



Scenario
Immaginiamo un’applicazione utilizzata dai rappresentanti o dai distaccamenti (usata ad esempio dai corrieri, dai medici e via discorrendo) progettata per collezionare dati direttamente sui posti e per inviarli ad una ipotetica sede centrale. Essa non solo invierà dati, ma riceverà le informazioni il più aggiornate possibile direttamente dalla sede centrale.
Ad esempio, quando un rappresentante vende un prodotto, inserisce tramite software l’ordine di acquisto, tipicamente usando dispositivi mobili. L’entry poi viene inviata al gestionale centralizzato, in modo da consolidare l’ordine. Ma per avere la giacenza di magazzino, le informazioni del dispositivo dovranno essere aggiornate il più possibile per non dare falsi riscontri durante la fase di acquisto.
Lo scenario di cui sopra evidenzia la necessità di una sincronizzazione costante fra i dispositivi remoti e le “sedi centrali”.
Soluzioni
La prima soluzione è l’utilizzo della replica di SQL Server. Essa si occupa di copiare e di distribuire i record da un database ad altri che possono essere anche dislocati geograficamente. Ci sono tuttavia alcuni limiti che rendono la replica inutilizzabile:
- Le uniche edizioni che possono pubblicare le informazioni (distribuirle) sono la Standard e la Enterprise (anche la Business Intelligence). Con la express è disponibile solo la possibilità di ricevere (sottoscriversi).
- La replica web non è disponibile per una configurazione che ha un distributore SQL 2005 ed un sottoscrittore SQL 2008.
- Chi distribuisce deve avere la versione maggiore o uguale di chi sottoscrive
- La versione del sottoscrittore nel caso di replica transazionale non deve essere inferiore di due versioni rispetto a quella di chi pubblica (ad esempio, 2000 – 2012 non è possibile)
- La versione del sottoscrittore nel caso di replica merge deve essere minore o uguale rispetto a quella di chi pubblica (ad esempio, sottoscrittori 2012 – pubblicatore 2008 non è possibile)
La seconda soluzione è utilizzre il Sync Framework, ovver un’API che ci dà la possibilità di creare applicazioni e di sincronizzare in automatico i database. Fornisce molta flessibilità ma richiede ovviamente sviluppo, il che incrementa i costi ed i tempi dell’implementazione della soluzione. Inoltra il Sync Framework sembra non essere più molto seguito come indicato qui.
La terza è utilizzare ApexSQL Data Diff, uno strumento per la comparazione e la sincronizzazione sui dati di SQL Server che rileva le differenze dei dati e che le risolve senza errori. Può fare comparazione e sincronizzazione di database online ma anche di backup e backup nativamente compressi e genera report delle differenze rilevate. Inoltre crea un file da eseguire per sincronizzare i dati.
Come funziona
Immaginiamo di avere un database centralizzato nell’azienda in cui si ricevono gli ordini (prendendo l’esempio all’inizio) ed un database dislocato (sul dispositivo mobile del rappresentante). L’azienda aggiunge un record negli articoli e il rappresentante sincronizza il suo dispositivo ogni giorno per leggere gli ultimi cambiamenti sui dati. Gli ordini fatti dai rappresentanti saranno salvati giornalmente nel proprio database locale.
