



Es de conocimiento general que ejecutar cambios directamente a una base de datos en producción, sin efectuar pruebas en profundidad primero, debería evitarse.
Si hay suficientes recursos en el ambiente, habría al menos una instancia SQL Server de pruebas y otra de producción. De todos modos, eso introduce otro desafío. Cuando todo está configurado en la prueba y corre sin problemas y como se esperaba, ¿cómo puede ser aplicado fácilmente a la instancia de producción?
Sincronizar muchos objetos puede ser hecho manualmente, pero aplicar cambios múltiples y complejos a una base de datos en línea y con muchas transacciones es algo que puede iniciar una avalancha de problemas, si no se prueba y ejecuta apropiadamente.
¿Qué hacer si cambios incorrectos fueron aplicados a la base de datos de producción, o si algo había ido mal y terminó arruinando la base de datos de producción y los esquemas de objetos incorrectos en la base de datos de pruebas? ¿Cómo comparar esquemas SQL, y más importante, cómo sincronizarlos de manera segura?
Para comparar y sincronizar en cualquiera de los escenarios descritos anteriormente, aquí está o que se debe hacer:
- Compare los objetos de base de datos en las bases de datos de producción y de pruebas, usando un script SQL como el siguiente:
SELECT (SELECT TOP 1 name FROM TestDB2.sys.schemas WHERE schema_id = D1O.schema_id) AS Schema_Name, D1O.name AS Object_Name FROM TestDB2.sys.syscomments D1C INNER JOIN TestDB2.sys.objects D1O ON D1O.object_id = D1C.id INNER JOIN TestDB.sys.objects D2O ON D1O.name = D2O.name INNER JOIN TestDB.sys.syscomments D2C ON D2O.object_id = D2C.id WHERE D1C.text <> D2C.text;
Hay varios scripts SQL con diferentes enfoques que puede ser usados para comparar esquemas de objetos de bases de datos. Lo que todos ellos tienen en común es que usan objetos de sistema.
La desventaja de scripts SQL como este es que no comparan todos los tipos de objetos, el script trata la definición de objetos sólo como texto y compara sólo objetos con exactamente los mismos nombres. Así que no puede ser usado para comparar las tablas Customers y tblCustomers, por ejemplo. También, la estructura de objetos de sistema tiene que ser bien conocida.
- Una vez que los diferentes objetos fueron encontrados, sincronícelos. Los escenarios más fáciles son usar un script ALTER para el objeto, o eliminar el objeto y recrearlo usando el script de objeto DDL. Estos métodos son aplicables sólo si no hay dependencias.
Para tablas, todos los registros tienen que ser almacenados primero, luego elimine y recree una tabla usando el script generado:-
Abra SQL Server Management Studio
-
En Object Explorer, expanda Databases
-
Haga clic derecho en una base de datos, abra Tasks -> Generate Scripts
-
En la pestaña Choose Objects, seleccione los objetos a codificar
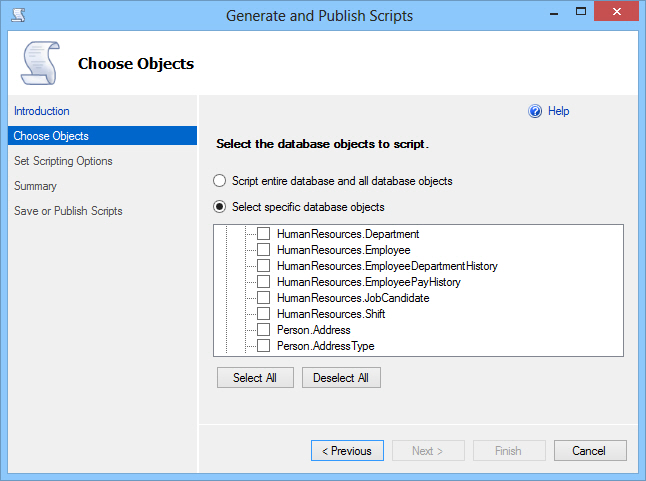
-
En la pestaña Set Scripting Options, haga clic en el botón Advanced y asegúrese de que la opción Types of data to script está configurada a sólo Esquema:
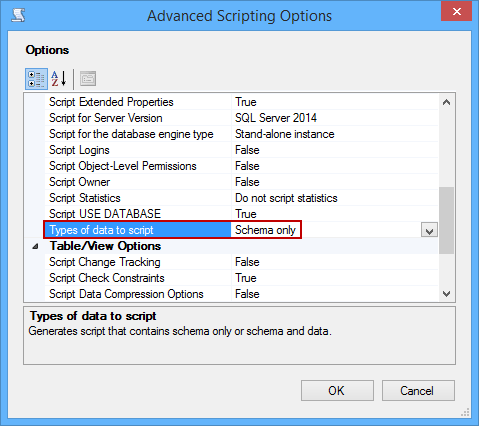
-
Aparte de las desventajas descritas, el método de sincronización manual no es recomendado ya que:
- No maneja dependencias de objetos. Las dependencias son fácilmente pasadas por alto, los objetos dependientes no son codificados, SQL no es ejecutado en el orden correcto. Cuando SQL es ejecutado sin recrear todos los objetos padres primero, SQL fallará.
