



Vista general de los eventos de conmutación por error
En general, los términos “conmutación por error” se refieren a cambiar de una máquina previamente activa, otro componente de hardware o red, a una pasiva (o sin uso), para sostener la disponibilidad y confiabilidadaltas. En la mayoría de casos, un evento de conmutación por error es un proceso automático, mientras que un evento similar, de cambio de servidor, requiere la intervención manual en el cambio entre elementos activos/pasivos.
La conmutación por error está incorporada en las configuraciones de alta disponibilidad en SQL Server (desde la versión 2012 y posteriores). En este artículo, la Instancia de Clúster de Conmutación por Error (como parte del grupo de servidores Windows Server Failover Clustering, abreviado WSFC) será cubierta para mostrar cómo monitorear eventos de conmutación por error de SQL Server cuando ocurren.
Instancia de Clúster de Conmutación por Error de SQL Server
Una Instancia de Clúster de Conmutación por Error (Failover Cluster Instance – FCI) es una instancia basada en servidor que actúa como una instancia SQL Server regular, pero es instalada en una multitud de nodosWSFC. Estos nodos presentan puntos de conexión en FCI, y son usualmente máquinas físicas con características similares (por ejemplo, en la configuración del hardware o el Sistema Operativo). Su configuración de jerarquía y trabajo es la por defecto, establecida como un grupo de nodos activos y pasivos. Aunque la FCI se parece a una instancia de una sola máquina (si se usa remotamente), esta aprovecha la alta disponibilidad y administra el proceso de conmutación por error entre los nodos activos y pasivos, en momento cuando uno de ellos está no disponible.
En una FCI de SQL Server, el proceso de conmutación por error en sí mismo es automático por defecto, pero este proceso puede ser iniciado manualmente, si se necesita, por ejemplo cuando se trata del mantenimiento de todo el servidor, o un nodo en particular (máquina).
Determinar cuándo ocurrieron eventos de conmutación por error
En este artículo, como se estableció previamente, el enfoque estará en la ocurrencia de los eventos de conmutación por error de SQL Server y su monitoreo. El monitoreo directo de los eventos de conmutación por error no es posible. El monitoreo debe ser hecho programáticamente.
Verificar qué nodo FCI está activo (T-SQL)
Determine qué nodo está actualmente activos en FCI con este scripts (vista de sistema de los (nodos del Clúster:
SELECT NodeName, STATUS AS NodeStatus, status_description AS NodeStatusDescription, is_current_owner AS CurrentlyActiveNode FROM sys.dm_os_cluster_nodes
El evento de conmutación por error en FCI está actualmente rastreado durante el cambio de rol entre los nodos (cuando un nodo se vuelve pasivo, y el siguiente se vuelve activo). Ente este punto, el tiempo cuando ocurre la conmutación por error es desconocido. El script revela el nodo activo, pero también puede mostrar en qué estado están los otros nodos, como en los resultados de una consulta a continuación:

En la columna NodeStatus ,los valores ‘0’ y ‘1’ representan los estados en línea/fuera de línea, y la columna NodeStatusDescription la describe (arriba o abajo). La columna CurrentlyActiveNode provee información acerca de cuál nodo está activo.
Desde estos resultados, es posible que un evento de conmutación por error ocurriera, porque AOAP-NODE2 obtuvo un rol activo desde AOAP-NODE1, el cual se volvió pasivo.
Verificar si las bases de datos de disponibilidad están sincronizadas (T-SQL)
Como cada nodo en WSFC actúa como una instancia de SQL Server regular, las bases de datos son usualmente llamadas bases de datos de disponibilidad. Con este script T-SQL, verifique las bases de datos de disponibilidad en cada nodo que aún no falló, revisando su estado de preparación:
SELECT database_name, is_failover_ready FROM sys.dm_hadr_database_replica_cluster_states WHERE replica_id IN ( SELECT replica_id FROM sys.dm_hadr_availability_replica_states )
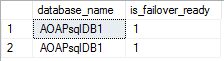
El valor ‘0’ significa que las bases de datos de disponibilidad no están sincronizadas y, sabiendo eso, una conmutación por error no exitosa potencial puede ser puesta en espera como precaución. Por otro lado, el valor ‘1’ (como se muestra arriba) significa que las bases de datos de disponibilidad son sincronizadas en todos los nodos.
Establezca la alerta de SQL Server Agent para eventos de conmutación por error
Para ser notificado de un evento de conmutación por error, establezca la alerta dentro de SQL Server Agent en una FCI deseada:
Ingrese la información requerida como se muestra en la imagen:
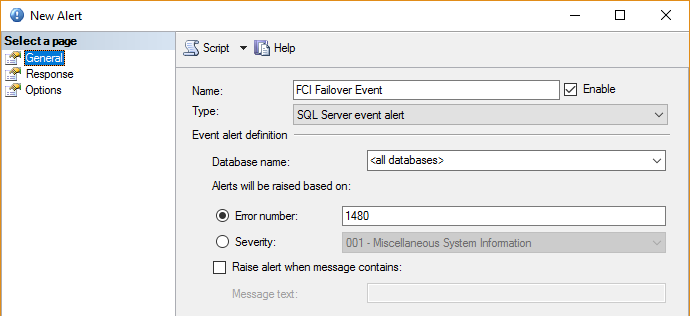
El error número 1480 (también llamado Cambio de Rol de Base de Datos Réplica), referenciado antes, representa la información de que la base de datos FCI falló en cambiar su rol esperado durante el proceso de conmutación por error o, en otras palabras, la conmutación no fue exitosa debido a la no disponibilidad de la base de datos particular.
