



A “one-to-many” relationship is one of the most common relationship types as many real world scenarios can be represented using it. For instance, the same product can be sold by more than one supplier; a customer can have more than address, and so on.
The straightforward solution
Usually, the one-to-many relationship is implemented by referencing the table which represents the “one” side of the relationship in the table that represents the “many” side. For example, let’s consider a database which needs to hold information on the products the company is selling as well as the user reviews for each product. If the data on the products and the reviews is stored in tables respectively named Product and Review, the obvious solution is to add a column (let’s name it ProductID) to the Review table and set up a foreign key on that column referencing the primary key of the Product table. This way each review is linked to the appropriate product while preserving the referential integrity. So far, so good:
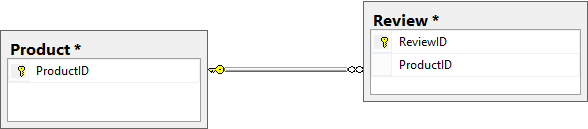
Handling design changes
What will happen if one day the management decides that in addition to the current comments system, users can rate the product using five-star review system? There are several ways to handle this requirement. One approach that might be taken is to isolate the data for the new rating system in a separate table named Rating. This way, a real world is modeled more accurately as each type of customer feedback, although related, represents one separate entity. Now, a way to link the rating data with the comment the user left and the appropriate product is needed. This can be solved by adding two columns to the Rating table which will reference the Product and the Review tables accordingly. As it can be seen, this approach is not very robust since adding a new type of customer feedback will effectively double the number of existing relationships between the affected tables:
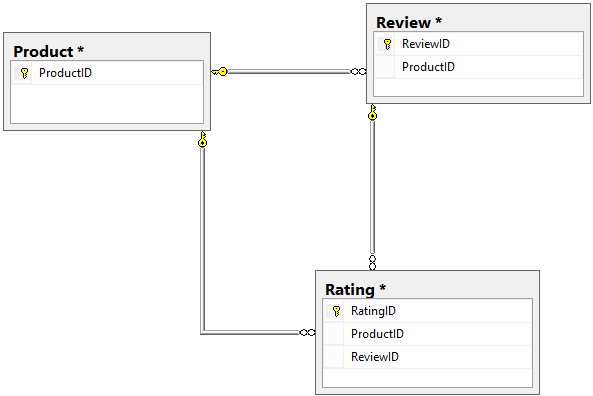
Therefore, in these scenarios using associative (also known as cross-reference, bridge, join, map, intersection, linking, pairing, pivot, transition or junction) tables is the better approach as they isolate the relationships in a separate table thus keeping the relationships explicit and the design more impervious to changes in businesses requirements.
Using association tables
Association tables contain common fields from two or more other database tables within the same database. They are on the many side of a one-to-many relationship with each of the other tables. Therefore, if a robust database design needs to be enforced from the get-go, the relationship between Product and Review in a separate association table should be isolated. This way, if the database needs to support additional types of customer feedback, the appropriate tables and relationships between the different feedback types can be added in an explicit and consistent manner. In this example, the association table between Product and Review should contain only the columns ProductID and ReviewID as a primary key, thus guaranteeing uniqueness of each product – review pair. Each of those columns would be a foreign key to the tables Product and Review respectively.
Now, implementing association tables at design time is straightforward. However, replacing the one-to-many relationship with an association table after the database has been deployed involves a bit of effort. Not only that it’s needed to populate the association table properly and remove the foreign key columns from the tables on the many sides of the relationship also it’s needed to update all object referencing those columns accordingly Searching for dependencies manually is an error-prone process as SQL Server cannot identify all objects’ interdependencies. For instance, querying syscomments might yield different results than when using sp_MSdependencies. Missing to update a dependent object might cause real trouble down the road, especially if the dependency-related errors surface a long time after the association table has been introduced. This is where SQL formatter from ApexSQL can help.