- Consume tiempo – encontrar todos los objetos diferentes y crear el SQL de sincronización para ellos toma mucho tiempo. Si los desarrolladores no documentaron cada uno de los cambios a detalle, esto es casi imposible.
- Proclive a errores – bases de datos enormes con un gran número de objetos no son fáciles de mantener y tampoco o es rastrear todos los cambios manualmente. Tales cambios involucran dependencias complejas las cuales incrementan los problemas que trae la sincronización manual.
En lugar de sincronizar las bases de datos manualmente y arriesgarse a hacer un desastre en la instancia de producción, use la herramienta de comparación de bases de datos SQL ApexSQL Diff.
ApexSQL Diff es una herramienta de sincronización y comparación de bases de datos SQL la cual detecta diferencias entre objetos de bases de datos y los resuelve sin errores. Genera reportes detallados acerca de las diferencias encontradas y puede automatizar el proceso de sincronización entre bases de datos en línea y versionadas, copias de seguridad, instantáneas y carpetas de scripts.
- inicie ApexSQL Diff
-
Haga clic en el botón New en el diálogo Project management:
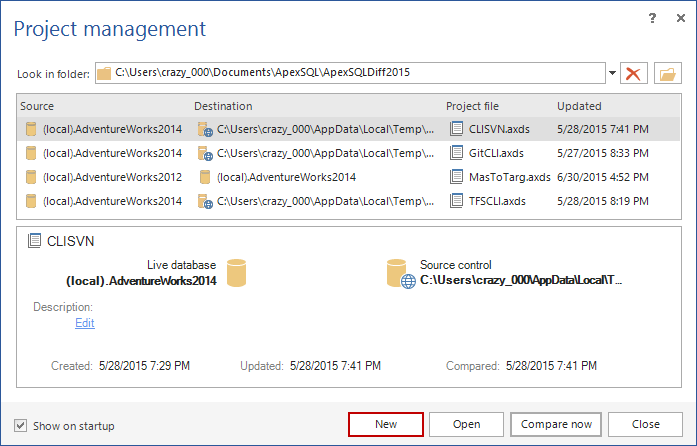
- En el panel Source :
- Seleccione Database en el menú desplegable Type
- Especifique la instancia SQL con la base de datos de pruebas en el menú desplegable Server
- Especifique el método de autenticación para la instancia SQL (y un conjunto válido de credenciales si usted elije la autenticación SQL Server)
- Especifique el nombre de la base de datos de pruebas en el menú desplegable Database
- En el panel Destination :
- Seleccione Database en el menú desplegable Type
- Especifique la instancia SQL con la base de datos de producción en el menú desplegable Server
- Especifique el método de autenticación para la instancia SQL (y un conjunto válido de credenciales si usted elije la autenticación SQL Server)
- Especifique el nombre de la base de datos de producción en el menú desplegable Database
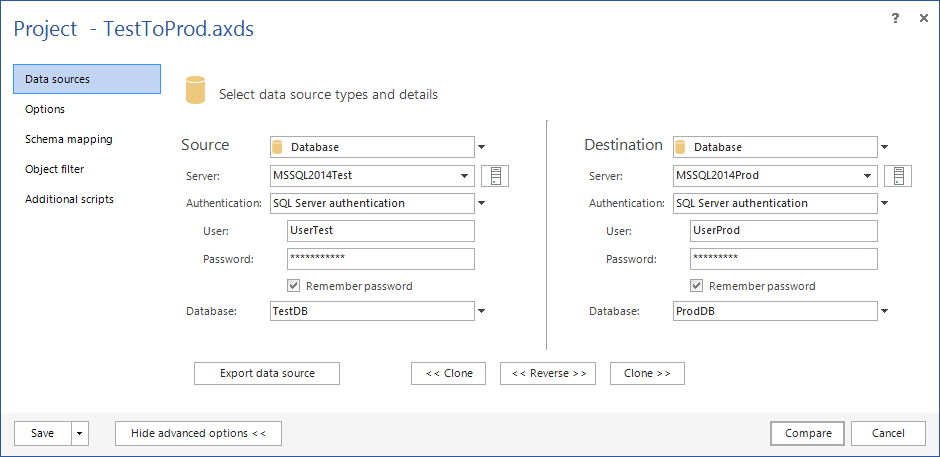
Nota: Seleccione la opción Remember password, dado que la CLI (“Command Line Interface”, Interfaz de Línea de Comandos) no podrá conectarse a la fuente y/o fuente de datos destino, a menos que una contraseña esté especificada como interruptor en la CLI.
