



Introducción
Cuando se trabaja con bases de datos, la disponibilidad y el desempeño son de suprema importancia. El desempeño de la base de datos está basado en múltiples factores, entre los cuales se destaca poder procesar consultas rápidamente. Esto puede ser facilitado usando índices. Los índices son como los índices de un libro, proveen accesos directos a donde la información está localizada. De otra manera, usted tendría que comenzar a leer el libro desde el inicuo hasta encontrar la información necesitada. Es lo mismo con las bases de datos, si no fuera por los índices, por cada consulta habría la necesidad de un escaneo de la tabla entera.
Viendo los índices, cuando se insertan nuevos datos, las páginas de índices se llenan gradualmente. El Factor de relleno entra en escena aquí, ya que su valor, en términos de porcentaje, determina cuánto se le permitirá a cada página llenarse. Establecer el factor de relleno a 0 o 100% (efectivamente lo mismo) significa que, una vez llenada, no hay más espacio en la página para datos adicionales. Cuando otra pieza de datos necesita ser insertada en una página, la cual está completamente llena, un evento llamado ’page split’ es usado para ajustarse a los nuevos datos. Lo que una división de página hace es dividir la página llena existente en dos nuevas páginas que están llenas a la mitad. La nueva pieza de datos va a ser insertada en su lugar lógico. De todas maneras, SQL Server ahora tiene más páginas para leer, lo cual tiene un impacto en el desempeño y un uso más alto de memoria, CPU y ancho de banda IO.
La fragmentación de índices en una base de datos SQL Server ocurre en dos formas, fragmentación interna y externa. La fragmentación interna significa que el índice es más grande de lo que realmente necesita ser. Esto es causado por operaciones que dejan páginas sin llenar, y los resultados en registros siendo grabados en nuevas páginas en lugar de ser grabados en espacios vacíos en las páginas existentes, llevando a un índice más grande y un desempeño más lento, ya que el servidor necesita leer más páginas.
La fragmentación externa en una base de datos SQL Server significa que el orden lógico en un índice no coincide con el orden físico en el disco. Cuando las páginas están dispersadas en el disco, toma tiempo para que las cabezas de los dispositivos magnéticos salten de una página a otra, lo cual disminuye el desempeño y la longevidad general del hardware. En algunos casos, las lecturas al azar en un dispositivo magnético pueden ser hasta 100 veces más lentas que las lecturas secuenciales.
Cuando se lidia con índices fragmentados, hay dos opciones disponibles para arreglar la fragmentación. Estas son la Reorganización del índice y la Reconstrucción del Índice. Una práctica común es Reorganizar cuando la fragmentación del índice está entre 10-30%, y Reconstruir cuando la fragmentación está encima de 30%. De todas maneras, le concierne al usuario elegir en última instancia el porcentaje al cual correr Reorganizar o Reconstruir.
Hay un par de maneras de arreglar automáticamente la fragmentación del índice de la base de datos en SQL Server:
- Reorganizar/Reconstruir índices de bases de datos SQL Server usando Planes de SQL Server Maintenance
-
Reorganizar/Reconstruir índices de bases de datos SQL usando ApexSQL Defrag
Reorganizar/Reconstruir índices de bases de datos usando Planes de SQL Server Maintenance
Microsoft SQL Server Management Studio es un ambiente para Microsoft SQL Server. Para propósitos de este artículo, tendremos una base de datos AdventureWorks en nuestro SQL Server.
-
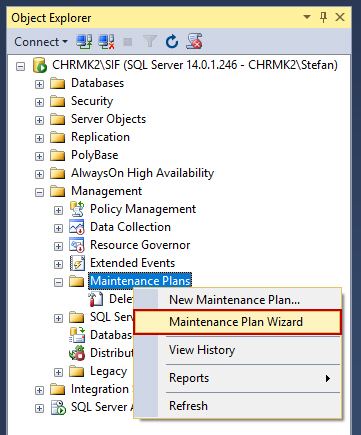
Después de conectarse al servidor, expándalo y después, la carpeta Management. Haga clic en Maintenance Plans y seleccione Maintenance Plan Wizard.
-
Cuando se abra la nueva ventana, haga clic en Next.
-
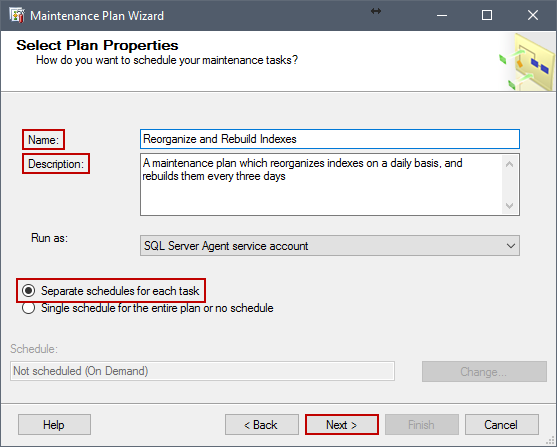
En la siguiente ventana, ingrese un nombre descriptivo y opcionalmente ingrese una descripción para el plan de mantenimiento. Adicionalmente, seleccione Separate schedules for each task, ya que en este escenario deseamos reorganizar los índices diariamente y reconstruirlos cada tres días, y después haga clic en Next.