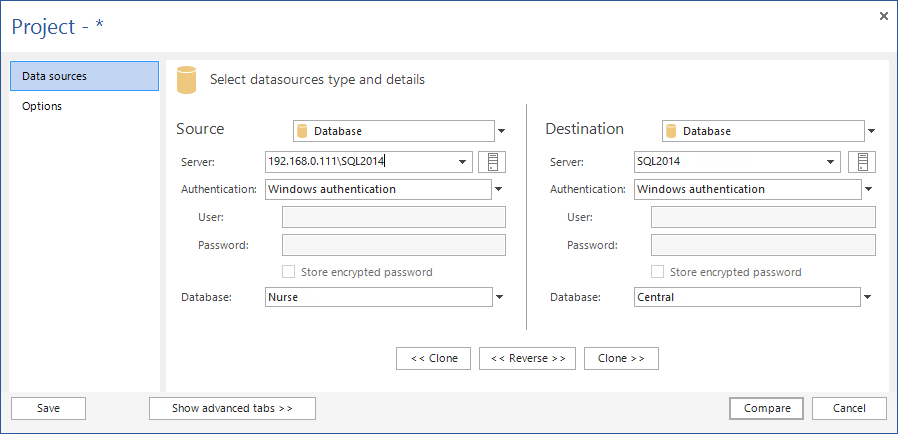
- Eseguire ApexSQL Data Diff
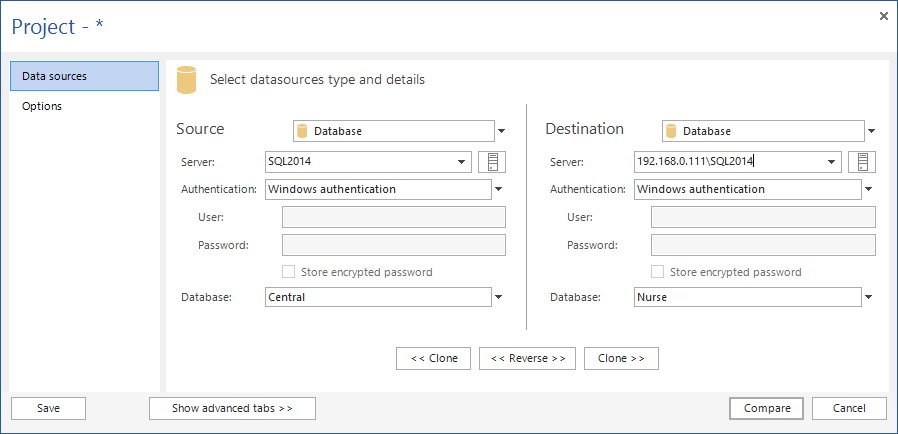
- In Source, selezionare Database come tipo, il server centralizzato come server, ed il database centrale
- In Destination, selezionare Database come tipo, il dispositivo (quello del rappresentante) come server, e come database quello da sincronizzare
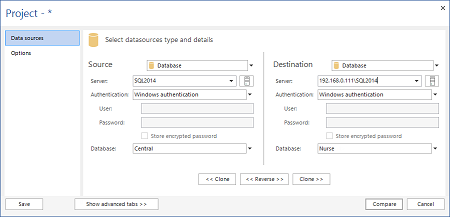
- Premere Compare. Tutte le tabelle verranno sincronizzate ed il risultato sarà visualizzato nella griglia principale
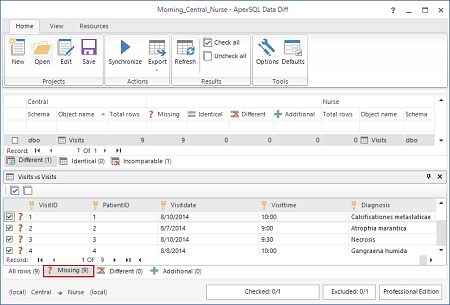
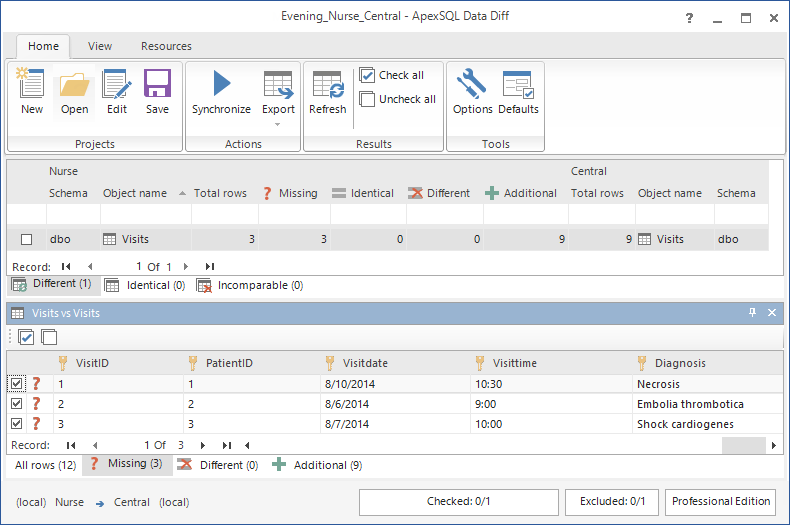
I record inseriti nel database aziendale verranno mostrati nel tab Missing
- Selezionare le tabelle da sincronizzare

- Premere Synchronize sul tab Home
- Premere Next al passaggio Synchronization direction del Synchronization wizard
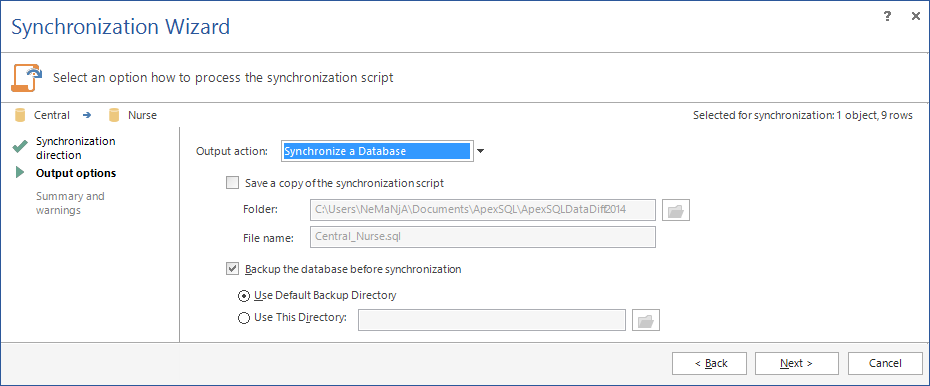
- Nel passaggio Output options del Synchronization wizard, selezionare Synchronize a database come azione di output
