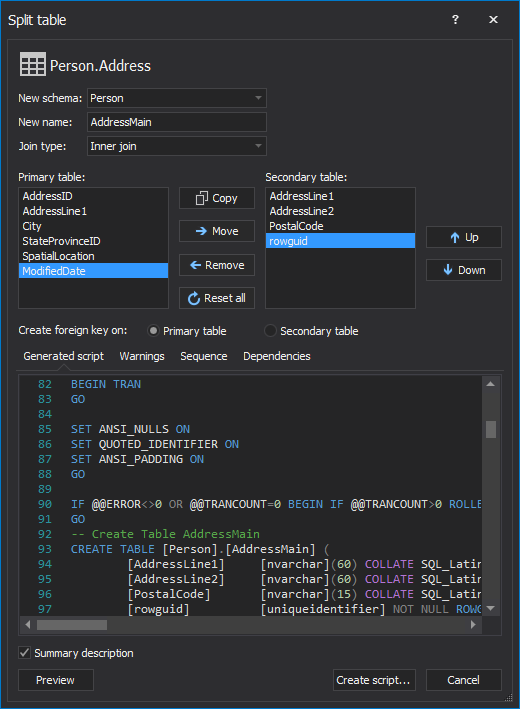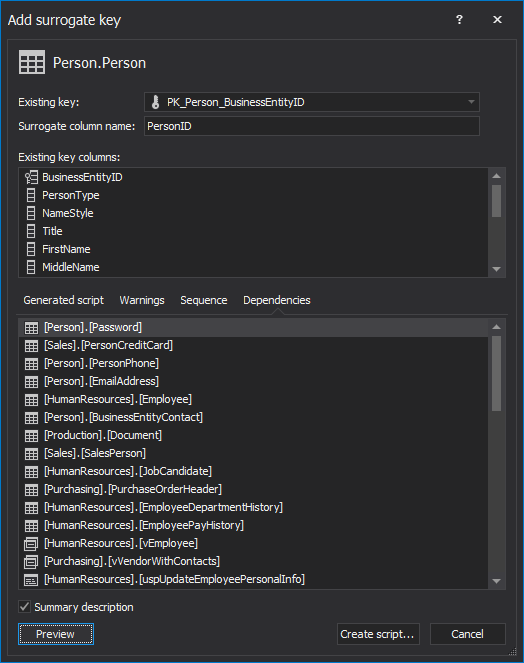
Determining just the right primary key for tables is one of the most important parts of a robust, high-quality database design. The key candidates and the keys themselves need to be picked with caution, as suboptimal choices can snowball out of control and leave the bloated, slow databases which require heavy maintenance and require massive amounts of work to meet changes in the business requirements. Therefore, due to the importance of the primary keys for the future behavior of the database, their impact on the database performance needs to be weighted as well. So, from a performance standpoint, should replacing complex natural keys with a surrogate key be considered?
April 4, 2013