-
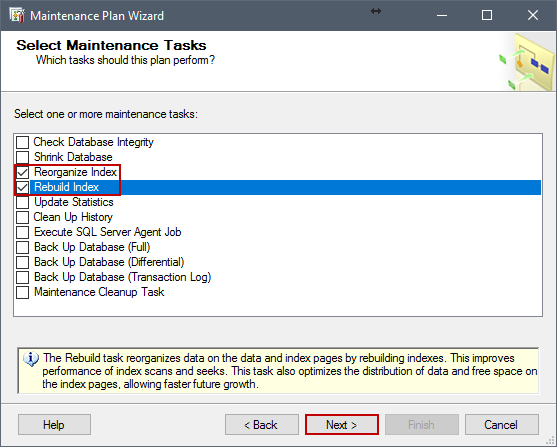
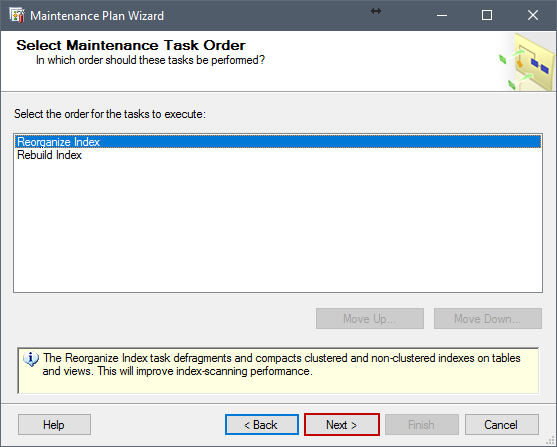
En la siguiente ventana, seleccione Reorganize Index y Rebuild Index y haga clic en Next.
-
En la siguiente ventana, simplemente haga clic en Next.
-
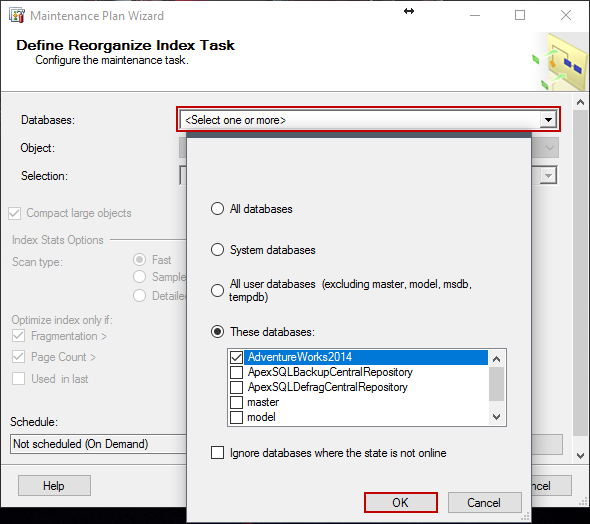
En Define Reorganize Index Task, debajo de Databases en el menú desplegable, podemos seleccionar las bases de datos sobre las que deseamos trabajar.
-
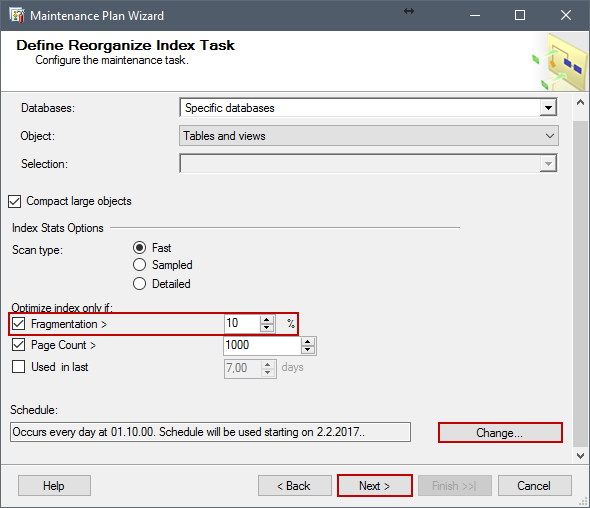
Después de seleccionar la base de datos sobre la que deseamos trabajar, podemos seleccionar Scan type y seleccionar las condiciones cuando el índice debería ser reorganizado. Podemos seleccionar el porcentaje de fragmentación, el conteo de páginas y si ha sido usado en los últimos días; después de eso, haga clic en Change… para configurar un programa cuándo correr la tarea Reorganize Index Task.