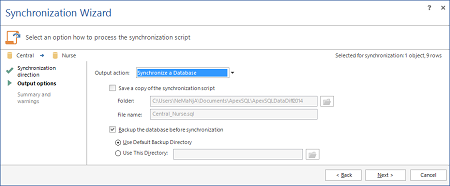
- Premere Next
- Controllare il sommario delle operazioni che verranno eseguite e valutare gli eventuali warning.
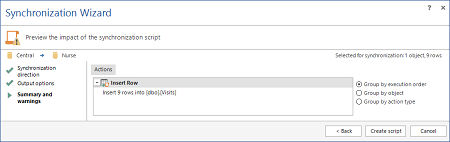
- Premere Synchronize
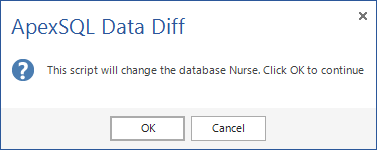
- Premere OK
- Premare Save nel tab Home, per salvare le opzioni configurate durante la progettazione della fase di sincronizzazione. Queste impostazioni potranno poi essere riutilizzate in futuro.



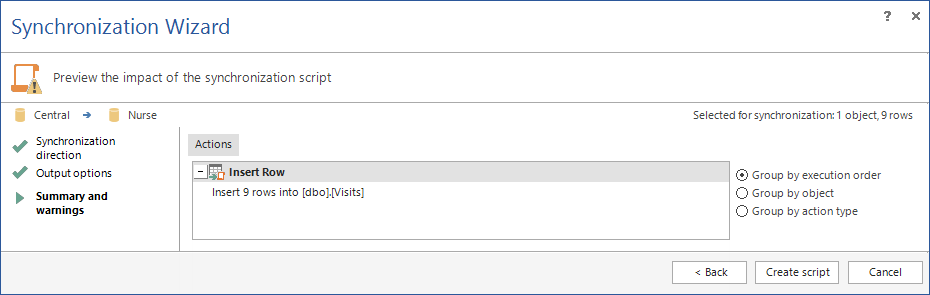
Quando l’esecuzione è completata verrà mostrata la seguente vista:
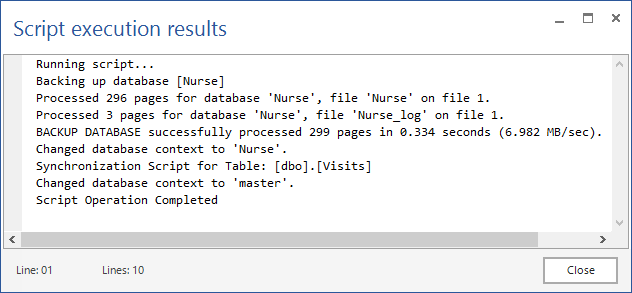
Nel caso in cui si volesse sincronizzare nell’altra direzione (dal dispositivo al centralizzato) i passi sono del tutto simili:
- In Source impostare il database del dispositivo e il database aziendale in Destination
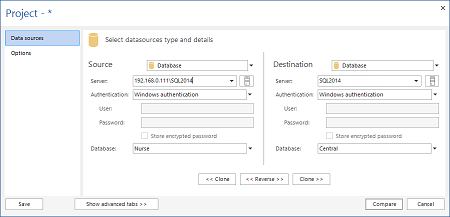
- Premere Compare
- Selezionare le tabelle da sincronizzare. I record mancanti in destinazione verranno mostrati nel tab Missing
