



En el caso del desarrollo de bases de datos, de la misma manera que para el desarrollo de aplicaciones, siempre hay tareas como desarrollar una nueva característica, arreglar un error del lanzamiento actual, experimentar con código para mejorar el desempeño, la usabilidad en cualquier forma y más. Por todo esto, es esencial que cualquier cambio que haya sido enviado, pero no inmediatamente, sea segregado a un ambiente aislado, de modo que no afecte al resto del equipo o el código principal. Por ejemplo, cuando se está desarrollando una nueva característica, puede que requiera que muchos cambios se envíen antes de la característica, o incluso una parte funcional de la característica se vuelve útil, de modo que el resto del equipo pueda aplicarla en sus copias locales de la base de datos. Sin tener el aislamiento mientras se desarrolla, el equipo no tendrá la libertad de codificar sin tener que preocuparse acerca de romper el código base existente.
La ramificación es una solución que permite a los desarrolladores trabajar con cambios desde el repositorio en aislamiento, sin tener que preocuparse acerca de afectar el código base principal. Cuando los cambios son verificados, pueden ser unidos en una manera organizada.
¿Qué es ramificación?
Ramificación significa divergir desde la ruta principal de desarrollo y trabajar en aislamiento, sin afectar el código base más grande o afectar a otros desarrolladores. Las ramas son también conocidas como árboles, torrentes o líneas de código. La idea de la ramificación es desarrollar en paralelo. Los proyectos grandes a menudo requieren el involucramiento de muchos roles, como desarrolladores, administradores de builds, ingenieros de Control de Calidad, etc. Tener la habilidad de trabajar en micro ambientes específicos que no afectan al resto del equipo es esencial.
Más tarde, cuando los cambios estén verificados y aprobados, las ramas pueden ser unidas, lo que significa que los cambios desde una rama recién creada serán integrados en otra rama, la cual es típicamente el código base principal.
¿Por qué usar ramas?
La razón para usar ramas es una necesidad de trabajar en aislamiento. Algunos de los casos de uso más comunes son: cuando se está desarrollando una nueva característica, se está corrigiendo errores de un lanzamiento previo o cuando se está experimentando con cambios de la base de datos. Cualquier cambio hecho en tales casos puede romper la base de datos si es parcialmente finalizado, y como tal ser usado por otros desarrolladores. En otras palabras, no importa si un desarrollador está trabajando en alguna nueva funcionalidad (nueva característica o experimentando) o modificando la existente, es esencial que el resto del equipo no sea afectado con cambios, a menos que sean lo suficientemente buenos para ser usados. La ramificación permite a un desarrollador trabajar en aislamiento (usando una rama separada), hasta que los cambios son “suficientemente buenos” para ser usados por el resto del equipo. En este punto, los cambios hechos en una rama separada pueden ser unidos (integrado en la línea principal).
Para propósitos de este artículo, una nueva rama local será usada para la siguiente versión de una base de datos (MyDatabase2.0).
Ramas locales y remotas
Como dice el nombre, las ramas locales están disponibles sólo en una máquina local y son visibles sólo al usuario local. Las ramas remotas están en el repositorio remoto, disponibles para el equipo entero o cualquiera que tenga acceso al repositorio.
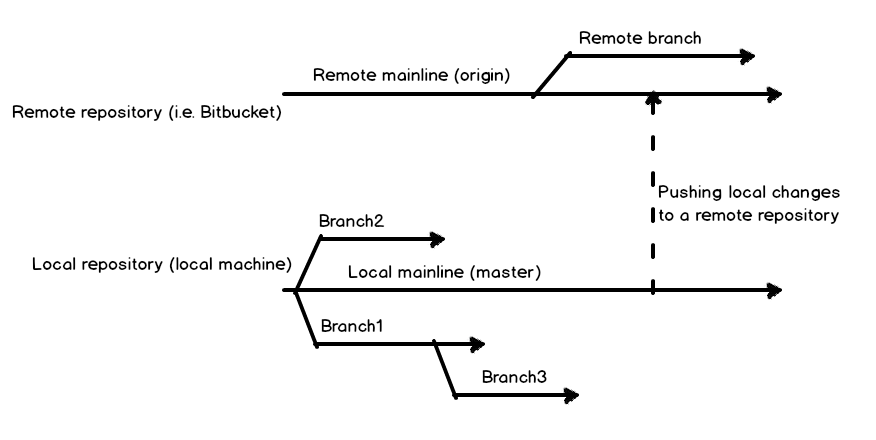
Caso de uso
Para mostrar cómo mantener cambios en la base de datos usando múltiples ramas, establezcamos un caso de uso y algunos básicos.
