



Splitting a table by moving set of columns into a new table is called vertical partitioning. Horizontal partitioning is having different tables with the same columns but contain different (distinct) sets of rows
Why split a table in SQL?
Most often, the reasons for splitting a table vertically are performance related and/or restriction of data access. Having a table where most of the external applications access one set of data more often (e.g. persons’ name, SSN etc.) while other data (e.g. person’s picture) is required less, often the performance can be improved by splitting the table and move the less accessed columns into another table. This will improve the time to retrieve data from a table, especially in cases of applications that select all columns from a table. Another example of vertical table partitioning is restricting access to some information within a table (e.g. salary, password, login information etc.). By splitting a table and moving columns that need to be protected, different access rights to a table that contains sensitive data can be assigned.
Vertical table splitting
An example of vertical partitioning of the Employee table to restrict access to the Salary column will be shown in the following example.
The current structure of the Employee table is shown here:
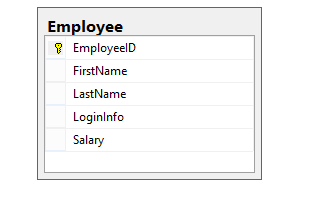
To implement split table SQL refactoring the following needs to be done:
-
Introduce a new table using CREATE TABLE. It may be useful to use an existing table that may be suitable to just move the columns into.
Here, the table EmployeeInfo will be introduced with information about the employee’s salary and the login details:
CREATE TABLE EmployeeInfo ( LoginInfo varchar(20) PRIMARY KEY, Salary varchar (20) )
-
Copy data from the Employee table to the EmployeeInfo table:
INSERT INTO EmployeeInfo (LoginInfo, Salary) SELECT DISTINCT LoginInfo, Salary FROM Employee
-
In the transition period, in the case of a multi-application environment, triggers need to be introduced on the Employee table to keep the columns that belong to a common table synchronized. The triggers must be invoked by any change to the Employee table.
Triggers on the Employee table:
CREATE TRIGGER TriggerOnEmployee ON Employee AFTER INSERT, UPDATE AS BEGIN INSERT INTO dbo.EmployeeInfo ( LoginInfo, Salary ) SELECT i.LoginInfo, i.Salary FROM INSERTED i END CREATE TRIGGER TriggerOnEmployeeDelete ON dbo.Employee AFTER DELETE AS DELETE FROM dbo.EmployeeInfo WHERE LoginInfo IN ( SELECT d.LoginInfo FROM DELETED d) GO
