



Each event that causes data loss or disruption of regular daily operations on a SQL Server can be defined as a “disastrous” event. These events include power outages, hardware failure, virus attacks, various types of file corruption, human error, natural disasters, etc. Although there are many methods that are focused on preventing these events, they still occur from time to time and therefore require proper measures to be addressed. One of the most effective methods for this purpose is the creation of a suitable disaster recovery plan.
Popular disaster recovery solutions are based on techniques like failover clustering, database mirroring, replication, log shipping, and regular backup and restore operations. Each of these techniques has its own perks and flaws when it comes to complexity, recovery time and required resources. The backup/restore method is still most commonly used, since it requires the least amount of resources (in most cases), and is relatively simple when compared to other solutions. The method is based on creating SQL Server backup chains on a regular basis.
One of the crucial factors that have to be taken into consideration when it comes to planning a backup strategy is the recovery model of a database. A recovery model is a database property that defines how SQL Server logs each transaction, and which types of backup and restore operations are allowed on the database. There are three recovery models for the SQL Server databases: simple, full and bulk-logged recovery models.
Another major consideration when it comes to designing a backup strategy is to determine the recovery point objective (RPO). The recovery point objective is defined as the maximum targeted period in which data might be lost due to an incident.
This article will describe the most common disaster recovery strategies for each type of database recovery model, and show how to automate the entire process of making SQL Server backup chains.
Backup options and strategies for databases in simple recovery model
The main difference between the recovery models comes from the way new transactions are recorded in the transaction log. For databases in simple recovery model, each new transaction is written to the transaction log, but as soon as the transaction completes, and the data has been written to the data file, the space in the log used by the transaction gets recovered for future transactions. Therefore, the data that exists in the transaction log often gets overwritten by new transactions. This way, disk space is saved, and the size of the transaction log does not change significantly. The process of making log space available for reuse is defined as truncation. All databases that use the simple recovery model are referred to as being in auto-truncate mode.
Due to this behavior, there is no option to make a transaction log backup for simple recovery model databases (there is no point in making transaction log backup due to the frequent transaction overwrites). There is no continuous stream of transactions in the log, which makes point in time restore impossible. In practice, this means that all changes made since the last database backup can be lost in case of a disaster. Having this in mind, it is important to plan the frequency of backup operations accordingly. Since point in time restore is not possible, it is advised to use simple recovery model only with the databases that contain static data, or the data that does not get updated too often.
Advantages and disadvantages of simple recovery model databases are listed in Table:
| Advantages | Log space is automatically reclaimed to keep space requirements low. There is no need to manage disk space occupied by the transaction log |
|
Disadvantages |
No transaction log backups |
| No log shipping | |
| No database mirroring and AlwaysOn Availability Groups | |
| No media recovery without data loss | |
| Point-in-time restore is not possible. It is possible to recover only to the end of the last backup |
Databases in a simple recovery model allow only full and differential backup operations. By default, full database backups contain a copy of the entire database (at the time of backup creation), along with all user and objects data and system information related to the database (users and permissions information, and system tables and views). Differential database backups contain copies of every page that has had a change made to it since the last full backup was taken.
Having this in mind, there are two possible recovery solutions when it comes to databases in simple recovery model:
-
The backup strategy is based on full backup files only. This strategy is used for the smaller databases, where the backup process completes for a short period of time. If a backup operation completes quickly, it can be scheduled for any time of the day. In the case of the disaster, it is possible to restore the database only to a point in time when a last full database backup was created. In this case, the backup chains consist only of a single backup file. The time between two database backups should equal the recovery point objective.
-
The backup strategy is based on a combination of full and differential backup files. Performing full database backups on large databases is usually time and resource consuming. It is not feasible to run full database backups during normal operation hours since it can impact server performance. To avoid the performance impact, it is best to schedule full database backups during off-peak periods when the activity on the server is low. In this scenario, full database backups are usually made late at night. Since differential backups only capture changes made since the last full backup, they are much smaller in size and use less resources. For large databases that are not subjected to a huge number of changes, a differential backup can execute in 10% of the time it would take for a full backup. Because of the low impact on database performance, it is acceptable to schedule differential database backups during operational hours. Scheduling one or more differential backups between two full database backups cannot compare to a point-in-time restore, but does create multiple restore points that will reduce the data loss in case of the disaster, and thus significantly lower the recovery point objective. Should a disaster occur, the latest backup file prior to disaster is restored. If this happens to be a differential backup file, it is necessary to use it with the last full backup file. In this case, the backup chain is made of the full backup file combined with the last differential backup file.
Backup options and strategies for databases in full recovery model
In databases with full recovery model, all operations are logged in the transaction log file. Unlike in simple recovery model, the transaction log is not automatically truncated with new transactions. Since each transaction gets recorded in the transaction log, it is possible to perform a restore to any given transaction, or to any given point in time, without losing any data. This practically lowers recovery point objective to 0 minutes, thus making full recovery model preferred when it comes to disaster recovery.
Since there is no automatic truncation in databases, transaction logs of these databases tend to grow with each new transaction. The higher the traffic on a database, the faster will be the growth of its transaction log. The only way to truncate the transaction log, in this case, is to perform transaction log backups. As all recorded changes from the transaction log get recorded in the transaction log backup, the used space gets available for the new transactions. This makes taking transaction log backups necessary maintenance task for most full recovery model databases.