La base de datos usada en este caso, llamada MyDatabase, está siendo codificada, y todos los scripts son grabados en una carpeta local inicializada como un repositorio Git. Todos los cambios hechos durante el desarrollo son enviados a la línea principal local, y promovidos a la rama master en el repositorio remoto, usando el cliente Git Bash. La versión inicial de la base de datos es lanzada a producción como MyDatabase1.0.
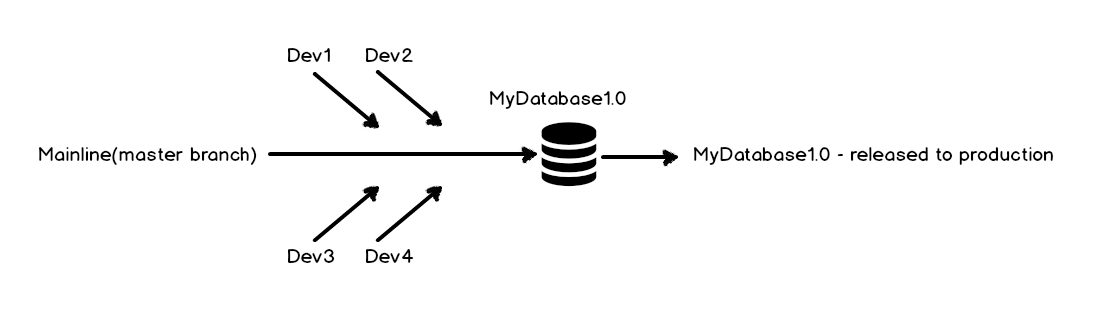
Viendo el repositorio remoto donde los cambios han sido enviados, el resultado siguiente muestra que todos los cambios están en la rama master (línea principal):
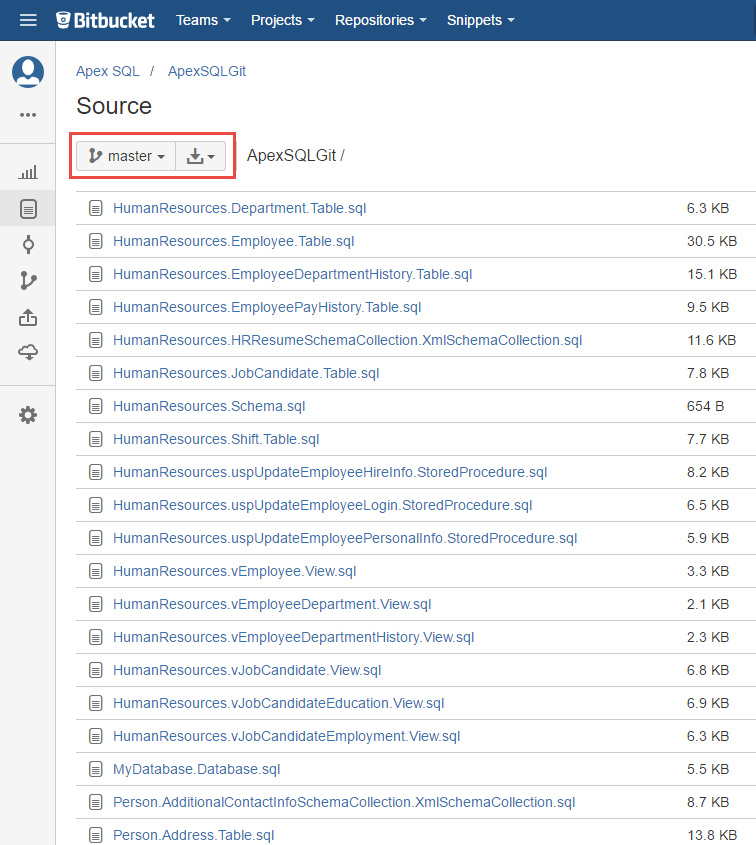
Para el siguiente lanzamiento, hay muchas nuevas características que tienen que ser desarrolladas. Más allá de eso, cualquier error encontrado en MyDatabase1.0 después de que sea lanzada, tiene que ser resuelto desde dentro de la línea de código de MyDatabase1.0, la cual está en este caso en la rama master. Este es el punto donde la ramificación Git entra en escena.
