



If SQL queries perform sluggishly and severely impact SQL Server performance, the solution can be very simple – in some cases all that needs to be done is to not use the * wildcard in the SELECT statement.
One of the most common performance and scalability problems are queries that return too many columns or too many rows. Although the reasons for this might seem straightforward as returning unnecessary table rows and columns wastes CPU time, memory, disk and network bandwidth simply due to the fact they are unnecessary, the reasons go way deeper than that.
Namely, the columns in the SELECT clause are also considered by the optimizer when it identifies indexes to generate the execution plan. Using a SELECT * query not only returns unnecessary data, but it also can force clustered index scans for the query execution plan, regardless of the WHERE clause restrictions as the cost of going back to the clustered index to return the remaining data from the row after using a non-clustered index to limit the result set is actually more resource-intensive (in some cases, twice as expensive) than scanning the clustered index in the first place.
To add insult to injury, SELECT * obscures the specific list of columns that will be returned, which may result in unanticipated errors in calling code (e.g. application code) that are difficult to diagnose.
The only solution to this is to reference only the needed columns in SELECT SQL queries, even when the data from all of the columns is actually need. . This way, besides preventing the query from taxing database resources in order to return unnecessary data and speeding up query execution plan, the queries will become more transparent and thus easier to troubleshoot.
Now, here comes the real catch – all of this seems easy enough on paper, but in reality, this means that it will be needed to often look at scripts where to explicitly name 20+ columns. This process is not only tedious, it’s very error-prone and hence, frustrating.
This is where ApexSQL Refactor comes to play.
ApexSQL Refactor is a SQL Server Management Studio and Visual Studio add-in which formats and refactors SQL code using nearly 15 code refactors and over 200 formatting options. It expands wildcard, fully qualifies object names, renames SQL database objects and parameters without breaking dependencies and much more.
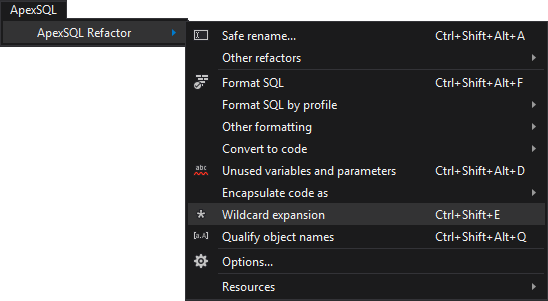
To replace the * wildcard with the list of the referenced column names:
- Open the SQL script in SQL Server Management Studio or Visual Studio
- From the ApexSQL menu click the ApexSQL Refactor from the list
- Select the Wildcard expansion command
For example:
| Before: |
SELECT * FROM SalesLT.Address
| After: |
SELECT Address.AddressID, Address.AddressLine1, Address.AddressLine2, Address.City, Address.StateProvince, Address.CountryRegion, Address.PostalCode, Address.rowguid, Address.ModifiedDate FROM SalesLT.Address
The Wildcard expansion code refactor of ApexSQL Refactor is an effective way to improve SQL query performance and prevent errors related to wildcards in SELECT statements as well as improving the quality and readability of SQL code.
April 4, 2013