Advantages and disadvantages of full recovery model databases are listed in Table:
| Advantages | Each transaction is recorded in transaction log |
| Can recover to an arbitrary point in time (point-in-time restore) | |
| Recovery point objective is zero – the risk of losing any of the data is minimal | |
| Log shipping is supported | |
| Database mirroring and AlwaysOn Availability Groups are supported | |
| Disadvantages | Transaction log files grow with each transaction. More disk space is required |
| To control the growth of the transaction log, it is necessary to take regular transaction log backups, which require additional effort and free disk space |
Each transaction log backup captures the changes made since the last transaction log backup. The only situation when changes get recorded since the last full database backup is when transaction log backup is taken for the first time.
|
Quick tip:
When changing the recovery model of a database from simple to full, it is necessary to take one full database backup in order to initialize the transaction log. If this step is skipped, the database still functions as simple recovery model database. |
Disaster recovery strategies for full recovery model databases depend on various factors such as database size and server traffic, but they are all based on creating transaction log backup chains in SQL Server. Each backup chain consists of a sequence of transaction log backups that are created after a full backup. It is a common scenario to take one full database backup each night (or any time when server activity is low), and multiple transaction log backups during the productive hours. The frequency of transaction log backups mostly depends on server traffic. The higher the traffic, the higher should be the frequency of transaction log backups to prevent the rapid growth of the transaction log.
There are several ways to restore a database to a point in time. The most common are described in articles:
- Restore a database to a point in time – part 1
- Restore a database to a point in time – part 2
- How to restore to a point in time using ApexSQL Restore
In all cases, it is crucial that the backup chain stays intact. This means that if any of the transaction log backup files get corrupted, a restore process will be possible up to a point of the last functional transaction log backup. To ensure that the backup chains stay intact, it is advised to create regular schedules for full and transaction log backups.
Bulk logged recovery model
Databases in the bulk-logged recovery model operate in a similar way as databases in the full recovery model. Some bulk-logged operations like bulk insert and index rebuild, are logged minimally. This behavior reduces the growth of the transaction log, thus lowering the need for frequent transaction log backups. The main drawback of the bulk-logged recovery model is the inability to perform a point-in-time restore if a log backup contains details of minimally logged operations. In this case, the recovery is possible only to a point in time represented by the previous transaction log backup that does not contain any minimally logged transactions.
Backup plan for a high traffic database in full recovery model
The best way to create a continuous backup chain is to plan the schedule for each backup type. In the case of databases in a simple recovery model, scheduling a single full database backup should suffice. If we are dealing with databases in full or bulk-logged recovery model, the backup policy may also contain differential and transaction log backup schedules. An example of a backup strategy on a high traffic server will be presented in this case. Full database backup is taken daily (during the inactive hours), and transaction log backups are taken every two hours. There are two ways to create backup schedules for this plan: by defining the SQL Server Agent job and with SQL Server maintenance plans.
Automatically create backup chains with SQL Server agent jobs
Since each agent job can have only one schedule, it will be necessary to make two separate agent jobs: one for the full database backups, and one for transaction log backups. To create SQL Server agent backup jobs, perform the following steps:
-
Make sure that SQL Server Agent is running. Open Object Explorer in SQL Server Management Studio, right click on SQL Server Agent, and select Start, if agent isn’t running.
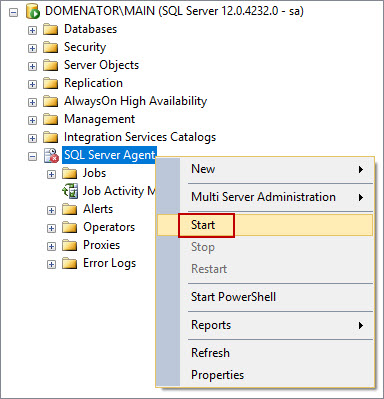
-
Expand SQL Server Agent, right click on Jobs, and select New Job… button.
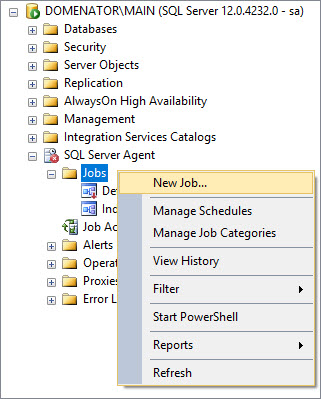
-
In General tab of the New Job wizard, provide the name and brief description of the job. Let’s make full daily database backup job first, and name it accordingly.
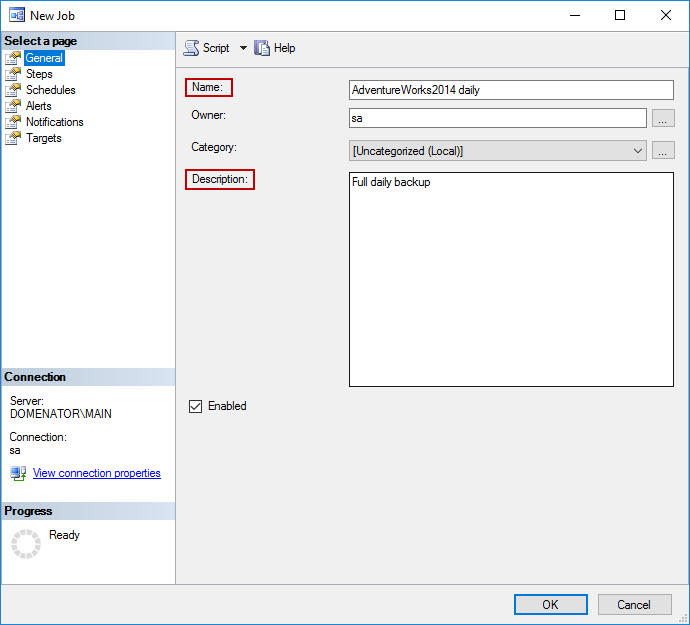
-
In Steps tab, click on the New… button.