Creando una nueva rama
Para crear una nueva rama, el siguiente comando es ejecutado:
$ git branch MyDatabase2.0
Para verificar que la rama MyDatabse2.0 es creada, corra el siguiente comando, eso debería darle una lista de todas las ramas locales:
$ git branch
Como resultado, lo siguiente aparece:
MyDatabase2.0
* master
Esto significa que la rama MyDatabase sólo es creada, pero la rama master es aún la actual (usada para enviar cambios).
Cambiar entre ramas
Para cambia a otra rama, en este caso, la rama MyDatabase2.0, el siguiente comando es usado:
$ git checkout MyDatabase2.0
La salida confirma que la rama actual es MyDatabase2.0, desde ahora en adelante:
Switched to branch ‘MyDatabase2.0’
Cuando se cambia a la rama, cualquier cambio enviado no afectará a la rama master en ninguna manera. Para mostrar esto, un simple cambio en un objeto es hecho:
ALTER TABLE dbo.Users ADD AddressLine2 NVARCHAR(50);
Y el script SQL es grabado en la carpeta del repositorio local. Después de correr el siguiente comando:
$ git status
El resultado muestra que la tabla SQL ha sido modificada:
On branch MyDatabase2.0
Changes not staged for commit:
(use «git add <file>…» to update what will be committed)
(use «git checkout — <file>…» to discard changes in working directory)
modified: dbo.Users.Table.sql
no changes added to commit (use «git add» and/or «git commit -a»)
Corriendo el comando git commit, el cambio de arriba (una nueva columna añadida a la tabla dbo.Users) será enviado a la rama MyDatabase2.0.
Para verificar que la rama master no es afectada, debería haber algunas diferencias cuando se compara la rama master con la rama MyDatabase2.0. Específicamente, la diferencia debería ser un solo cambio recientemente hecho en un objeto que es enviado a la rama MyDatabase2.0.
Para compara entre ramas, el siguiente comando es usado:
$ git difftool master MyDatabase2.0
Como resultado, lo siguiente es mostrado:
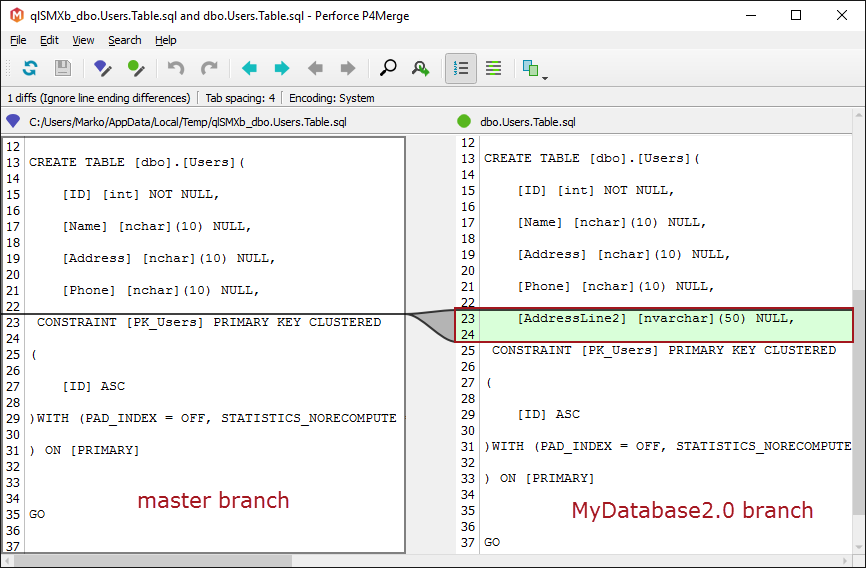
La imagen de arriba representa la comparación resultante entre la rama master (en el lado izquierdo) y la rama MyDatabase2.0 (en el lado derecho). Dado que el cambio mencionado arriba (una nueva columna añadida: AddressLine2) es enviado a la rama MyDatabase2.0, no existirá en la rama master.