-
Create the referential relationship between tables:
ALTER TABLE Employee ADD CONSTRAINT fk_Login FOREIGN KEY ( LoginInfo ) REFERENCES EmployeeInfo ( LoginInfo ) GO
-
Drop the Salary columns from the Employee table:
ALTER TABLE Employee DROP COLUMN Salary GO
The partitioned table will have the following structure:
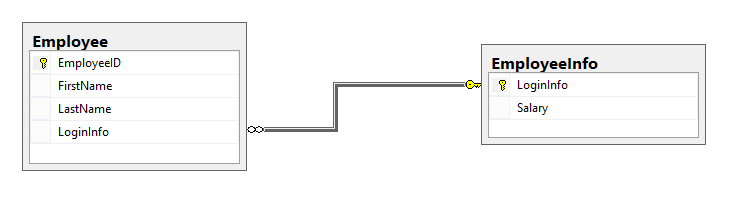
Also all procedures, views and dependent objects, as well as external applications that access and reference the table to reflect the changes need to be rewritten. If there are queries that involve columns from both new tables the query processing engine would require joining two partitions of the tables to retrieve data. In this example, the EmployeeView view that retrieves all columns from the Employee table and rewriting this view using INNER JOIN to get the data from the both tables are shown:
Before:
CREATE VIEW EmployeeView AS SELECT * FROM dbo.Employee
After:
ALTER VIEW dbo.EmployeeView AS SELECT Employee.EmployeeID, Employee.FirstName, Employee.LastName, Employee.LoginInfo, EmployeeInfo.Salary FROM ( dbo.Employee INNER JOIN dbo.EmployeeInfo ON Employee.LoginInfo = EmployeeInfo.LoginInfo ) GO
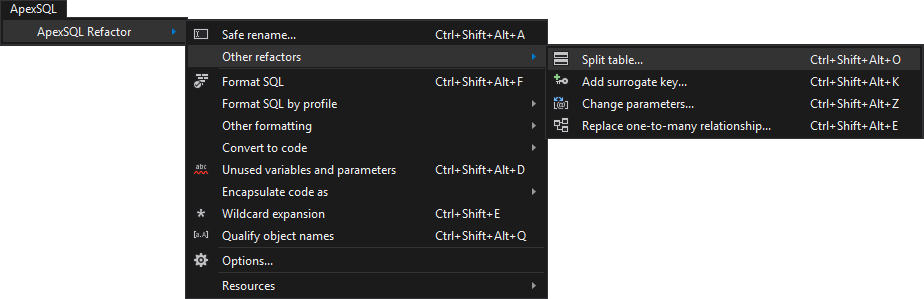
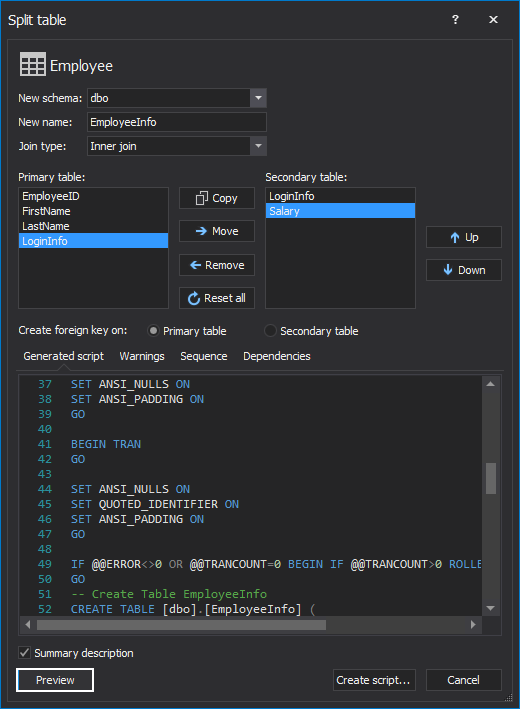
Using ApexSQL Refactor an SSMS and VS refactoring add-in with database refactoring features a table can be split by using the Split table feature. Choose a table from the Object Explorer or Server Explorer panel and from the ApexSQL Refactor main menu, under the Other refactors sub-menu select the Split table command:
The Employee table will be used again.
In the Split table window, a name for a new table that will be created needs to be entered. Let’s name it EmployeeInfo like in the previous example.
Also, it needs to be specified whether a foreign key needs to be created on a primary or on a secondary table. In this example, it determines that this table split is for one-to-one relation, and the foreign key will be set up on the primary table.
The columns that should be on the other partition needs to be moved. One column needs to be copied from the primary table to keep the referential integrity of partitioned tables. The LoginInfo column will be copied for referential integrity and the Salary column is moved.