-
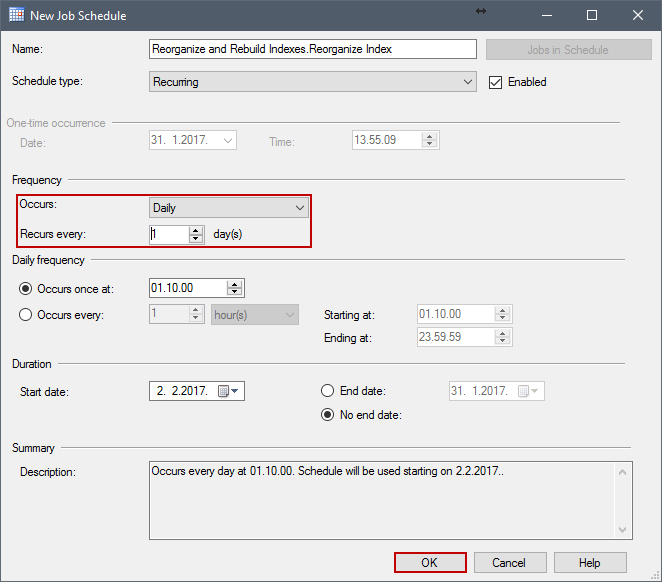
En New Job Schedule definimos cuándo correr la tarea Reorganize Index. Después de definir el programa, haga clic en OK y seleccione Next para avanzar a la siguiente ventana.
-
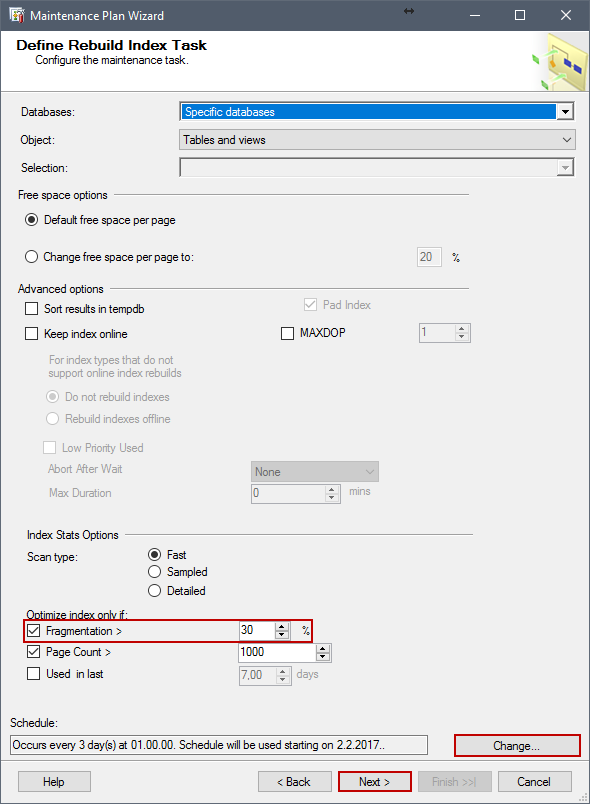
En la ventana Define Rebuild Index Task, definimos Free space options (opciones de espacio libre), el cual es el Factor de Relleno. Podemos dejarlo en Default free space per page, lo cual deja el Factor de Relleno para cada Índice en lo mismo que estaba antes, o podemos elegir Change free space per page to:, para elegir un porcentaje que cambia todos los índices al mismo Factor de Relleno, lo cual no es recomendado en bases de datos grandes con diferentes índices, algunos de ellos más o menos actualizados. Debajo de Advanced options, podemos elegir Sort results in tempdb (ordenar los resultados en tempdb), Keep index online (mantener el índice en línea) si se soporta, definir el máximo grado de paralelismo, y definir Index Stats Options (opciones de estadísticas de índices) como en la ventana previa.
-
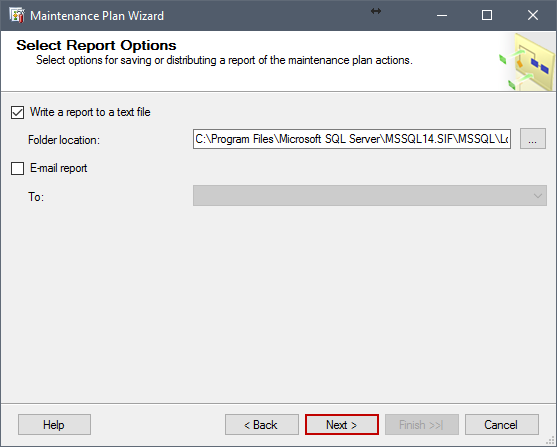
En la siguiente ventana, podemos elegir escribir un archivo de reporte y grabarlo en la localización predefinida o navegar por nuestra cuenta o enviar un reporte en correo electrónico. Después de seleccionar eso, haga clic en Next.
-
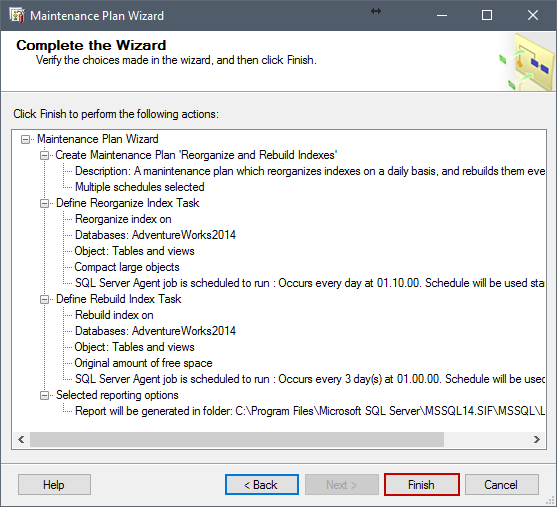
En la siguiente ventana, revisamos las tareas creadas y verificamos que todo esté correcto. Si hay cambios adicionales a ser hecho, haga clic en Back y revise los cambios. Si todo está correcto, haga clic en Finish.