Además, cualquier cosa enviada a la rama actual (en este caso, la rama MyDatabase2.0) no afectará ninguna otra rama. Por lo tanto, un desarrollador puede trabajar en una nueva versión de la base de datos sin afectar la línea principal local o la versión actual de la base de datos (MyDatabse1.0).
Trabajar con ramas remotas no difiere, en ninguna manera, cuando se compara a trabajar con ramas locales. El repositorio remoto, junto con las ramas remotas, están disponibles para el equipo entero, así que, cualquier cambio en la estructura de ramas debería ser una decisión de equipo. Dado que el concepto de enviar cambios a una rama específica es similar cuando se trabaja con ramas locales y remotas, lo siguiente será una explicación de enviar cambios a una rama remota, directamente desde SQL Server Management Studio, usando ApexSQL Source Control.
La característica de ramificación de ApexSQL Source Control
ApexSQL Source Control es un complemento que se integra directamente en SQL Server Management Studio (SMSS), y permite el control de versiones de los objetos de la base de datos SQL. En el proceso de enlazar una base de datos, al usuario se le ofrecerá elegir una rama a la cual enlazar la base de datos:
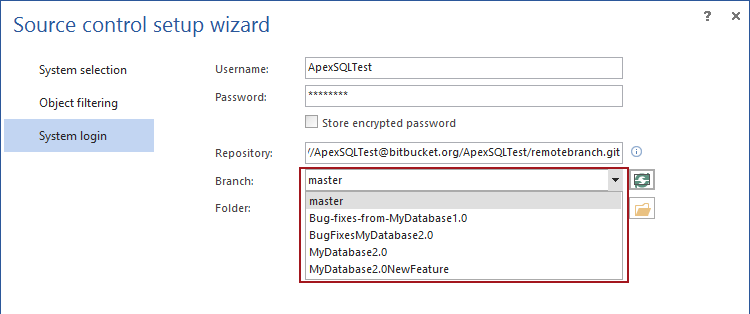
La rama seleccionada puede ser verificada/cambiada después, en la pestaña Action center después es inicializada, ya que la misma lista desplegable estará disponible, mostrando la rama activa (la rama donde los cambios seleccionados serán enviados):

Para compara el estado actual en una base de datos con cualquier rama disponible, una rama necesita ser seleccionada desde la lista desplegable. El complemento realizará la comparación y presentará los resultados en la pestaña Action center.
Enviemos los cambios a una rama separada y confirmemos que tales cambios no afectan a la rama master usando ApexSQL Source Control.
En un punto inicial, todos los cambios de la base de datos han sido sincronizados con la rama master, de modo que la pestaña Action center ninguna diferencia:
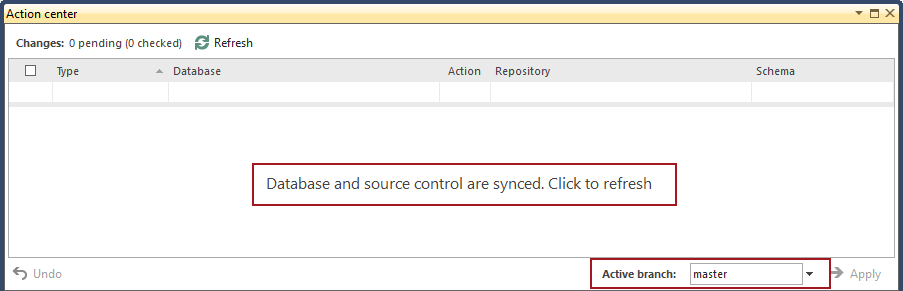
Después de ejecutar el siguiente script contra la base de datos:
ALTER TABLE dbo.Users ADD AddressLine2 NVARCHAR(50);