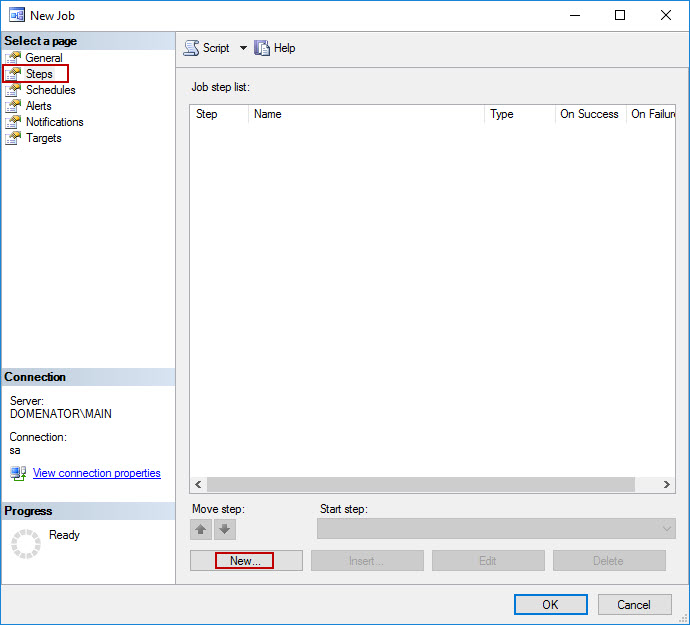
-
In New Job Step wizard, provide the step name, select T-SQL script type, and specify a database that will be backed up.
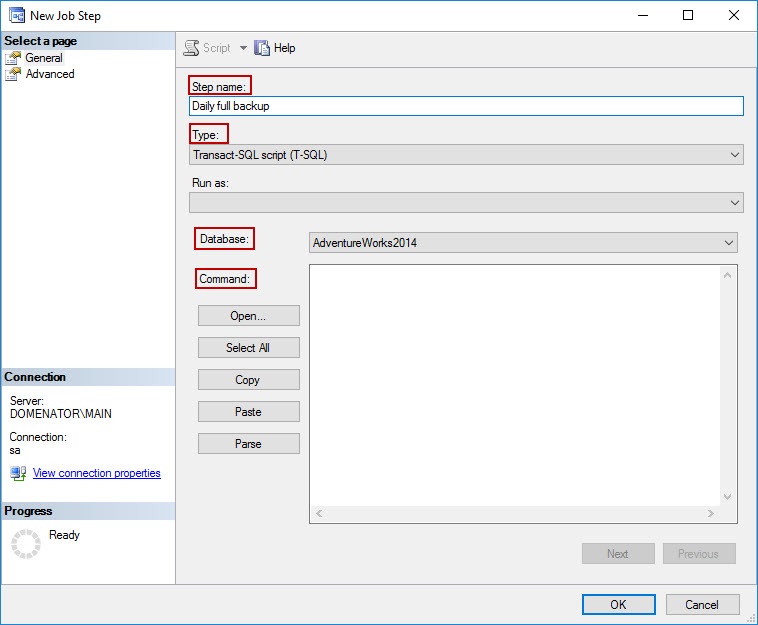
To successfully define the job step, the backup script needs to be provided in the Command text box. Since backup script uses same paths for all backup files, it is recommended to use custom script that will assign different name to each backup file. We will modify the script from the article “Create daily database backups with unique names in SQL Server”.
The script generates a name for each database backup depending on the time it was taken. In this case, the backup type should also be included in the filenames. To customize the script to run properly, it is necessary to provide the following parameters:
- Backup path in the second block in the script.
- Filename format in the fourth block in the script. The first string in the file name should contain database name and the backup type; in this case “AdventureWorks2014_Full”. The sequence of other variables in the equation determines the time format in the file name.
- The name of a database that is backed up is provided in part 5 of the script, along with the backup command.
--Script 2: Full database backup -- 1. Variable declaration DECLARE @path VARCHAR(500) DECLARE @name VARCHAR(500) DECLARE @pathwithname VARCHAR(500) DECLARE @time DATETIME DECLARE @year VARCHAR(4) DECLARE @month VARCHAR(2) DECLARE @day VARCHAR(2) DECLARE @hour VARCHAR(2) DECLARE @minute VARCHAR(2) DECLARE @second VARCHAR(2) -- 2. Setting the backup path SET @path = 'E:\DB backups\' -- 3. Getting the time values SELECT @time = GETDATE() SELECT @year = (SELECT CONVERT(VARCHAR(4), DATEPART(yy, @time))) SELECT @month = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(mm, @time), '00'))) SELECT @day = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(dd, @time), '00'))) SELECT @hour = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(hh, @time), '00'))) SELECT @minute = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(mi, @time), '00'))) SELECT @second = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(ss, @time), '00'))) -- 4. Defining the filename format SELECT @name = 'AdventureWorks2014_Full' + '_' + @year + @month + @day + @hour + @minute + @second SET @pathwithname = @path + @namE + '.bak' --5. Executing the backup command BACKUP DATABASE [AdventureWorks2014] TO DISK = @pathwithname WITH NOFORMAT, NOINIT, SKIP, REWIND, NOUNLOAD, STATS = 10
As soon as the script is copied, or loaded in the Command text box, click Ok to close the New Job Step wizard and save changes.