-
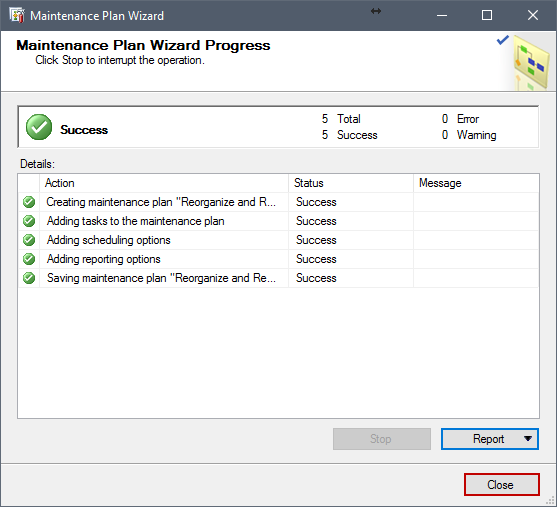
En esta ventana, las tareas son creadas y se nos muestra si todo marchó sin errores. Después de eso, hacemos clic en Close, y nuestro Plan de Mantenimiento es creado.
Los Planes de Mantenimiento son una buena opción para configurar y olvidar. De todas maneras, a menos que se elija específicamente los índices a correr en el Plan, este correrá contra todos los índices en la base de datos seleccionada que están entre 10% y 30% fragmentados, reorganizándolos o reconstruyéndolos respectivamente, y la interfaz para elegirlos podría ser más amigable.
Reorganizar/Reconstruir índices de bases de datos SQL Server usando ApexSQL Defrag
ApexSQL Defrag es una herramienta de terceros hecha específicamente para arreglar automáticamente la fragmentación de índices en bases de datos SQL Server. Con ella, podemos analizar la fragmentación del índice, reconstruir y reorganizar los índices fragmentados, crear y administrar políticas personalizadas y programas para trabajos de desfragmentación, monitorear la fragmentación de índices en múltiples servidores, crear reportes HTML y exportar todas las actividades a archivos CSV o XML.
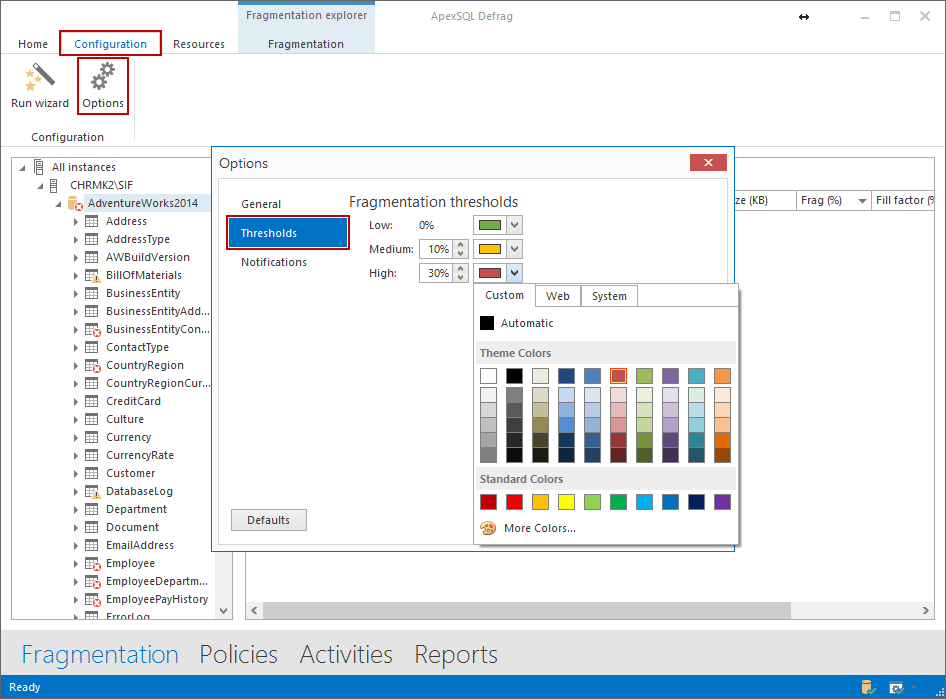
Para tener la habilidad de detectar la fragmentación de índices de bases de datos SQL Server, primero es requerido configurar las opciones de umbral a nuestras necesidades.
Podemos hacer eso yendo a Configuration en la barra superior y seleccionando Options en la cinta. En la ventana Options, después de hacer clic en Thresholds, podemos seleccionar manualmente el porcentaje de fragmentación y los colores apropiados desde el seleccionador de colores.
Crear un programa en ApexSQL Defrag para detectar la fragmentación de índices en SQL Server y reorganizar/reconstruir índices fragmentados, puede ser hecho en un par de pasos simples.
-
El primer paso es opcional y puede ser saltado, pero es recomendado realizarlo para tener una vista general de la cantidad de fragmentación en la base de datos seleccionada.
