



In scenarios where a development project of a large scale is being completed, DBA skills can really be put to the test. Due to the nature and the dependencies of the software which is being developed, it’s not uncommon for the DBA to be in charge of dozens of environments, used by multiple development teams working on different aspects of the project. In some cases, this scale of development doesn’t only require for multiple SQL Server instances to be set up across environments – more often than not it requires different versions of SQL Server to be accessible across environments as well
However, the sheer number of databases and SQL instances isn’t the biggest challenge the DBA has to overcome; the biggest challenge is keeping the different versions of the same databases current across environments with as little overhead as possible
In order to cut hardware costs, the best way to go is to set up virtual environment with a lot of virtual machines running on one or more physical servers. Maintaining the servers, while a serious task that can take a significant amount of the day, isn’t necessarily a complicated one, especially since, thanks to PowerShell, a good chunk of the administrative tasks can be fully automated. Furthermore, due to their nature, maintaining the same patches and settings across all virtual environments is much easier than across environments using physical servers
Keeping the objects in the different versions of the same databases in sync can be achieved by introducing a version control system. Keeping the SQL scripts for each database object under source control, under different branches as necessary, will allow any changes made to the database objects in one of the environments to be propagated to the rest with the least amount of overhead and even more importantly – it will allow to quickly revert from an unwanted or a rouge change as the unaltered object’s script will remain safely in the version control system’s repository
However, maintaining consistent data across the environments in an entirely different ball game. Both developers and testers need access to valid business data in order to ensure that the software will actually work once it reaches production. Although it’s possible to generate such data it is a lot of work, as it boils down to extracting specific data subsets from the backups of the production databases. One of the key requirements for the extracted data subsets is to fully represent the business logic; hence, if the business logic changes so do the rules used to extract the data. Therefore, more often than not it’s simply cheaper to fall back to production data for development and testing purposes. Essentially, this means that every time a software component which directly relies on the data is created, updated or needs to be tested a database restore needs to take place
This approach is a rather wasteful one as a SQL Server restores not only take large amount of disk space and time – they also take time to check whether there is enough disk space for the restore in the first place. Such checks can be automated, but since there is no getting away from the physical disk limitations in virtual environments even in those scenarios it’s not uncommon for production of a part of the project to halt until enough disk space is freed in order for the database to be restored. This is where ApexSQL Restore can help
ApexSQL Restore is a SQL Server restore tool which attaches both native and natively compressed SQL database and transaction log backups as live databases, accessible via SQL Server Management Studio, Visual Studio or any third party tool for a fraction of the time and disk space needed for a full restore. It allows attaching single or multiple backup files including full, differential and transaction log backups, making it ideal for continuous integration environments, quickly reverting inadvertent or malicious changes and balancing heavy report loads. For more information, visit the ApexSQL Restore product page
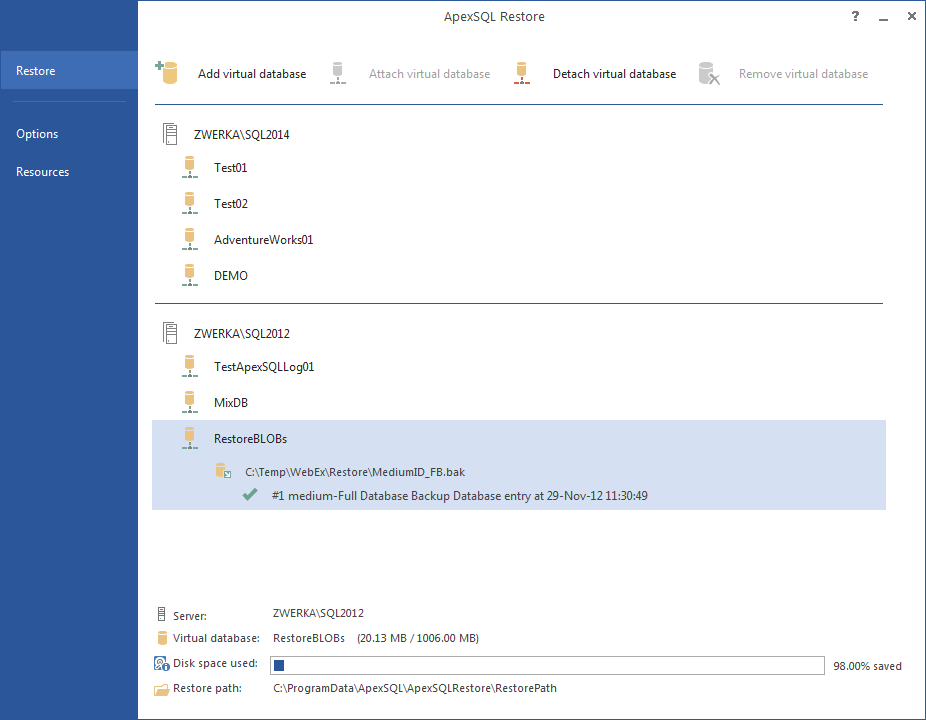
To restore a database backup using ApexSQL Restore in order to save up 99% of the time and disc space need for a full restore:
- Start ApexSQL Restore
- Click the Add a virtual database button
- In the Restore a backup dialog that will appear provide:
- The name of the SQL Server instance the backup will be attached to
- The preferred authentication method; to use SQL Server authentication a set of valid SQL Server credentials needs to be provided
- The name of the database the backup will be virtually restored to
- Click Next
- To specify the backup to be attached click Add file(s)…, navigate to the backup file and click Open
- Review the backup properties and select the appropriate checkboxes next to each backup you want to attach
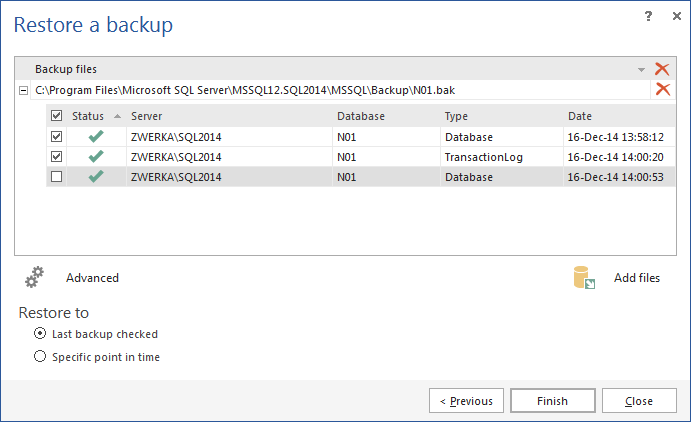
- To attach a different file click Remove file and repeat the process described in step 5.
- To specify a non-default restore path click Advanced >> and specify the path
- Click Finish to attach the backup
In summary, although large scale development projects may seem overwhelming opting for virtualization of the environments the different teams work within and managing the database object changes using a version control system are the best ways to cut costs and minimize overhead. However, when it comes to cutting down the time and disc space costs related to the inevitable database restore – see for yourself what ApexSQL Restore can do for you
April 4, 2013