- Haga clic en el botón Compare
-
Seleccione los objetos en la Cuadrícula de resultados que será incluida en el proceso de sincronización:
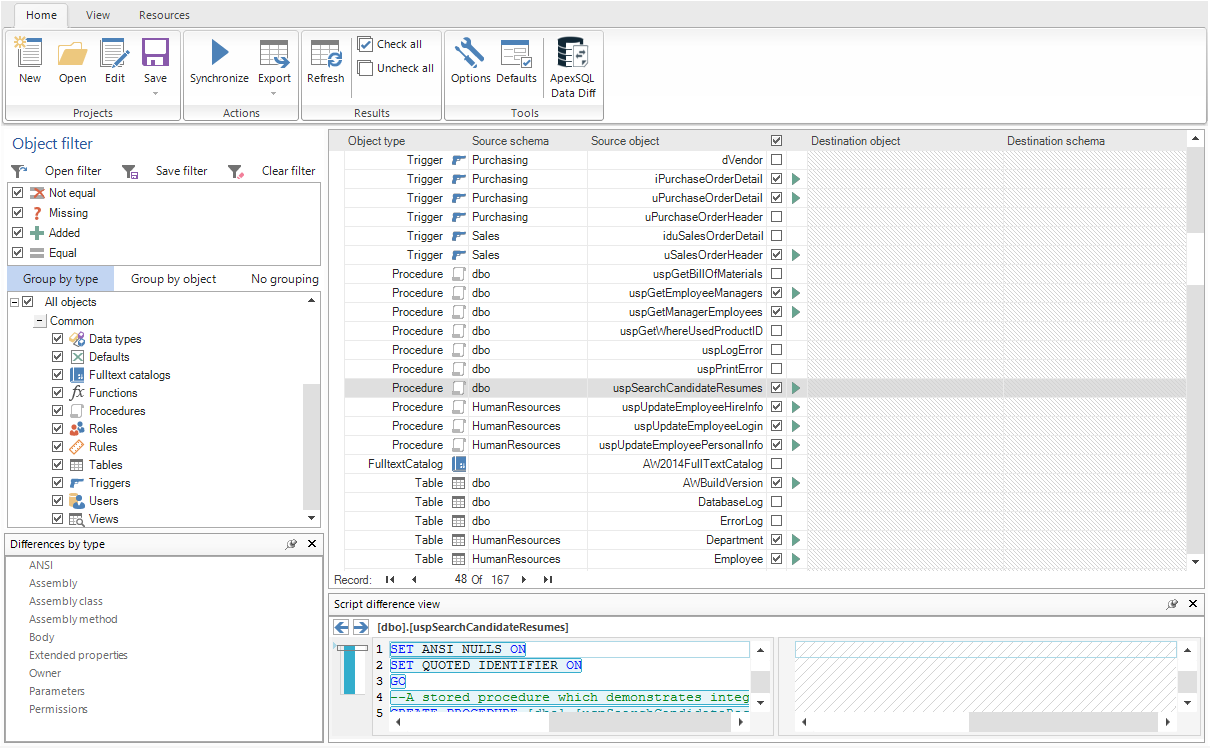
- Haga clic en el botón Save en la pestaña Home, para grabar el proyecto:
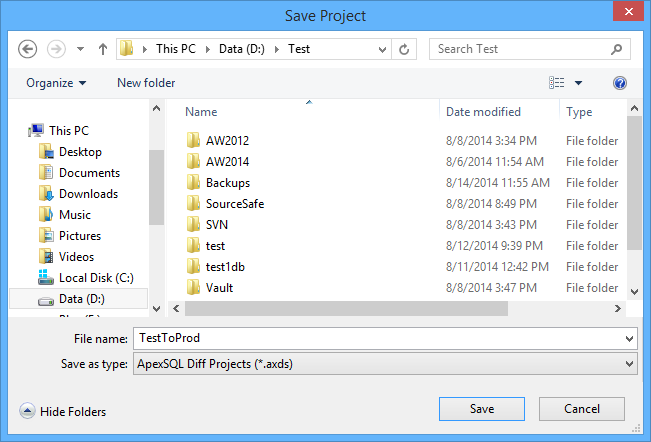
-
Especifique el nombre del proyecto y haga clic en el botón Save
-
Verifique si todo está bien, ya que este proyecto será usado en el futuro
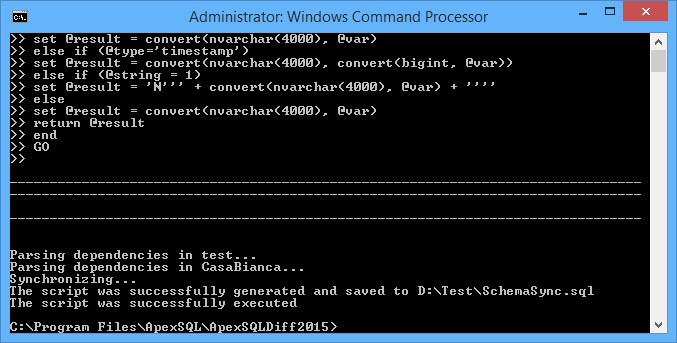
- Para programar la sincronización y comparación de bases de datos SQL cree un archivo batch que ejecutará el proyecto ApexSQL Diff. Grabe el siguiente comando:
"C:\Program Files\ApexSQL\ApexSQLDiff2015\ApexSQLDiff.com" /pf:D:\Test\TestToProd.axds /of:D:\Test\SchemaSync.sql /sync /bu:D:\Test /v /f
En el archivo batch D:\Test\DiffBatchTestToProd.bat.