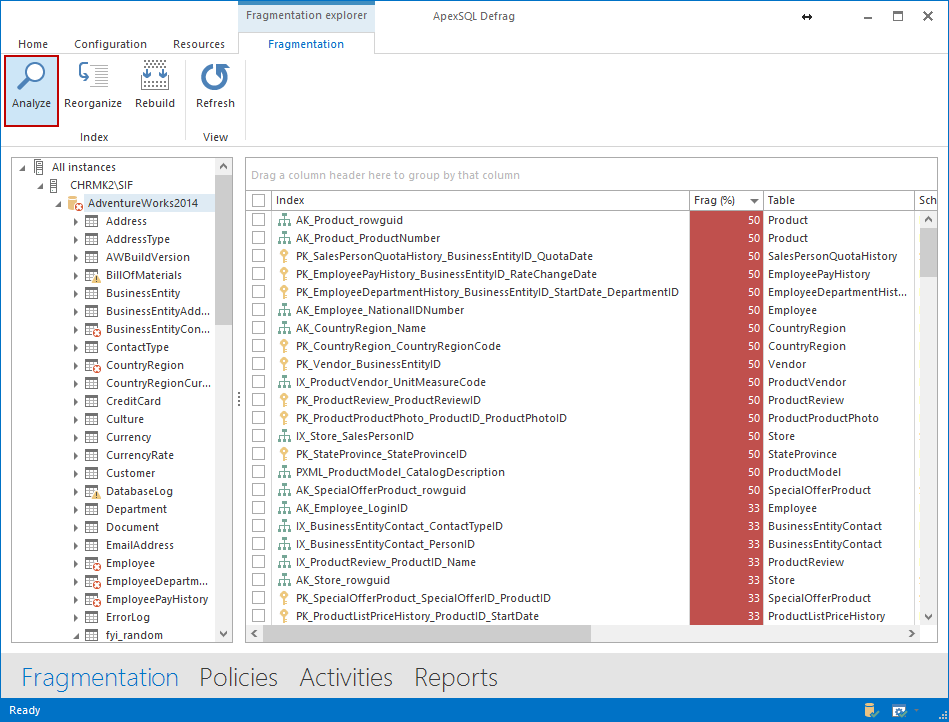
Después de seleccionar la base de datos, haga clic en Analyze. En el lado derecho, usted tendrá una lista de todos los índices con sus respectivos detalles. Todos los nombres de las columnas se pueden reordenar, y tenemos aquí el porcentaje de fragmentación listado justo después del nombre del índice.
-
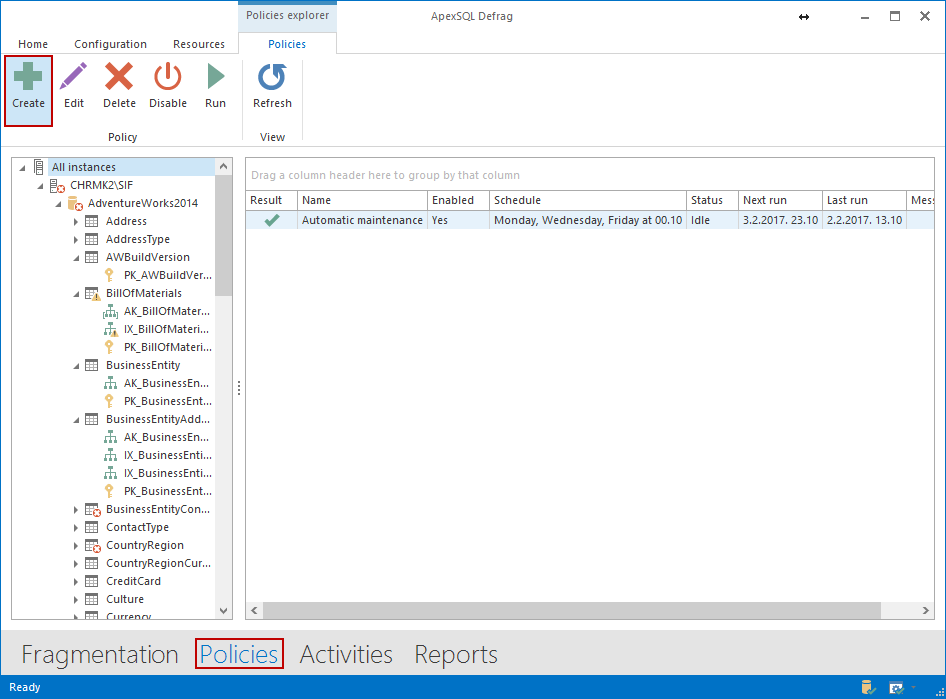
Después de analizar, en la barra inferior haga clic en Policies y después en Create.
