



Ogni database SQL Server è mappato ad un insieme di file. Questi file portano con sé dati e informazioni sulle transazioni effettuate. I file sono utilizzati solo da un database e i dati non sono mai mixati con le informazioni di transazione. Mentre i dati sono salvati su file con estensione MDF (per il primario) ed NDF (per i secondari), le transazioni risiedono nel file di log, con estensione LDF. Concettualmente il file di log è una stringa di record di log. Fisicamente i record di log sono salvati in un file LDF (o più) che implementa, appunto, il log delle transazioni.
Lo scopo fondamentale di questo file è di assicurare il concetto di ACID (Atomicità, Consistenza, Isolamento e Durevolezza).
- Atomicità: se una parte della transazione fallisce, deve fallire l’intera transazione senza lasciare il database in uno stato inconsistente. Lo stato deve essere quello precedente alla transazione fallita
- Consistenza: ogni transazione porta il database da uno stato ad un altro stato valido
- Isolamento: Una transazione rappresenta un’unità di isolamento, in quanto consente che le transazioni simultanee abbiano luogo come se ciascuna di esse fosse l’unica transazione in esecuzione nel sistema
- Durevolezza: Una transazione rappresenta inoltre un’unità di recupero. Se una transazione ha esito positivo, il sistema garantisce che gli aggiornamenti da essa effettuati persistano, anche se il computer si blocca immediatamente dopo il commit
Un file LDF mantiene al suo interno sufficienti informazioni per replicare operazioni o eseguirne un annullamento, o ancora per recuperare il database in uno specifico istante. Pertanto, a causa di processi di audit o a causa di requisiti per il recupero, vi è la necessità di aprire il file e di capirne il contenuto. Ma non è così semplice come potrebbe sembrare.
Ci sono vari metodi, come usare le funzioni non documentante e i comandi console (sempre non documentati) come ad esempio fn_dblog, fn_dump_log, DBCC PAGE. Tuttavia è necessaria una profonda conoscenza del T-SQL, anche solo per rendere leggibile il contenuto del file LDF.
-
Questo è un esempio di utilizzo della fn_dblog, con un risultato suddiviso in 129 colonne (mostrate solo 7):

-
La fn_dump_dblog viene utilizzata per leggere dal log delle transazioni nativamente oppure da un suo backup compresso. Il risultato è del tutto simile:

Sfortunatamente non ci sono documentazioni ufficiali per le funzioni ai due punti precedenti. Per trasformare il contenuto delle colonne è necessario conoscere le strutture dei dati ed il loro numero.
-
DBCC PAGE viene utilizzato per leggere il contenuto dei file di un database online (sia MDF che LDF). L’output è in esadecimale ed è difficile da interpretare.

Utilizzare ApexSQL Log come lettore di file LDF
ApexSQL Log è un lettore di log per SQL Server che legge le tranasazioni da un file di log online, da un file di log scollegato oppure dai backup del log delle transazioni (compressi e non). Come visualizzatore di LDF si focalizza sulle operazioni DML e DDL (45 in totale) e su cosa è cambiato a fronte di quelle operazioni. Oltre che mostrare il contenuto dei file LDF, ApexSQL Log fornisce funzionalità aggiuntive come la creazione di script di undo o redo, la storia dei cambiamenti dei record e altro ancora.