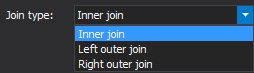
ApexSQL Refactor offers a choice to choose the type of the JOIN statement. As previously mentioned, this is needed if there are queries that retrieve data from all columns which will now be partitioned in two tables:
When the partitioning is set up, click on the Preview button to see the created script:
The Warnings section will inform of any potential issues due to splitting a table:
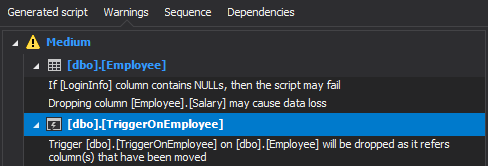
All dependencies will be listed in the Dependencies section, which in this case is the EmployeeView view that retrieves all columns from the table:

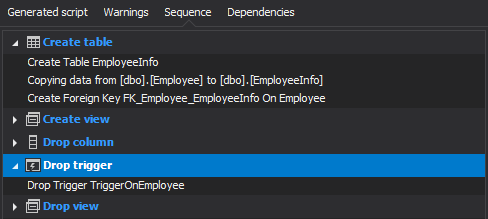
The Sequence section will give the exact steps in the process of splitting a table which will show the refactoring actions in order in which they occur:
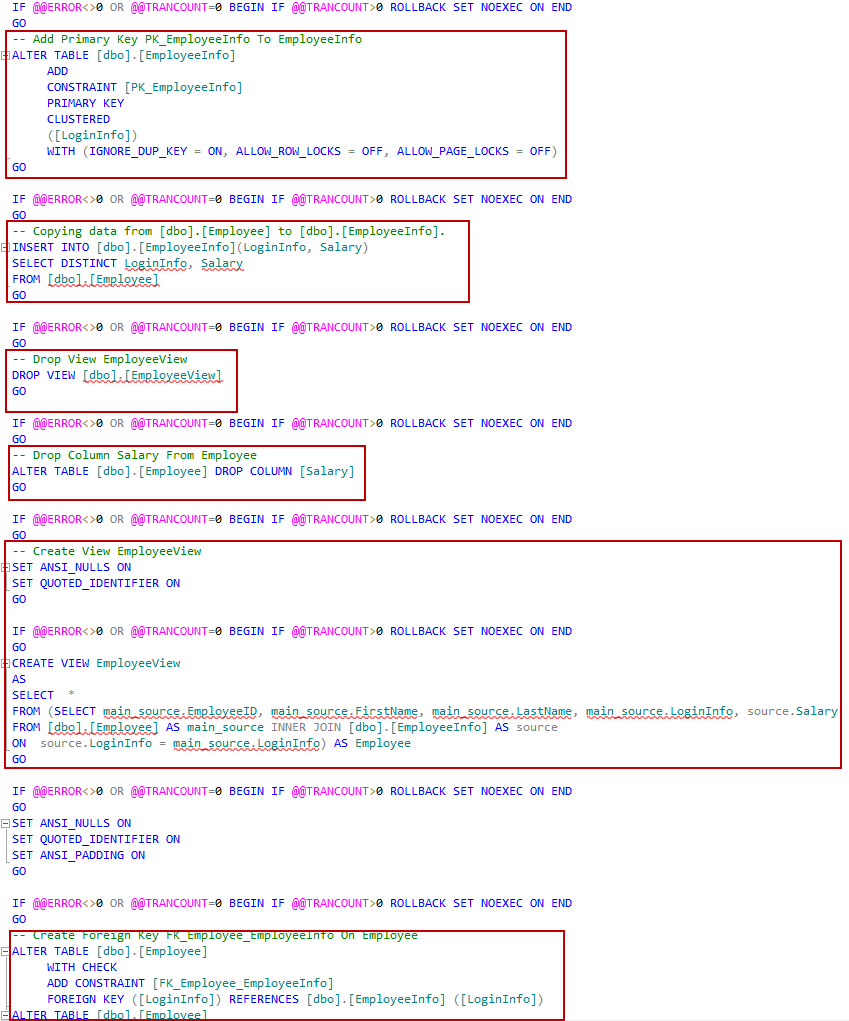
To see and edit the generated script in the SSMS query window click the Create script button. It can be seen that a script in the query window contains all the steps needed to automatically split a table and update all dependencies:
Useful resources:
Partitioning
Vertical Partitioning as the way to reduce IO
Top 10 steps to optimize data access in SQL Server: Part V (Optimize database files and apply partitioning)
March 10, 2014