-
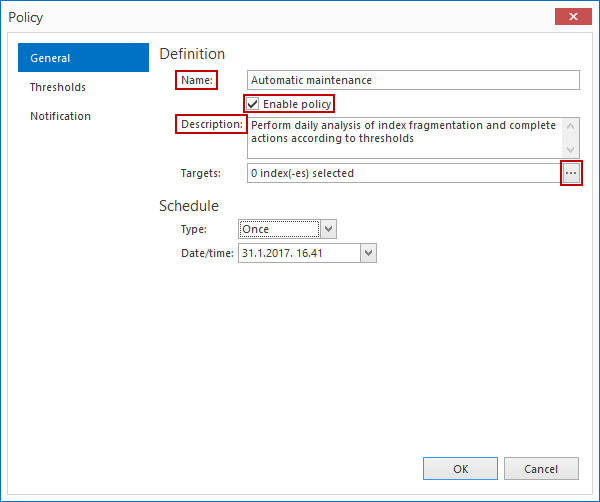
En la nueva ventana, ingrese un nombre apropiado y, opcionalmente, una descripción para la nueva política y asegúrese de que la política está habilitada seleccionando la casilla a la izquierda de Enable policy. Después de eso, presione el botón a la derecha de Targets para abrir una nueva ventana para seleccionar los índices sobre los cuales deseamos correr la política.
-
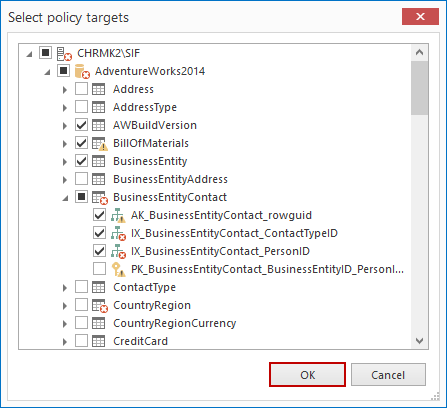
En la ventana Select Policy Targets, después de expandir la vista de árbol, podemos seleccionar contra qué índices deseamos correr la política. Podemos seleccionar la base de datos completa, todos los índices enlazados a una cierta tabla, o índices individuales. Después de la nuestra selección, haga clic en OK para continuar.
-
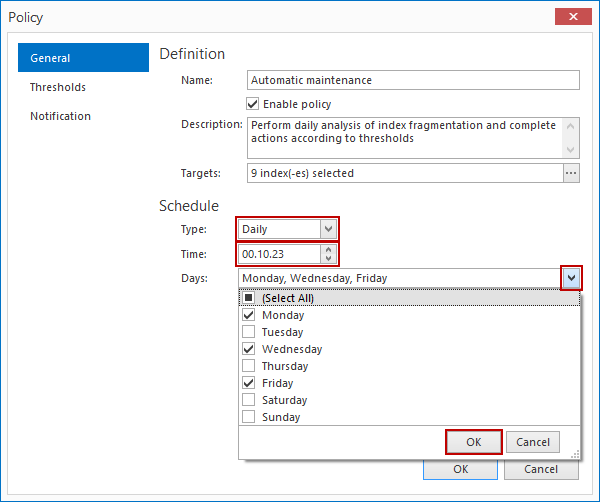
Debajo de Schedule, para Type seleccionamos Daily, especifique el tiempo (Time) cuando correrá la política, y en el menú desplegable para días (Days), podemos seleccionar en qué días correrá la política.
-
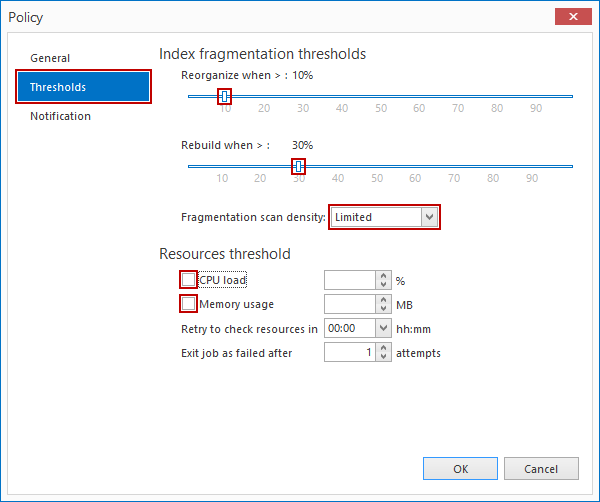
Después de hacer clic en Thresholds en la pestaña de navegación en la izquierda, somos presentados con opciones para seleccionar cuándo reorganizar índices, cuándo reconstruir y la densidad de escaneo de la fragmentación. Debajo de Resources threshold, podemos elegir revisar los recursos disponibles necesarios para ejecutar la política, el reintento opcional y opciones de salida en caso de falla.
-
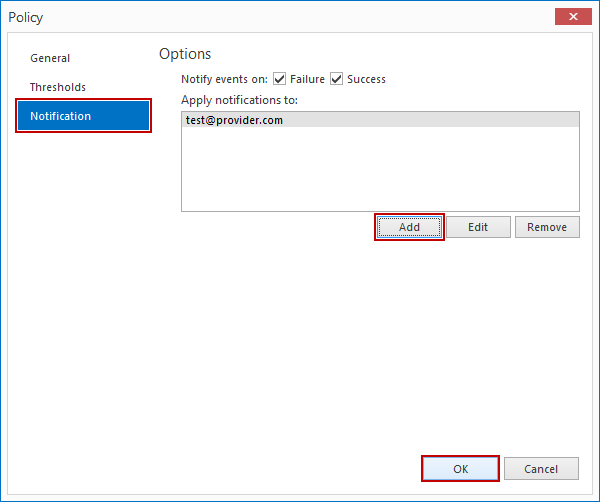
En el tercer panel seleccionado desde la pestaña Navigation a la izquierda, Notification, podemos seleccionar si deseamos ser notificados por correo electrónico si el trabajo es exitoso o no. Podemos añadir direcciones de correo electrónico haciendo clic en el botón Add. Después de terminar la configuración para nuestro trabajo, haga clic en OK para crearlo.