-
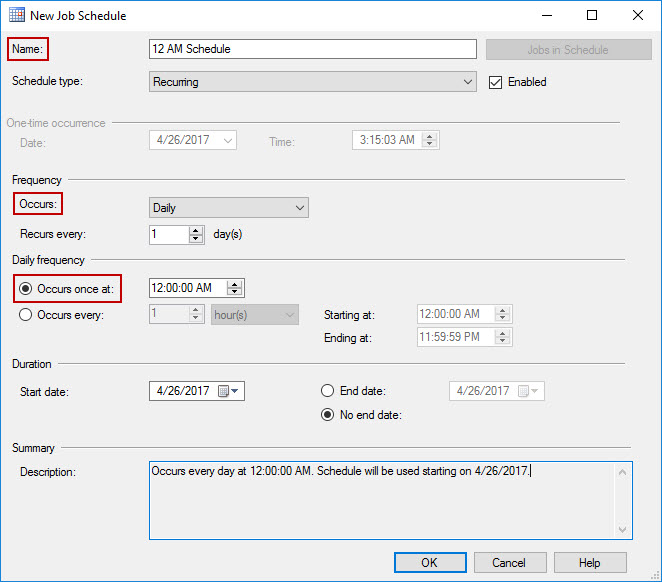
In the Schedules tab of the New job wizard, click on the New… button to open New Job Schedule dialogue. Provide a name for the schedule, set its frequency to Daily and specify the time for the backup operation. Choose the time when there is little, or no traffic on the server, because taking full database backups of large databases can be resource consuming. Click Ok to create the job schedule.
-
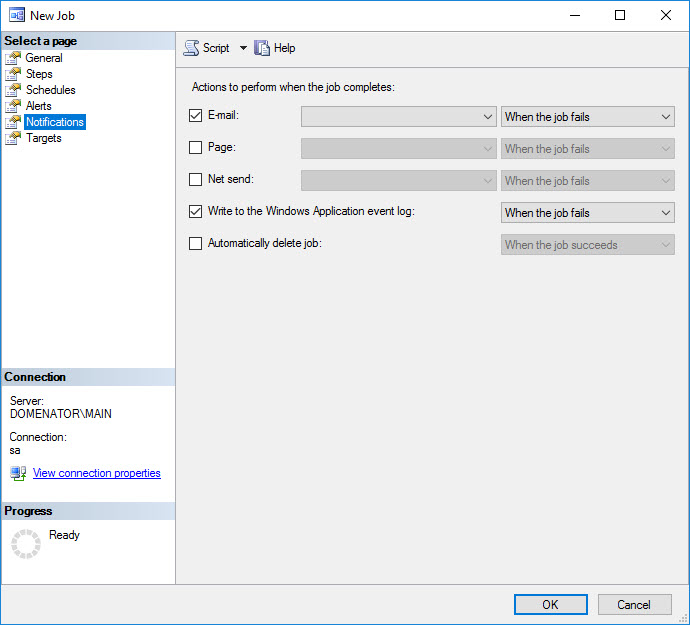
If needed, set email notifications for the job in Notifications tab. Click on OK button to close the wizard, and save the new job.
-
To create a job that will create transaction log backups each hour, repeat all steps from 2 to 4. Apply different naming rules to distinguish it from the full backup job.
-
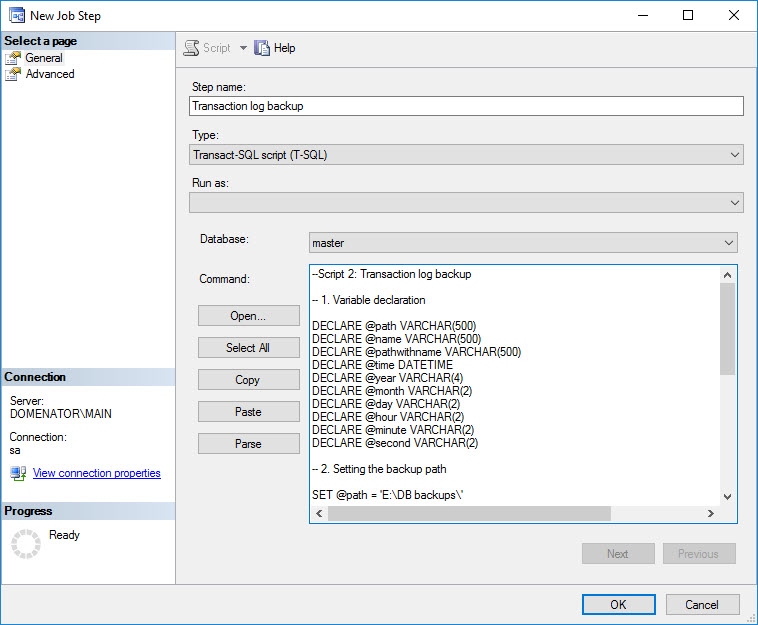
In New Job Step wizard, the script that is used will be slightly different than the one that was used for taking the full backup file:
- Change the string in the fourth part of the script to “AdventureWorks2014_Log” or similar, to tell the difference between full and transaction log backup files.