El archivo creará SchemaSync.sql para sincronizar la base de datos de producción con la de pruebas en la carpeta D:\Test, también creará una copia de seguridad de la base de datos completa de producción llamado ApexSQLDiffBackup_ _YYYY_M_DD_HH_MM_SS_FFF.bak en la carpeta D:\Test folder. Por ejemplo, ApexSQLDiffBackup_ProdDB_2015_7_14_14_16_49_125.bak.
Usted puede probar este comando CLI primero. Después de una sincronización exitosa, el siguiente mensaje aparece:
-
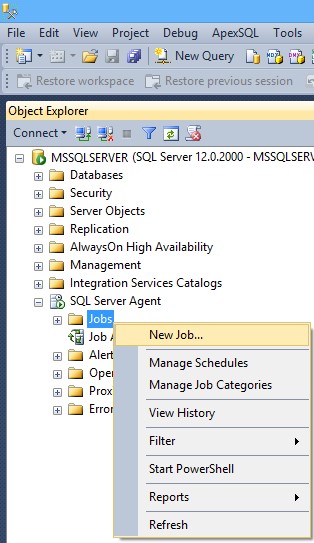
Inicie SQL Server Management Studio
- En Object Explorer expanda SQL Server Agent, haga clic en Jobs, y seleccione New job
-
En la pestaña General, especifique el nombre de la tarea
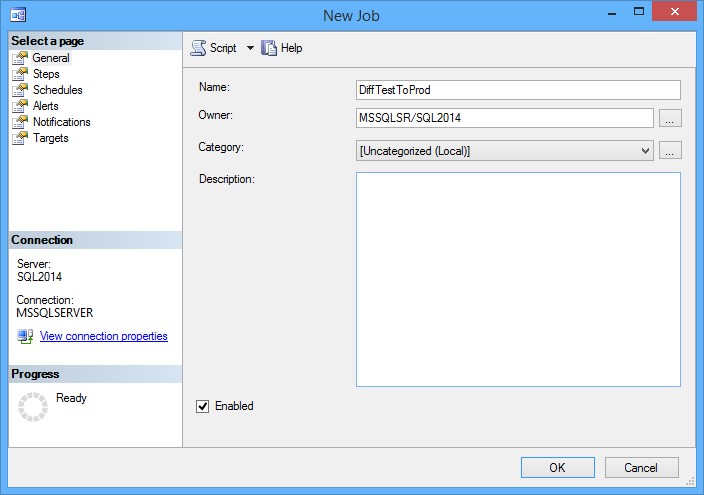
-
En la pestaña Steps, haga clic en el botón New para añadir un nuevo paso en la tarea
-
