



Due to the sheer volume of data usually involved in an Extract – Transform – Load (ETL) process, performance is positioned very high on the list of requirements which need to be met in order for the process to go as smoothly as possible. Here are some guidelines which will help you speed up your high volume ETL processes
Load only changed rows
A key consideration in reducing the volume of the data that is loaded by an individual ETL process, is to extract only those rows which are new or have changed since the previous ETL run from the source system. The worst possible thing you can do performance wise is to fully load the data to staging and then filter it there. The most efficient approach is to capture a snapshot of changed records at the source. This will capture added and changed records including transactional changes. This process will require modifying the date and the time of the changes – however, no intermediate will be captured. As the ETL process includes metadata such as the ETL last run date, this date can be used together with the last modification date in the source system in order to determine the exact records to be transferred.
Alternatively, producing extract tables populated with data since the last ETL run date is another way to ensure that only the changed rows will be loaded. Please note that this approach will move the CPU load from the staging server to the data source. This mechanism works well for updated and inserted rows, but not for deleted rows. If you plan to use this approach, you will need to leverage “soft deletions” (i.e. use deletion indicators instead of physically deleting the rows from the source)
Use batching whenever possible
Batching can be achieved in two ways, either by running the data extraction more frequently or by logically partitioning the rows to be extracted. Dividing the data logically – for example, by country or ZIP codes – would allow extractions to be performed at different times, which in turn results in reducing the amount of data transferred per ETL load execution. This reduces concurrent network load and resource contention at the staging database
Bottom line – even with both strategies in place, extracting huge amounts of data will have an impact on the SQL server resources. This impact can prove to be particularly nasty if another part of the process fails resulting in restarting the process itself. The obvious solution would be to take a backup of the source and restore it on a different SQL instance. However, restoring a database backup of a large SQL database will a significant amount of time (not to mention disk space). This is where ApexSQL Restore can help
ApexSQL Restore attaches both native and natively compressed SQL database and transaction log backups as live databases, accessible via SQL Server Management Studio, Visual Studio or any third party tool. It allows attaching single or multiple backup files including full, differential and transaction log backups, making it ideal for continuous integration environments, quickly reverting inadvertent or malicious changes and balancing heavy report loads. For more information, visit the ApexSQL Restore product page
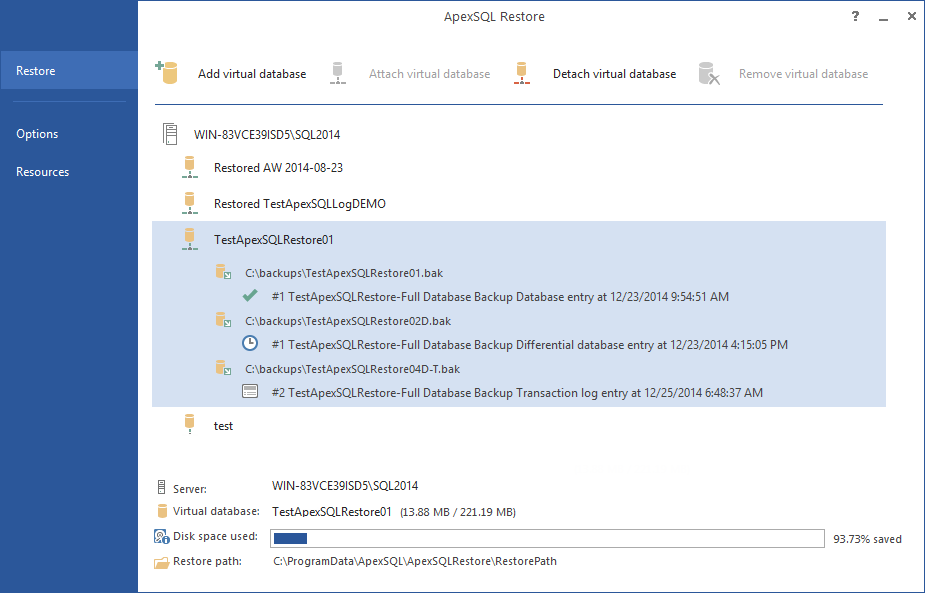
To utilize a secondary server as the data source in an ETL process using ApexSQL Restore:
- Start ApexSQL Restore
- Click the Add a virtual database button
- In the dialog that will appear provide:
- The name of the SQL Server instance you want to use as a the data source
- The preferred authentication method for that instance; a valid set SQL Server credentials needs to be provided if you opt for SQL Server authentication
- The name of the database that will be used as the extract source
- Click Next
- Click the Add file button, and navigate to the backup file which holds the data to be used in the process
-
Click Open
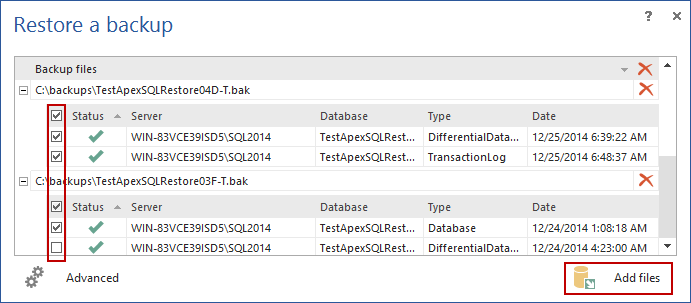
- Click Finish to attach the backup
Following the seven simple steps outlined above, in addition to using only the rows that have changed and batching the updates can significantly improve the performance of your ETL process and lighten the load on the original ETL data source
April 23, 2013