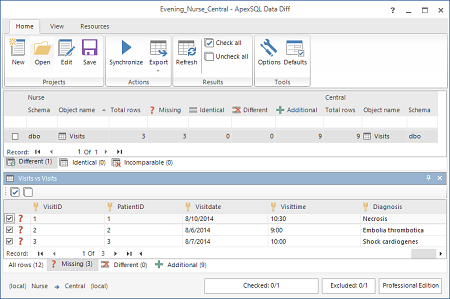
- Premere Synchronize nel menu
- Seguire I passi del Synchronization wizard e aggiungere i record nella tabella di destinazione
- Premare Save nel tab Home per salvare le impostazioni della fase di sincronizzazione
Ora che abbiamo i progetti salvati è possibile automatizzare il processo:
- Salvare il comando seguente in un file su disco (esempio, E:\Test\Mattino.bat). Questo file verrà eseguito insieme al progetto Mattina_Azienda_Rappresentante.axdd:
"C:\Program files (x86)\ApexSQL\ApexSQLDataDiff2014\ApexSQLDataDiff.com" / pf:D: \Test\Morning_Central_Nurse.axdd / of:D: \Test\MorningSync.sql / sync / bu:D: \Test / v / f
Questo comando creerà un file SQL chiamato SyncMattina.sql come indicato nel comando.
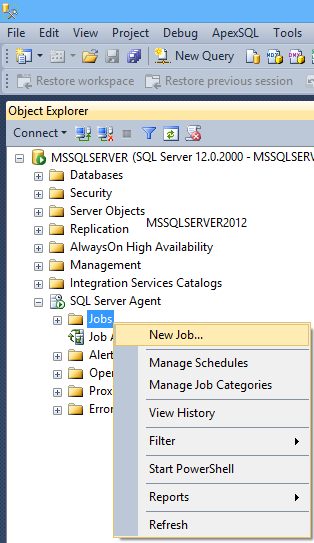
- Eseguire SQL Server Management Studio
- In Esplora Oggetti espandere il nodo SQL Server Agent, premere il tasto destroy su Jobs e selezionare New job per creare un nuovo processo