Especifique un tipo “Operating system (CmdExec)” para la tarea, añada un nombre al paso, haga clic en el botón Open
-
Seleccione el archivo batch grabado E:\Test\DiffBatchTestToProd.bat
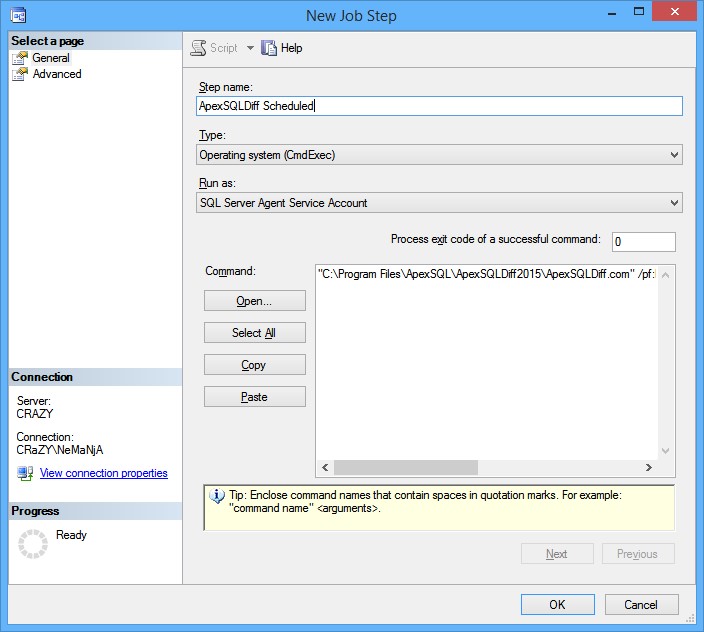
- Haga clic en el botón OK
-
Abra la pestaña Schedules y especifique cuándo debería ejecutarse la tarea de sincronización
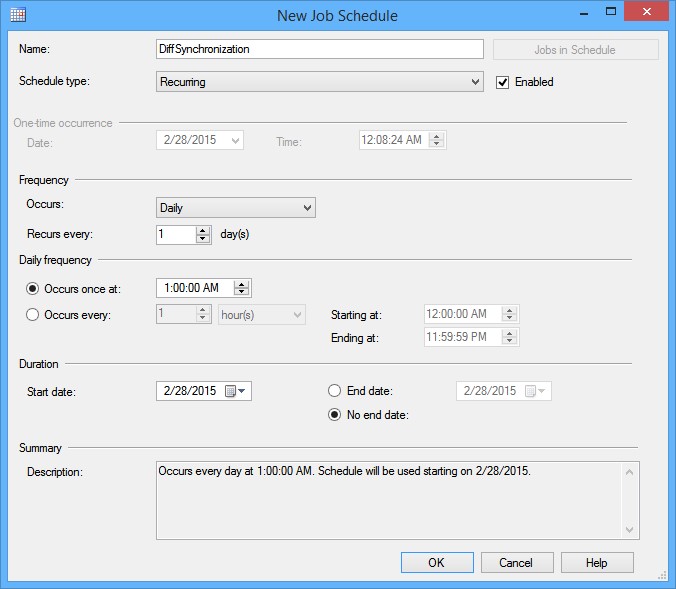
Ya no hay necesidad de preocuparse acerca de la sincronización de bases de datos. ApexSQL Diff comparará todos los objetos de base de datos, verificará las dependencias y las codificará junto a los objetos, se asegurará de que los scripts son ejecutados en el orden correcto y creará una copia de seguridad completa de la base de datos antes de la sincronización. Todo esto puede ser programado para ejecutarse de manera desatendida.
Traductor: Daniel Calbimonte
octubre 25, 2015