- In the fifth part of the script, command is changed to “Backup LOG”.
--Script 2: Transaction log backup -- 1. Variable declaration DECLARE @path VARCHAR(500) DECLARE @name VARCHAR(500) DECLARE @pathwithname VARCHAR(500) DECLARE @time DATETIME DECLARE @year VARCHAR(4) DECLARE @month VARCHAR(2) DECLARE @day VARCHAR(2) DECLARE @hour VARCHAR(2) DECLARE @minute VARCHAR(2) DECLARE @second VARCHAR(2) -- 2. Setting the backup path SET @path = 'E:\DB backups\' -- 3. Getting the time values SELECT @time = GETDATE() SELECT @year = (SELECT CONVERT(VARCHAR(4), DATEPART(yy, @time))) SELECT @month = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(mm, @time), '00'))) SELECT @day = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(dd, @time), '00'))) SELECT @hour = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(hh, @time), '00'))) SELECT @minute = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(mi, @time), '00'))) SELECT @second = (SELECT CONVERT(VARCHAR(2), FORMAT(DATEPART(ss, @time), '00'))) -- 4. Defining the filename format SELECT @name = 'AdventureWorks2014_Log' + '_' + @year + @month + @day + @hour + @minute + @second SET @pathwithname = @path + @namE + '.bak' --5. Executing the backup command BACKUP LOG [AdventureWorks2014] TO DISK = @pathwithname WITH NOFORMAT, NOINIT, SKIP, REWIND, NOUNLOAD, STATS = 10
-
When finished, click OK to save the job step.
-
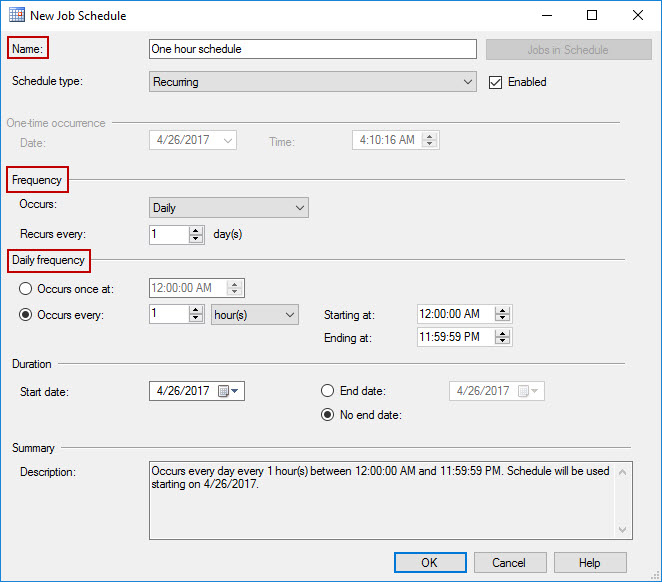
In Schedules tab, clicking on New… button creates a new schedule. Provide the name for the schedule, set the Frequency to daily, and set the Daily frequency to run every hour. Click OK to close schedule wizard.
-
Optionally, set alerts and notifications as described in step 7. Click OK button in New Job wizard to complete creating the job.
-
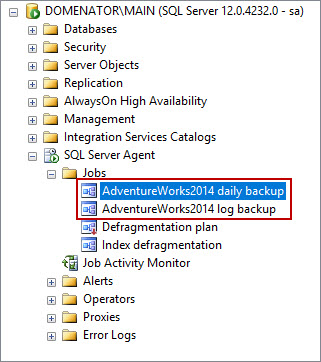
Both backup jobs are now configured to run automatically according to the set schedule. Both jobs are easily accessible in SQL Server Agent group, Jobs node. If needed, they can be run at any time from the context menu by selecting Start Job at Step…
-
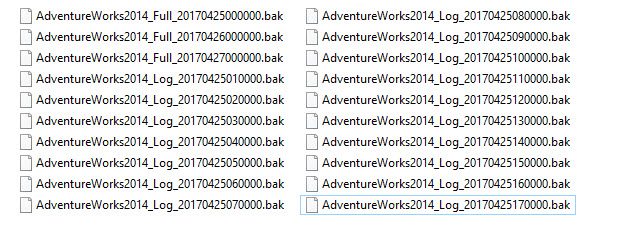
Backup files are automatically generated as long as jobs are enabled, and SQL Server Agent is running.
Automatically create backup chains with SQL Server maintenance plans
Creating a maintenance does not require the use of T-SQL scripts, and can be configured easily with the use of the Maintenance plan wizard.
-
To start the wizard, open the Object Explorer in SQL Server Management Studio, and expand Management node. Right click on Maintenance Plans, and select Maintenance Plan Wizard.
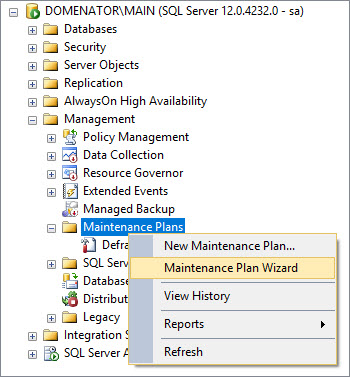
-
Click Next to skip first step of the wizard.
