



Wait statistics = Data
SQL Server’s built in abilities to track query execution via wait statistics is critical to resolving performance problems. Wait statistics or response time analysis are metrics that provide the ability to measure the time needed for the database to respond to executed queries. It doesn’t simply represent the time needed for a query to complete execution, but the wait statistic is also the measurement of the time the query has taken for each step in its execution. That information becomes the basis for identifying bottlenecks that are affecting the execution time.
Wait statistics are generally more precise for performance optimization than CPU, memory usage or what SQL Server health status, in general. By identifying and understanding SQL Server bottlenecks, their source and cause, via wait statistics it is possible to optimize SQL Server to avoid them and to “reroute” queries to a more optimized execution path.
Generally, there is no need for monitoring all SQL Server wait types all the time but focusing on those with the highest wait time collected during the time. The following query will allows getting information about top 20 wait types with the highest wait times
The wait stats data can be obtained from sys.dm_os_wait_stats Dynamic Management View (DMV).
|
Quick tip: Wait statistics data are retrieved from SQL Server Dynamic Management Views (DMV), but it must be taken into account that DMVs are dynamic objects and all information that DMVs collect will be flushed with every restart of SQL Server. Data obtained via DMVs might not be representative and reliable samples in situations when SQL Server is frequently restarted so using that data should be done with caution during troubleshooting |
The query below uses the sys.dm_os_wait_stats DMV and it will return the top 20 wait types by the highest total wait time
SELECT TOP 20 * FROM sys.dm_os_wait_stats WHERE waiting_tasks_count > 0 ORDER BY wait_time_ms DESC GO
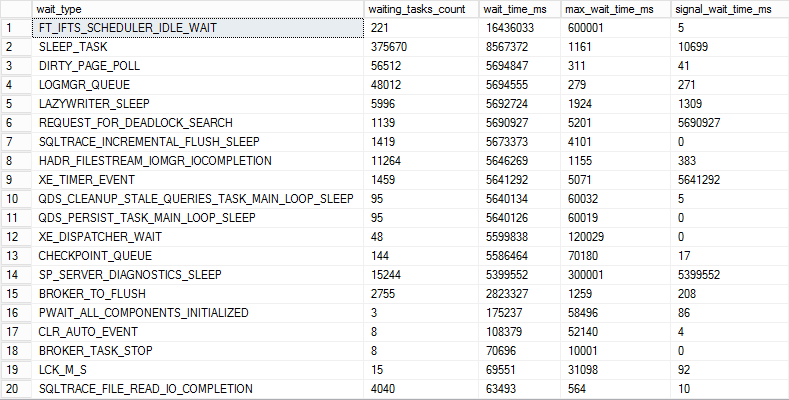
This way we will get the wait stat types with the highest wait time on the server since the last server restart. However, such general information is not always sufficient when it comes to troubleshooting of potential issues as it lacks the necessary context to interpret this data.
Wait statistics + Baselines = Information
To understand and properly interpret the wait statistics for the period of interest, it is important to know what data should be considered as normal, aka the baseline, for a different period of times, especially for some frequent and usual wait types which high values are not unnecessarily indication of an issue (i.e. CXPACKET, SOS_SCHEDULER_YIELD etc.). This additional dimension of time, allows us to transform raw wait statistics into more actionable information.
For example, if the specific wait type has high values every Monday between 2PM and 5PM for the past month or two and the SQL Server was not adversely affected by such high values, that could be considered as normal for that wait type in that time frame. Therefore, it is unlikely that when issue occurs in that time frame again on Monday, that this specific wait type is the cause of the problem. The most effective way to gain an accurate perception of what are the normal values for different wait types during the different periods of time is by establishing a baseline. Baselining wait types data can determine whether the specific wait type data are within the normal boundaries in the specified time period, vs those that are potentially anomalies in that should be further investigated
More information about baselining can be found in the How to detect SQL Server performance issues using baselines – Part 1 – Introduction article and details on how to establish and use baselining can be found in the How to detect SQL Server performance issues using baselines – Part 2 – Collecting metrics and reporting article
Additional resources:
- SQL Server, Wait Statistics Object
- sys.dm_os_wait_stats
- Microsoft Whitepaper on Waits and Queues
- The SQL Server Wait Type Repository…
December 20, 2016






