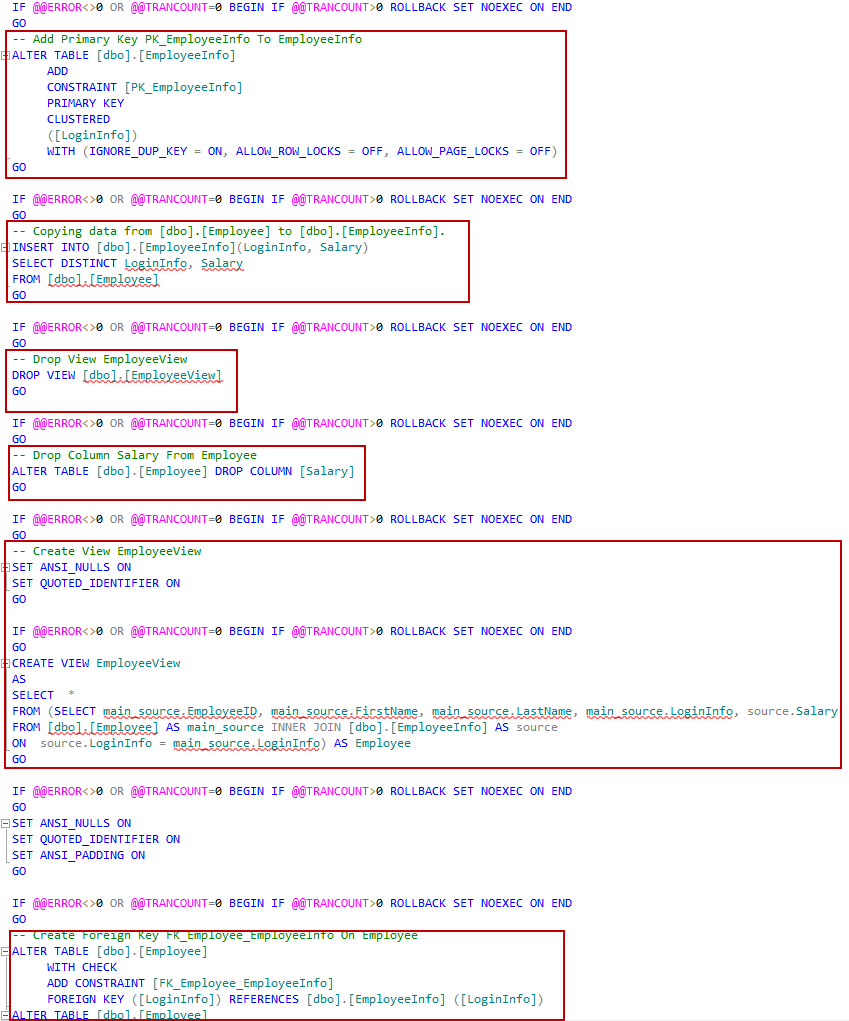
Para ver y editar el script generado en la ventana de consultas de SSMS, haga clic en el botón Open. Usted puede ver que el script en la ventana de consultas contiene todos los pasos necesarios para dividir automáticamente la tabla y actualizar todas las dependencias:
Recursos útiles:
Partitioning
Vertical Partitioning as the way to reduce IO
Top 10 steps to optimize data access in SQL Server: Part V (Optimize database files and apply partitioning)
Traductor: Daniel Calbimonte
octubre 16, 2016