Ecco come procedere:
-
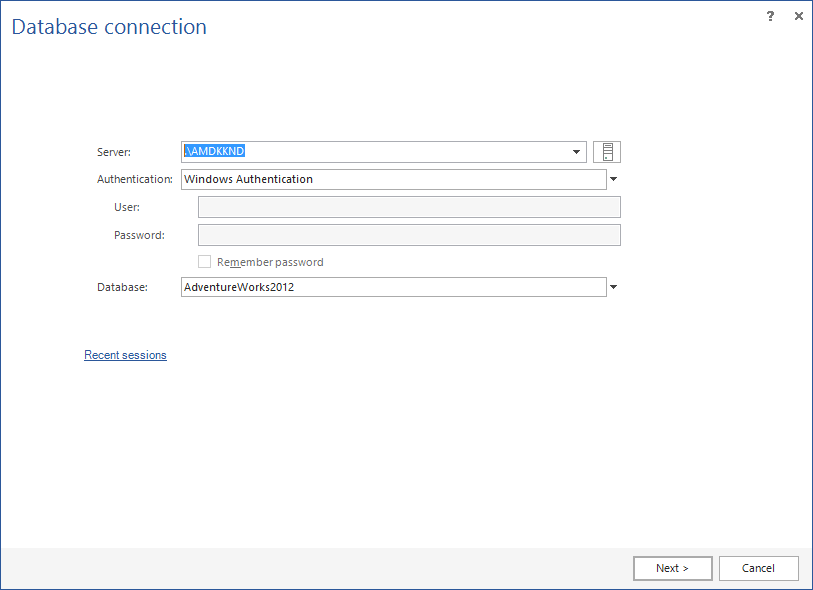
Connettersi al database al quale il file LDF è collegato:
-
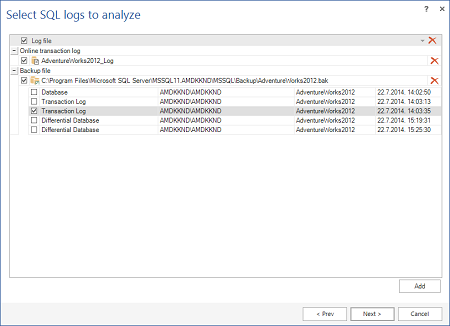
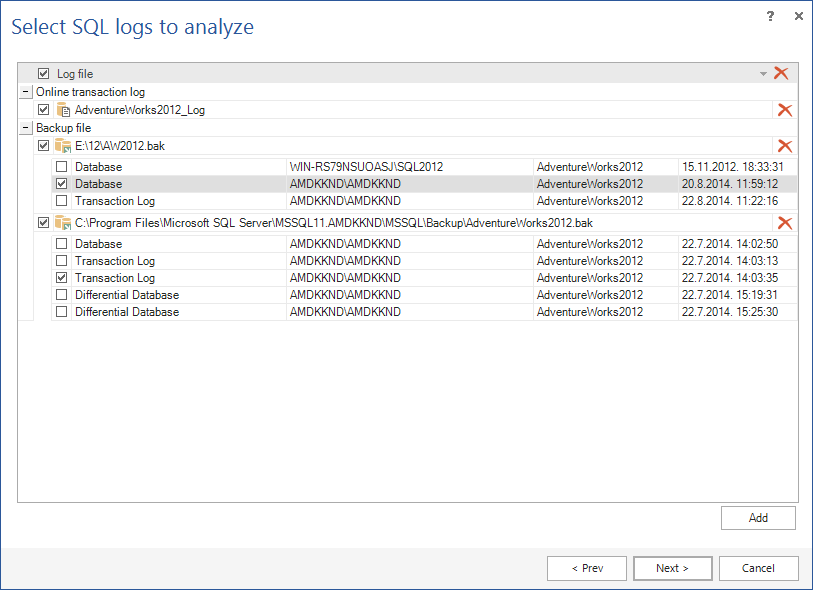
Il prossimo passo è di aggiungere file LDF, backup del log e/o file LDF scollegati. L’importante è caricare una catena di log completa. Una catena di log è una sequenza continua di backup dei log. Inizia con un backup full di un database, seguito dai relativi backup dei log. Nel caso in cui ci siano file corrotti, solamente la parte antecedente il danno sarà leggibile con informazioni complete ed esaurienti.
A differenza delle operazioni di INSERT e DELETE, che sono registrate per intero nel file di log, le UPDATE sono salvate con le sole informazioni essenziali (minimally logged). Vengono infatti salvati solo i cambiamenti e non i valori precedenti/nuovi.