Nota: Para añadir una dirección de correo electrónico, usted tiene primero que configurar una cuenta de correo electrónico en la pestaña Configuration de la aplicación.
-
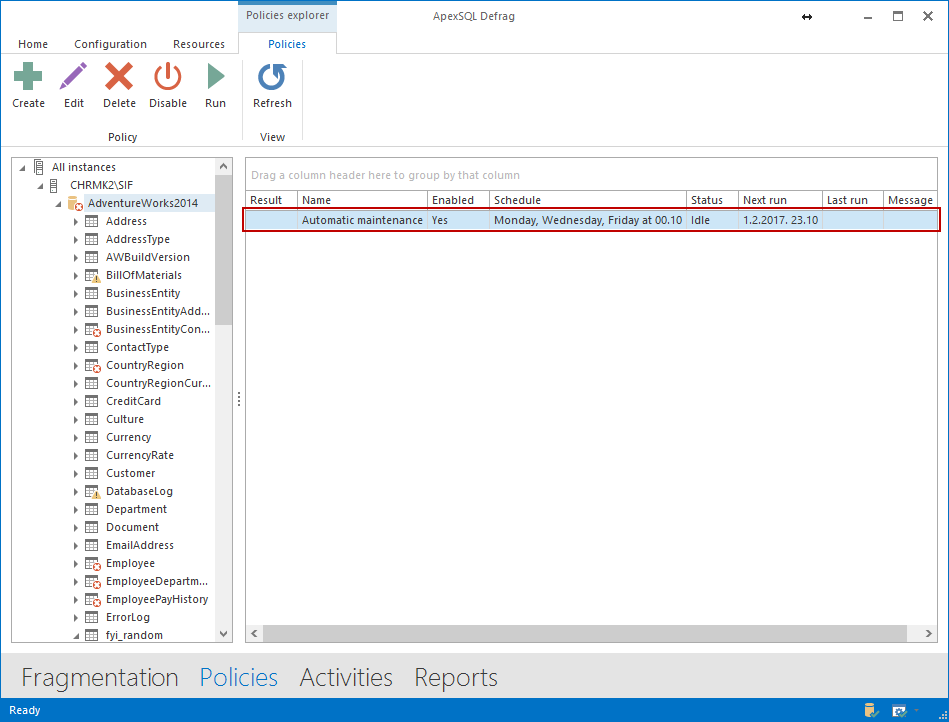
Después de crear el trabajo, podemos verlos en la pestaña Policies de la barra inferior.
-
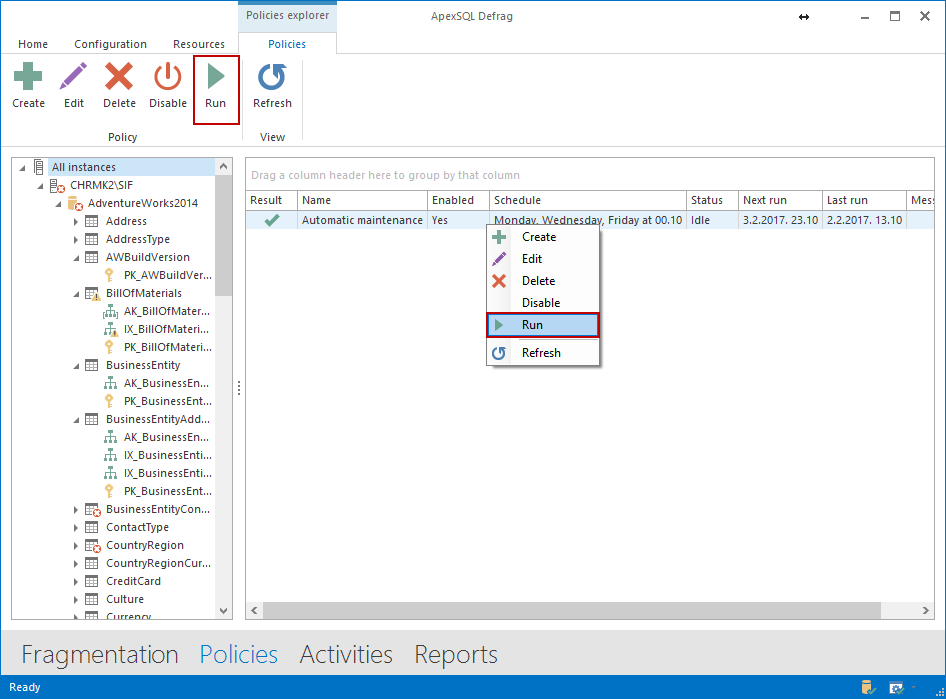
La política correrá ahora automáticamente en el tiempo programado. De todas maneras, si deseamos correrlo en demanda, podemos hacerlo manualmente seleccionado la política que deseamos correr y haciendo clic en la política y seleccionado Run, o presionando el botón Run en la cinta de arriba.