-
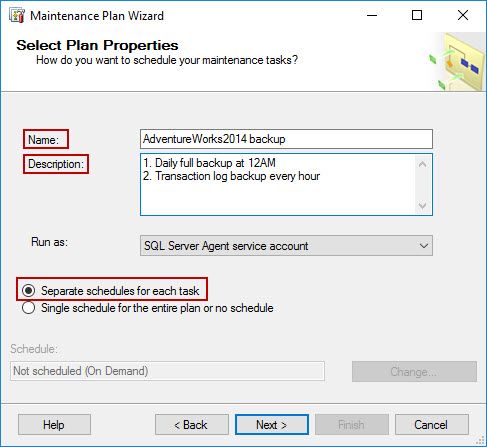
Provide a name and description for the maintenance plan. Since each backup task within the plan requires a separate schedule, select the radio button for Separate schedules for each task, and click Next to proceed.
-
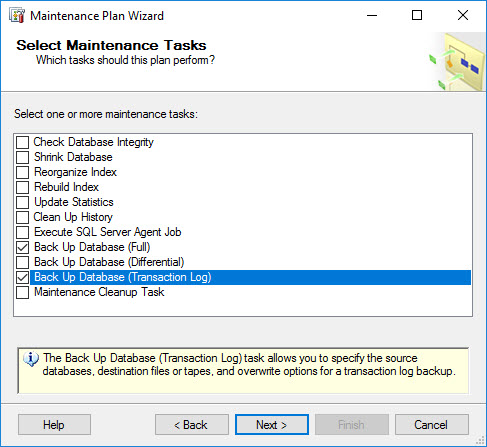
Select two maintenance tasks: Back Up database (Full) and Back Up Database (Transaction Log).
-
The maintenance task order is irrelevant in this case, since each task uses its own schedule. Click Next to proceed.
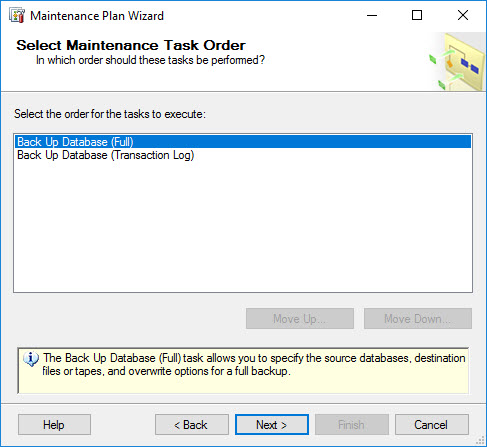
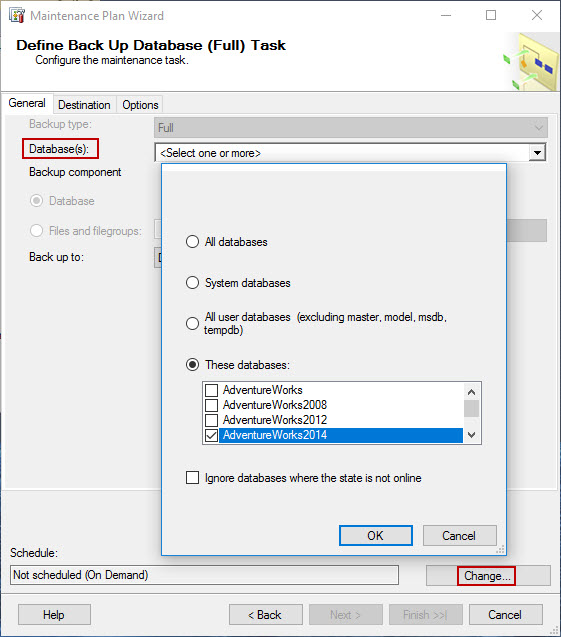
-
To configure the maintenance task for full backup operations, select the target database from the drop-down list. To set the schedule for the task, click on Change… button in Schedule section.
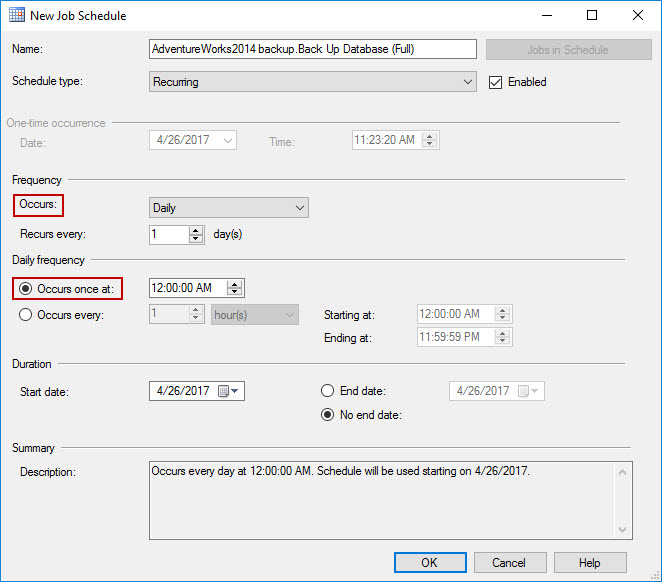
-
Configure the schedule to run each day at the preferred time. Click OK to save changes.