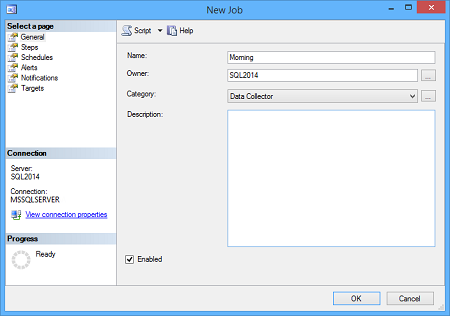
- Specificare il nome del processo
- Nel tab Steps, Premere New per aggiungere un passo da eseguire
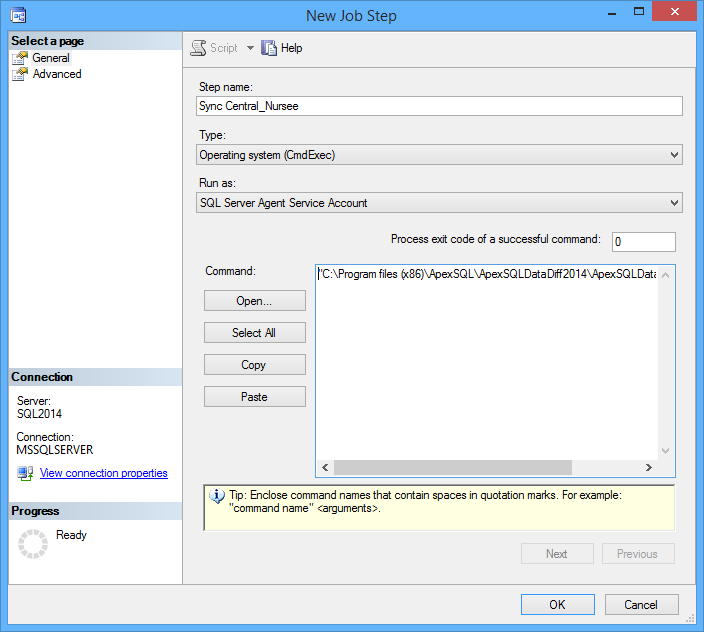
- Specificare Operating system (CmdExec) nel tipo, dare un nome allo step e premere Open
- Selezionare il file salvato in E:\Test\SyncMattina.bat
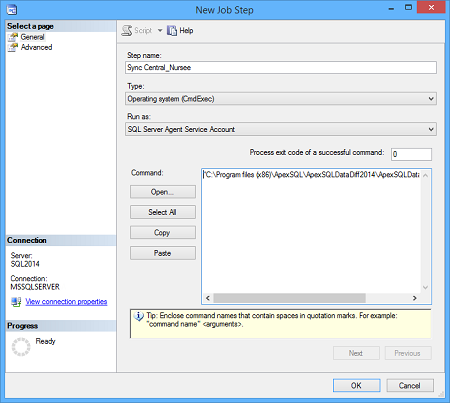
- Premere OK
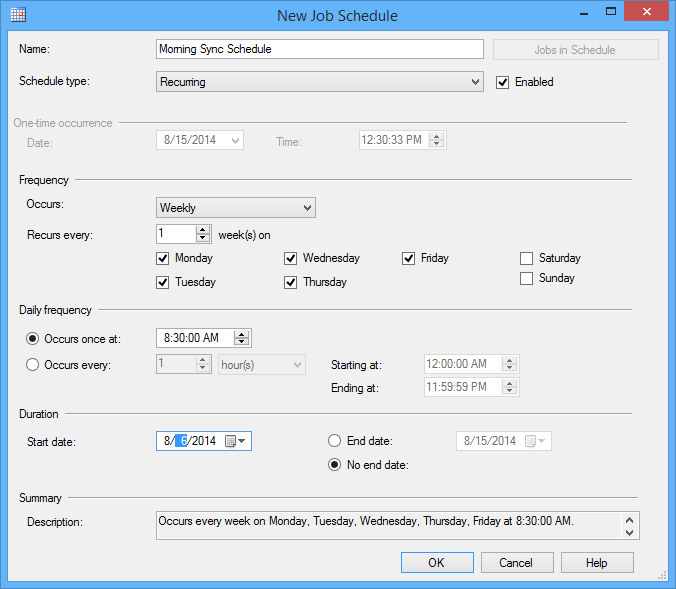
- Aprire Schedules e specificare gli intervalli di tempo per la schedulazione
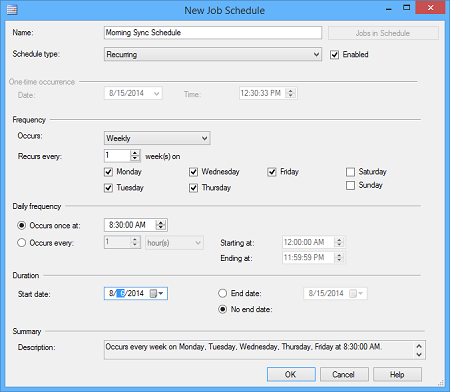
Ripetere gli step dal 3 al 9 per schedulare ogni sincronizzazione.

La comparazione la sincronizzazione dei database SQL Server remoti con database interni a datacenter utilizzando ApexSQL Data Diff può essere fatta senza preoccuparsi di versioni ed edizioni. Inoltre non serve nemmeno avere conoscenza di programmazione. È sufficiente conoscere i server in cui i database risiedono.
Traduttore: Alessandro Alpi
October 1, 2014