Y actualizar la pestaña Action center y cambiar a la rama MyDatabase2.0, lo siguiente será mostrado:
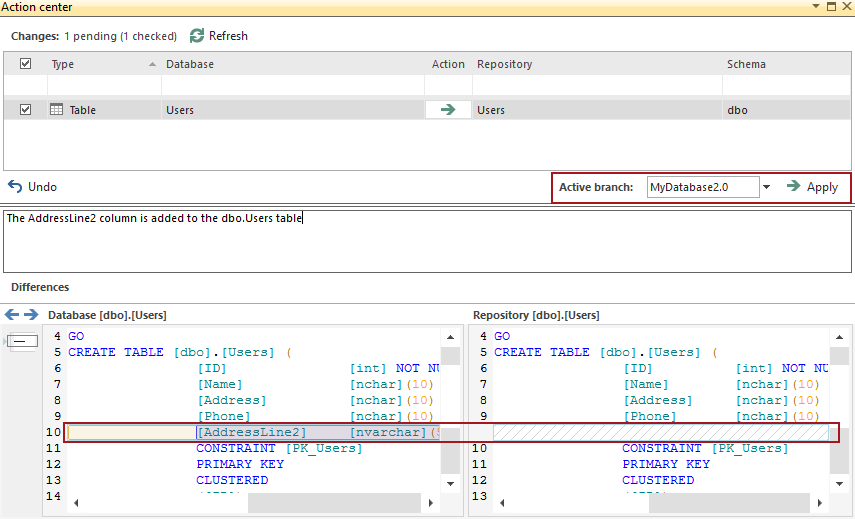
Esto muestra que la base de datos y la rama master ahora son diferentes en que la base de datos refleja el cambio, pero, ya que no ha sido enviado a la rama Master, esta no puede mostrar el cambio.
Para este cambio, no lo deseamos en la rama master, pero, en lugar de eso, la lista desplegable Active branch es cambiada a MyDatabase2.0.
Después de enviar a MyDatabase2.0, la pestaña Action center muestra lo siguiente:

El cambio previamente mostrado es enviado a la rama MyDatabase2.0, y la pestaña Action center muestra que no hay diferencia entre la base de datos y la rama MyDatabase2.0.
Para verificar que los cambios desde la rama MyDatabase2.0 no son hechos a la rama master, cuando estemos trabajando con ApexSQL Source Control, simplemente elegiremos la rama master desde la lista desplegable Action branch. La lista desplegable Active branch es un equivalente al comando git checkout, el cual es usado para establecer cualquier rama para que sea la actual, donde los cambios serán enviados.
Cuando se cambia desde la rama MyDatabase2.0 a la rama master (después de que un cambio es enviado a la rama MyDatabase2.0), el resultado en la pestaña Action center es como sigue:
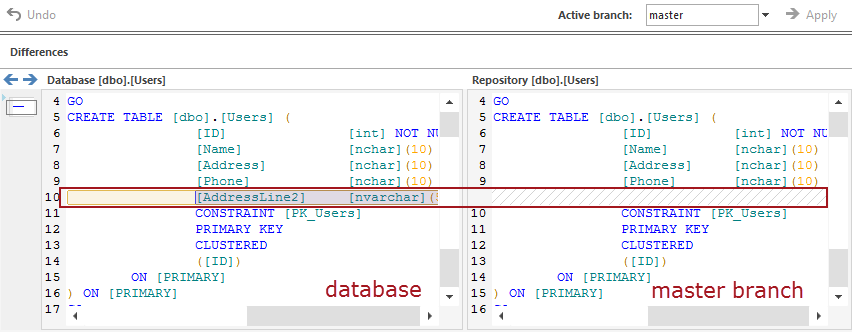
La imagen de arriba muestra el resultado de la comparación entre la rama master (en el lado derecho) y la base de datos (en la parte izquierda). El resultado muestra que la columna añadida a la base de datos (AddressLine2) y enviada previamente a la rama MyDatabase2.0 no existe en la rama master, como se muestra en el lado derecho.
Esto confirma que el cambio enviado a la rama MyDatabase2.0 no afectó a la rama master en ninguna manera. Por lo tanto, todos los cambios que son enviado a la rama MyDatabase2.0 no serán enviados (y no afectarán) a ninguna otra rama (incluyendo la rama master). Así que, un desarrollador puede trabajar en una rama separada hasta que los cambios sean suficientemente buenos para ser usados por el resto del equipo.
Enlaces útiles:
julio 7, 2017