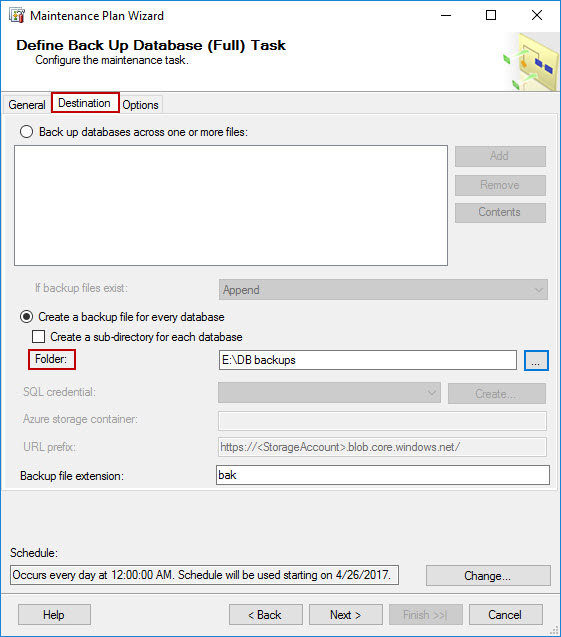
-
In the Destination tab of Maintenance Plan Wizard, select the option to Create backup file for every database. Since only one database got selected in the step 6, only one backup file will be created. Provide the path for backup files in Folder text box, and click Next to proceed.
-
A similar configuration can be applied to transaction log backup task. Select the database from Database(s) drop-down list, and click Change… button to configure the schedule.
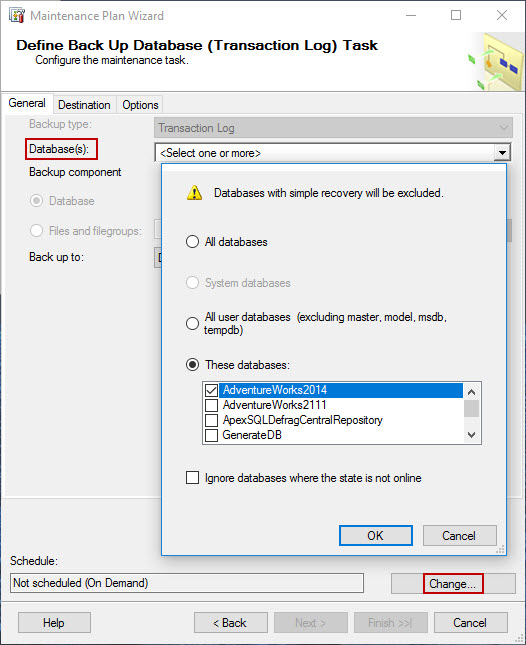
-
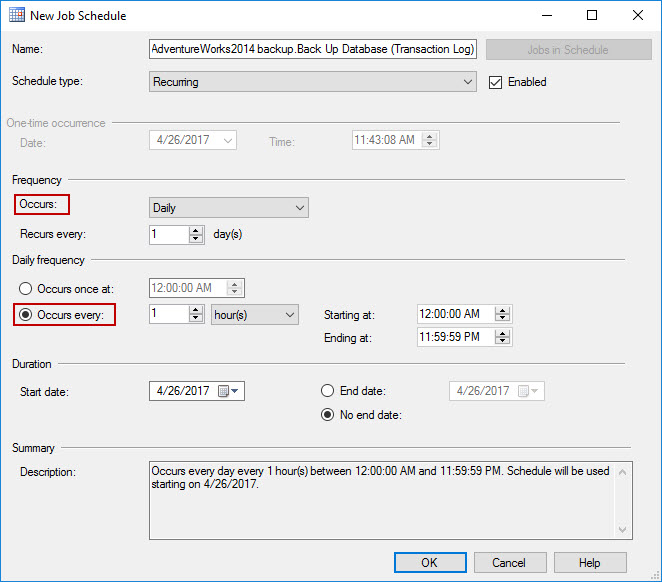
Set the schedule to run daily, every hour, and click OK to save it.
-
Same as in step 8, select the option to create a backup file for every database in Destination tab, and provide the destination path in Folder text box.
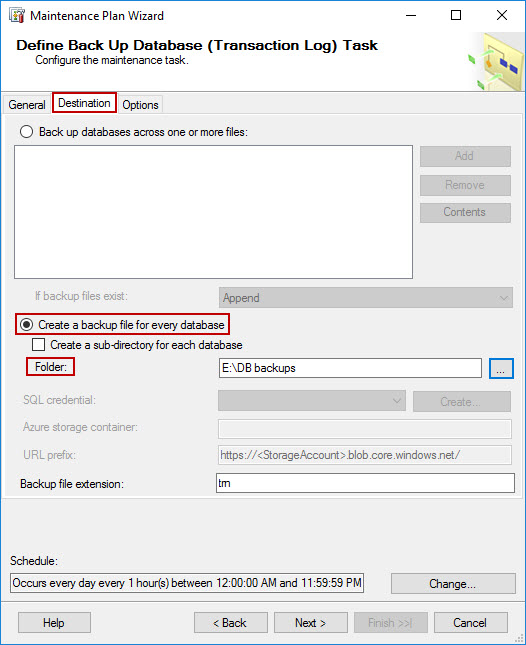
-
If needed, set the destination path for the text report, and specify the recipient for E-mail reports. When done, click Next.