Quando una UPDATE è registrata SQL Server si occupa di persistere solamente la parte di valore cambiata e non il valore intero precedente e nuovo. Ad esempio, se la parola “log” viene cambiata in “blog”, SQL Server aggiungerà, in linea generale, una “b” in posizione zero. Questo è quanto basta per garantire le proprietà ACID. ApexSQL Log deve ricostruire la storia dei cambiamenti per dare informazioni esaurienti. Per raggiungere questo obbiettivo ApexSQL Log utilizza tecniche di ricostruzione degli stati delle righe. Per questo necessita di una catena completa. Avendola, sarà possibile ricostruire anche perfettamente la storia di record soggetti ad UPDATE.
Nel nostro esempio, ApexSQL Log ricava lo stato della riga nel backup, estraendo il valore “log” e, da qui, determina il nuovo valore dopo l’aggiunta della “b” alla posizione zero. Con la catena completa è possibile velocizzare questo processo evitando, di fatto, la lettura dal log delle transazioni online (unico e più grande di solito).
In aggiunta è possibile specificare anche un file LDF scollegato.
-
Premere Add nella vista Select SQL logs to analyze
-
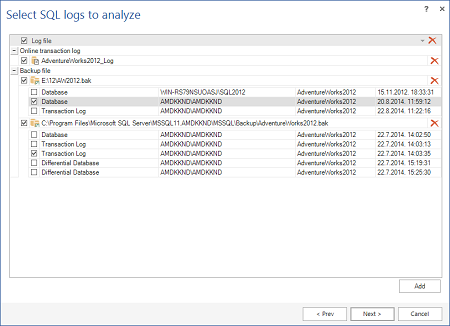
Con il tab Database backups deve essere caricato il backup completo da cui partire:
-
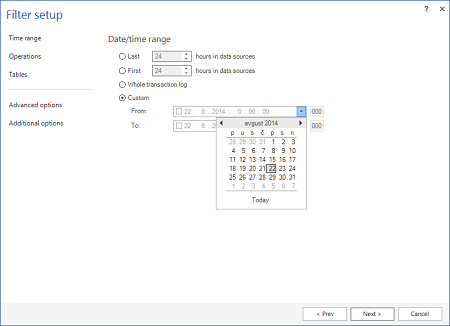
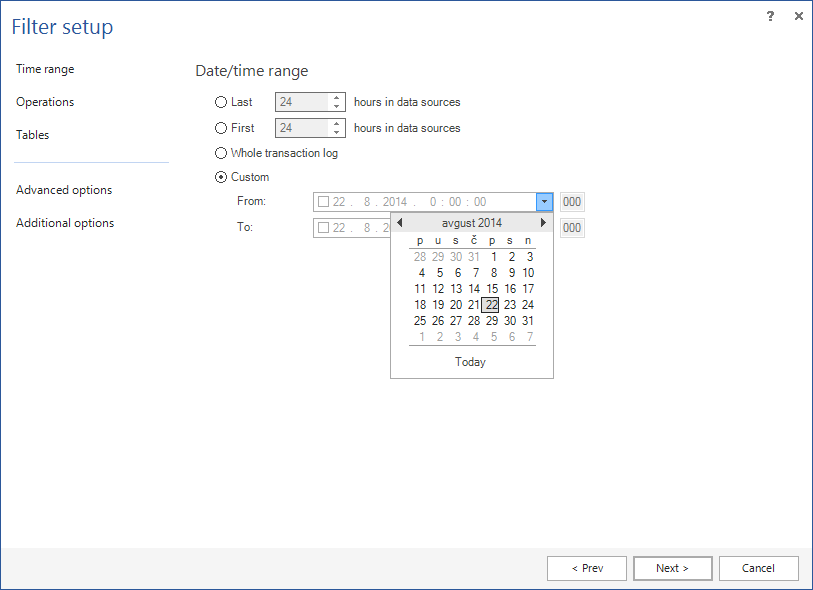
Con l’opzione Time range in Filter setup, specificare l’intervallo di date su cui ricercare. Più è isolata la ricerca, migliori saranno le prestazioni e maggiore sarà il dettaglio di risultato
-
La lettura del file LDF partità alla pressione del tasto Open
-
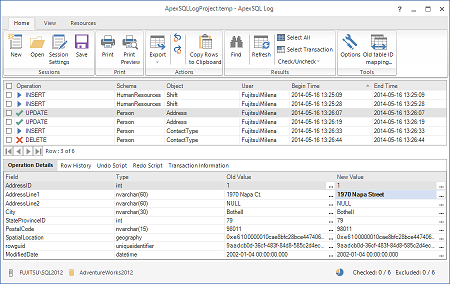
Alla fine del processo, i risultati relativi alle impostazioni definite verranno mostrate sulla griglia principale di ApexSQL Log
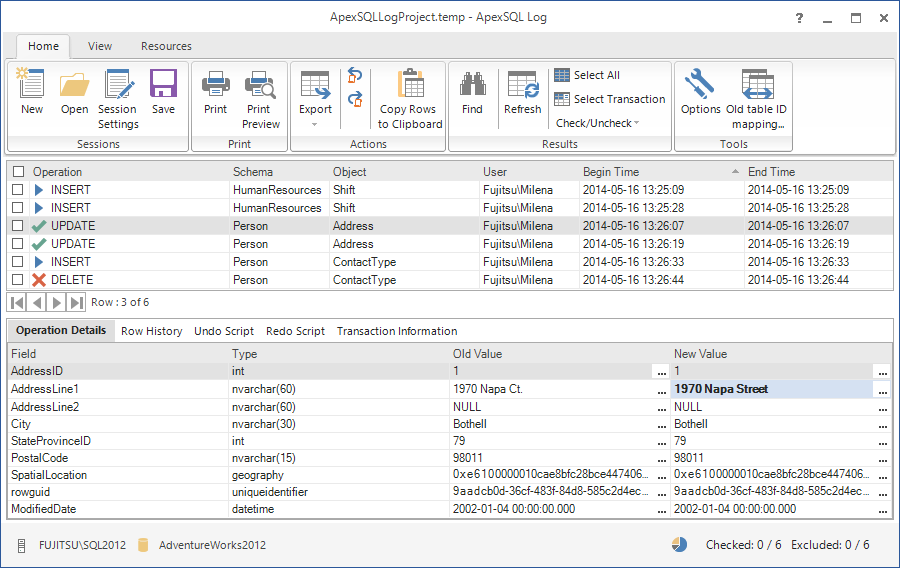