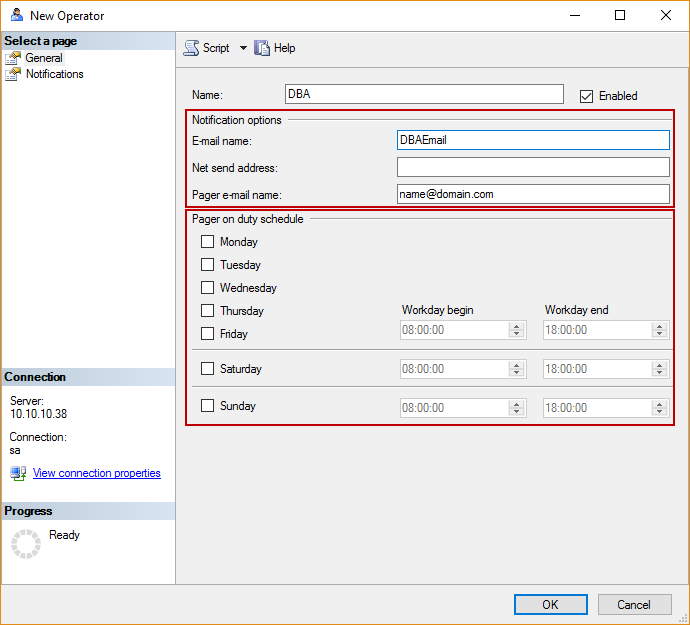
El siguiente paso es definir el operador y establecer la dirección de correo electrónico para propósitos de alerta, en la pestaña Response:
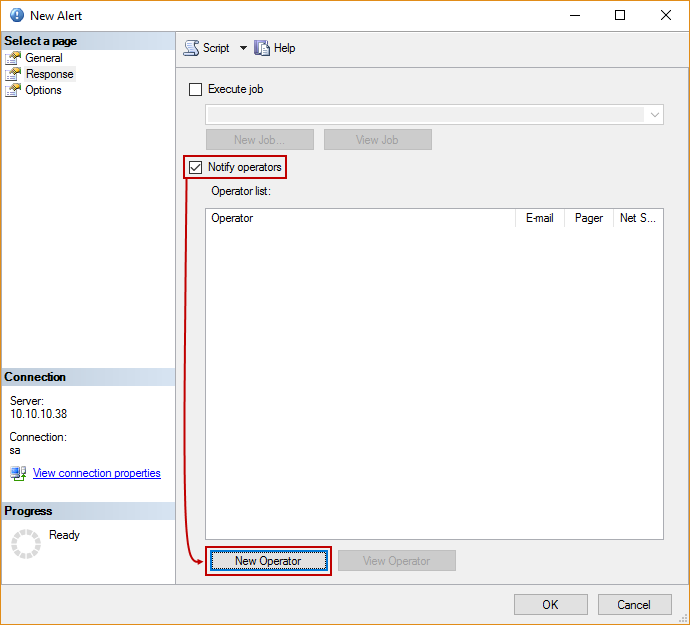
Establezca una dirección de correo electrónica válida para mandar notificaciones acerca de eventos de conmutación por error, y opcionalmente programe las horas de trabajo cuando este correo electrónico debería llegar:
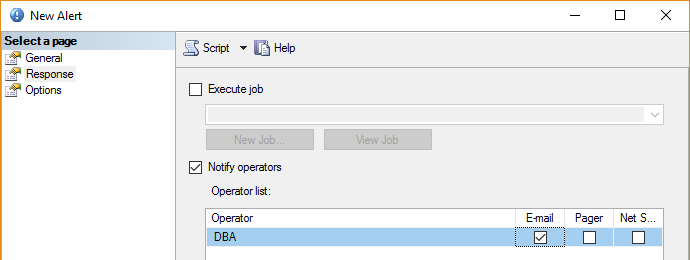
Asegúrese de verificar la opción Email, para confirmar la alerta:
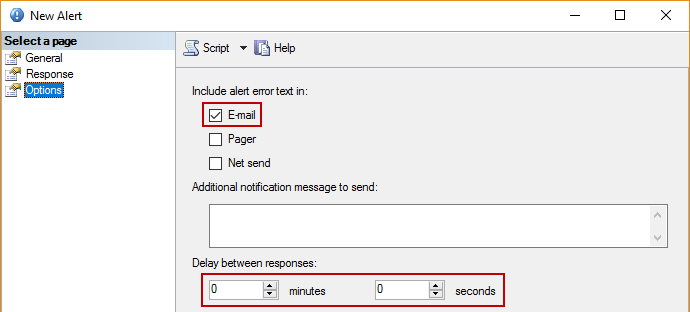
En la pestaña Options, verifique la opción para incluir el texto de la alerta de error en el correo electrónico y el rango de tiempo de retraso:
diciembre 15, 2017