ApexSQL Refactor is a SQL Server Management Studio and Visual Studio add-in which formats and refactors SQL code using 11 code refactors and over 200 formatting options. It expands wildcards, fully qualifies object names, renames SQL database objects and parameters without breaking dependencies and much more.
To replace a one-to-many relationship with an association table using ApexSQL Refactor:
- Select the table on the many side of the relationship in either SQL Server Management Studio or Visual Studio
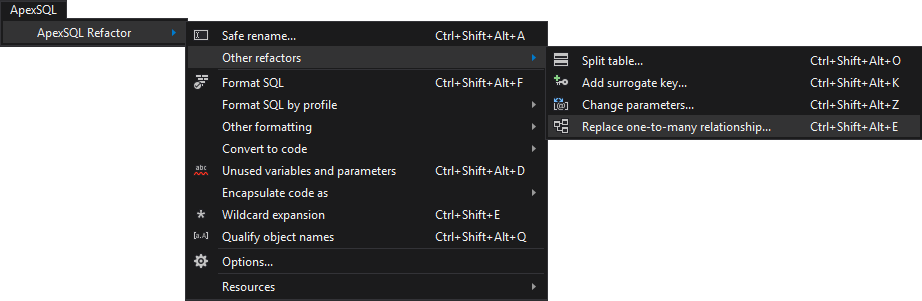
- From the Main menu go to the ApexSQL and choose the ApexSQL Refactor
-
Select the Replace one-to-many relationship command:
- Specify:
- The name of the association table that will be created
- The foreign key reflecting the one-to-many relationship which will be replaced
- The dependent table name
-
Click Preview to preview the change SQL script which will be executed:
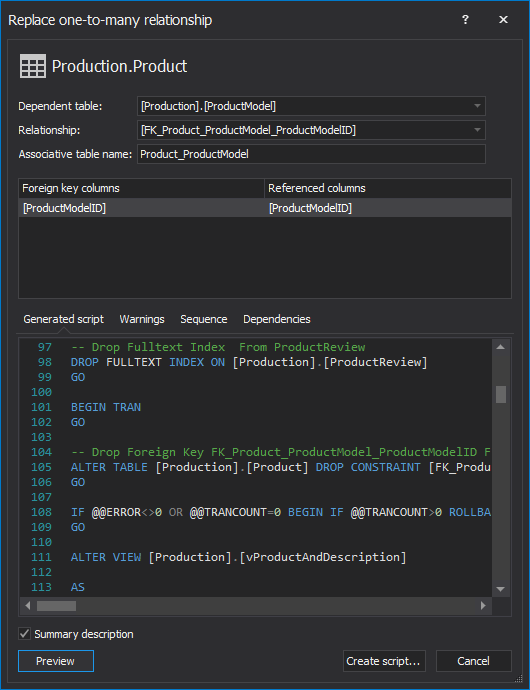
-
Review the Sequence tab to ensure that all of the actions will be executed in the proper dependency order:
- Select the Dependencies tab to preview the dependent objects which will be updated automatically to reflect the change
- Click the Create script button to open script for the association table
- Execute opened script
This will result in the relationship between Product and Review to be isolated in the ProductReviews table:
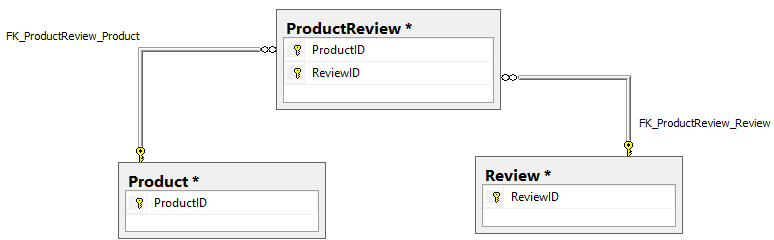
In summary, replacing one-to-many relationships with association tables can increase the robustness, efficiency, and clarity of database design, and ApexSQL Refactor can make that replacement very quickly and completely risk-free for a database structure.
May 21, 2013