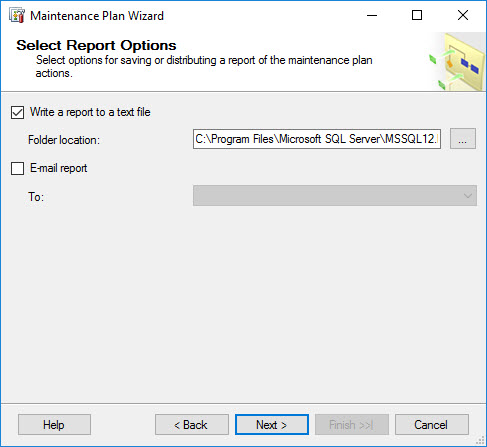
-
All changes made so far can be reviewed in the final step of the wizard. To complete configuration, click on Finish button.
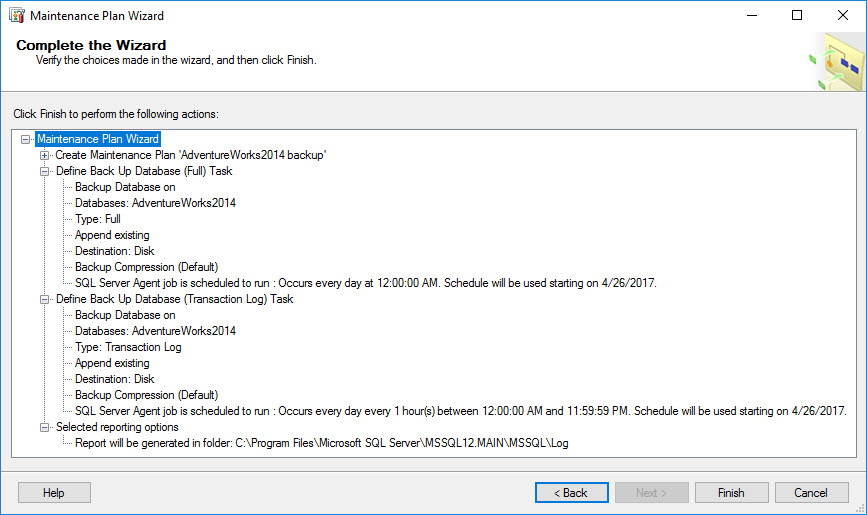
-
Success massage is generated as soon as all tasks are scheduled. Click Close to exit the wizard.
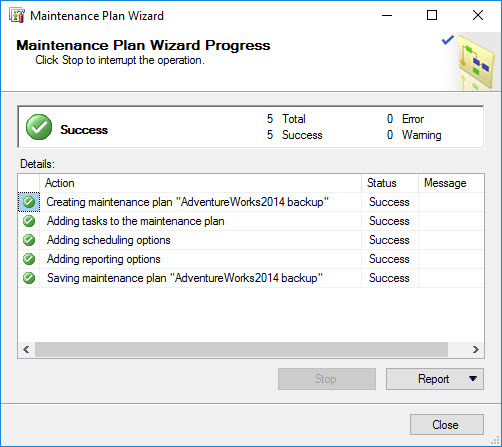
-
The maintenance plan automatically created and scheduled two separate SQL Server agent jobs. Each of these jobs can be run, stopped, enabled or disabled from the context menu in SQL Server Agent Jobs node.
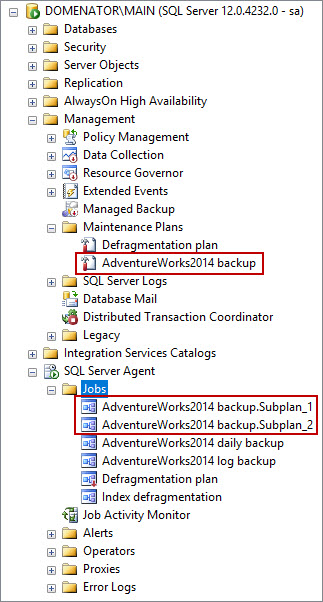
-
The maintenance plan will be enabled by default and it will create a full database backup each day at midnight and a transaction log backup every hour.
One of the disadvantages of using maintenance plans is the lack of custom naming options for the generated backup files. Each filename is generated automatically, based on the exact time when the file was created. It is not possible to include a custom string that will indicate the backup type in a filename. Date and time are included in the filename by default for both full and transaction log backups. The easiest way to distinguish full backup files from transaction log backups is by extension. By default, full backup files get the .bak extension, while the transaction log files don’t get any extension. This does not affect the ability to restore any of the backup files. Even if the extension is changed to an unknown format, the restore will still be possible, in the case that file structure remains intact.
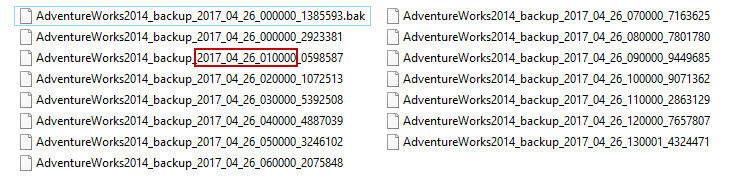
Related links:
May 15, 2017