Conclusioni
Come descritt, ci sono varie modalità di lettura di un file LDF, e la maggior parte di loro semplicemente aprono il file stesso, nulla di più. Inoltre vi è da convertire le informazioni lette, poiché non comprensibili con una semplice lettura.
ApexSQL Log non si limita ad aprire file. Porta bensì del valore aggiunto. Infatti potremo visualizzare i tipi di operazione, lo schema degli oggetti toccati, i nomi, gli oggetti coinvolti, l’istante dell’esecuzione, il nome dell’utente che ha eseguito la modifica e non solo.
I very vantaggi di questo tipo di processo sono:
- Avere accesso a informazioni leggibili dall’uomo (da esadecimale e binario)
- Concatenare più file per un unico processo
- Combinare backup e file scollegati per analizzare le transazioni in dettaglio
- Ricostruire la storia dei record sottoposti ad UPDATE (vecchi e nuovi valori nel tempo)
- Mostrare chi ha effettuato l’operazione, quando essa è stata effettuata e quali sono stati i cambiamenti nel tempo
- Prefiltrare i risultati
- Recuperare i dati delle tabelle che non esistono più (utilizzando un mapping)
- Mostrare le informazioni di un file LDF senza conoscere il T-SQL
ApexSQL Log fornisce inoltre:
- Gestione della griglia dei risultati (ordinamenti, layut, filtri)
- Esportazione dei dati in CSV, HTML, XML, o SQL tramite wizard dedicati per analisi successive
- Creazione di script SQL per la rollback o per il replay delle transazioni. Questo può essere estremamente utile in scenari di recupero, quando dati mancanti devono essere ripristinati, oppure dopo cambiamenti di schema che devono essere annullati, senza utilizzare ripristini di backup
- Una documentazione ufficiale per ogni funzionalità
- Un supporto tecnico, e ancora tanto altro
Autore Ivan Stankovic
Traduttore Alessandro Alpi
September 26, 2014