-
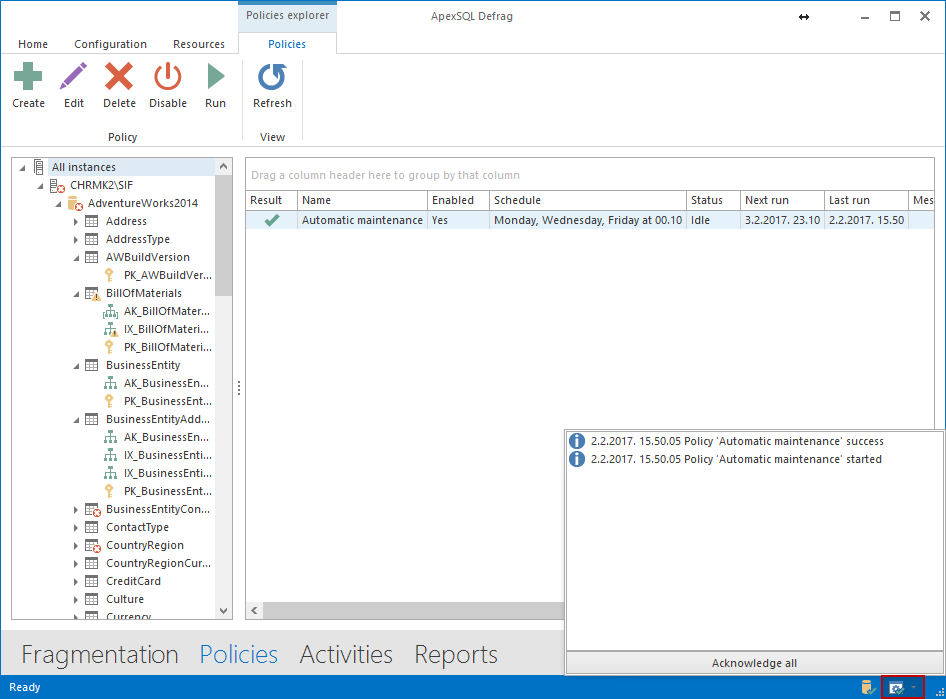
Después de que la política termina de correr, ApexSQL Defrag le notificará que ha terminado. Usted puede ver las notificaciones y ver si la política fue exitosa o no haciendo clic en el ícono de Agente.
-
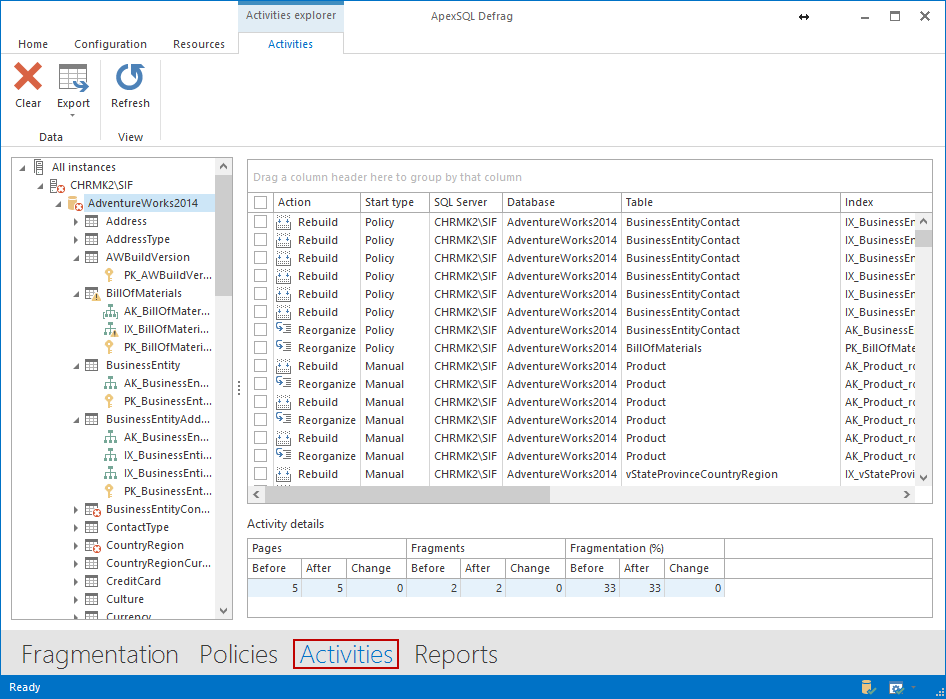
Alternativamente, usted puede ver todas las actividades seleccionando Activities en la barra inferior.
Enlaces relacionados:
- Por qué, cuándo y cómo reconstruir y reorganizar índices de SQL Server
- Reorganizar y Reconstruir Índices
- Fragmentación de Índices de SQL Server, Tipos y Soluciones.
julio 25, 2017






