



Database DevOps pain points
Traditionally the database has always been the bottleneck for full adoption of DevOps. For a variety of reasons continuous integration and delivery of databases is just harder than client applications. The reasons for this include the following
Data
-
Schema and data duality: The dual nature of databases in that they contain schemas (akin to classes in client code) but also data. Client apps generally don’t have to deal with anything other than trivial data requirements and even for those, they can also just be included in resource, XML or JSON files and included in the build
Data is different than code. It isn’t just a series of instructions. Also the data can’t just be put in a resource file and included in the build, as it is tightly coupled with the database objects themselves. Missing or mis-ordered data can break a build.
- Two types of data: There are two different types of data; transactional data, such a table of orders, and static data, which itself may need to be stored in source control. These different kinds of data need to be handled differently
- Test data: A requirement for test data generation and data masking. When creating a new, temporary database from source control, it will be empty, except perhaps for any static data that was versioned and included in the initial build. The rest will need to be generated, synthetically. This is an additional step/process that simply doesn’t exist in client development
- Data masking: Even if the database is provisioned from production, sensitive data will still need to be masked. Again, a complexity that client developers don’t have to deal with
Schemas
- Destructive changes: Schema changes can require dropping objects, recreating them, and re-applying the data which can be time consuming and high risk. This requires specialized tools that can analyze a database and plot optimal synchronization plans that reduce risk and preserve data.
- Creation order: Unlike in client code applications, the creation order of the database objects matter. Get it wrong, for example, add an object that references another object that hasn’t been added yet and therefore doesn’t exist and this will break your build. This requires a tool that can analyze a database or script for relationships and use that to come up with the correct sequence/order of creation
Tools
- Multiple IDE requirement: Oftentimes developers will use a different IDE for developing script based objects e.g. SSMS, VS and one for designing tables e.g. Erwin.
- Insufficient tools for source control integration: A lack of tools to integrate database development with source control. Database development UIs like SSMS have lagged behind client UIs like Visual Studio by decades, making iterative development integrated with source control difficult.
- Lack of build automation: Even if you have been successful in getting your database development integrated with source control, creating a pipeline to integrate those changes automatically is the next hurdle. Technologies haven’t existed, up to recently, to get your changes from source control, integrate them into a test environment, review, test, document and package those changes. Without that, your database changes are difficult to get to production, at least via a reliable and repeatable means
- Build-server integration: Lack of integration with popular build-servers like TeamCity and Jenkins. Unlike the client development world, there is a lack of plug-ins that would allow direct integration into these systems to support database CI and CD pipeline steps
- Costs: To the degree that some solutions have begun to emerge, the costs are often prohibitively high. One company, for example, requires a full license to its product bundle for every developer in the CI ecosystem, regardless of whether they are directly involved with pipeline construction, development or maintenance or are simply checking in changes to source control and nothing else.
All of these items, and probably many more that I may have forgotten, conspire to make continuous database integration and delivery much more difficult than comparable pipelines for client applications.
Database DevOps solutions
Fortunately, out-of-the box solutions exist to all of these problems, and more, allowing for an integrated solution to SQL Server database continuous integration and delivery
Let’s review each of these challenges, in turn, and provide a solution
Data
-
Schema and data duality
Both of these are critical elements of database continuous integration and delivery and need to be treated as equal partners with robust, enterprise level tools to manage both effectively. ApexSQL offers a one-two punch with ApexSQL Diff, for schema change management, and ApexSQL Data Diff, for data change management. Both are fast, reliable tools with full automation interfaces that lend them perfectly to a DevOps environment.
ApexSQL Diff can compare and synchronize SQL Server database schemas blazingly fast and with high accuracy, ensuring no errors. It has a console application and extensive command line interface aka CLI.
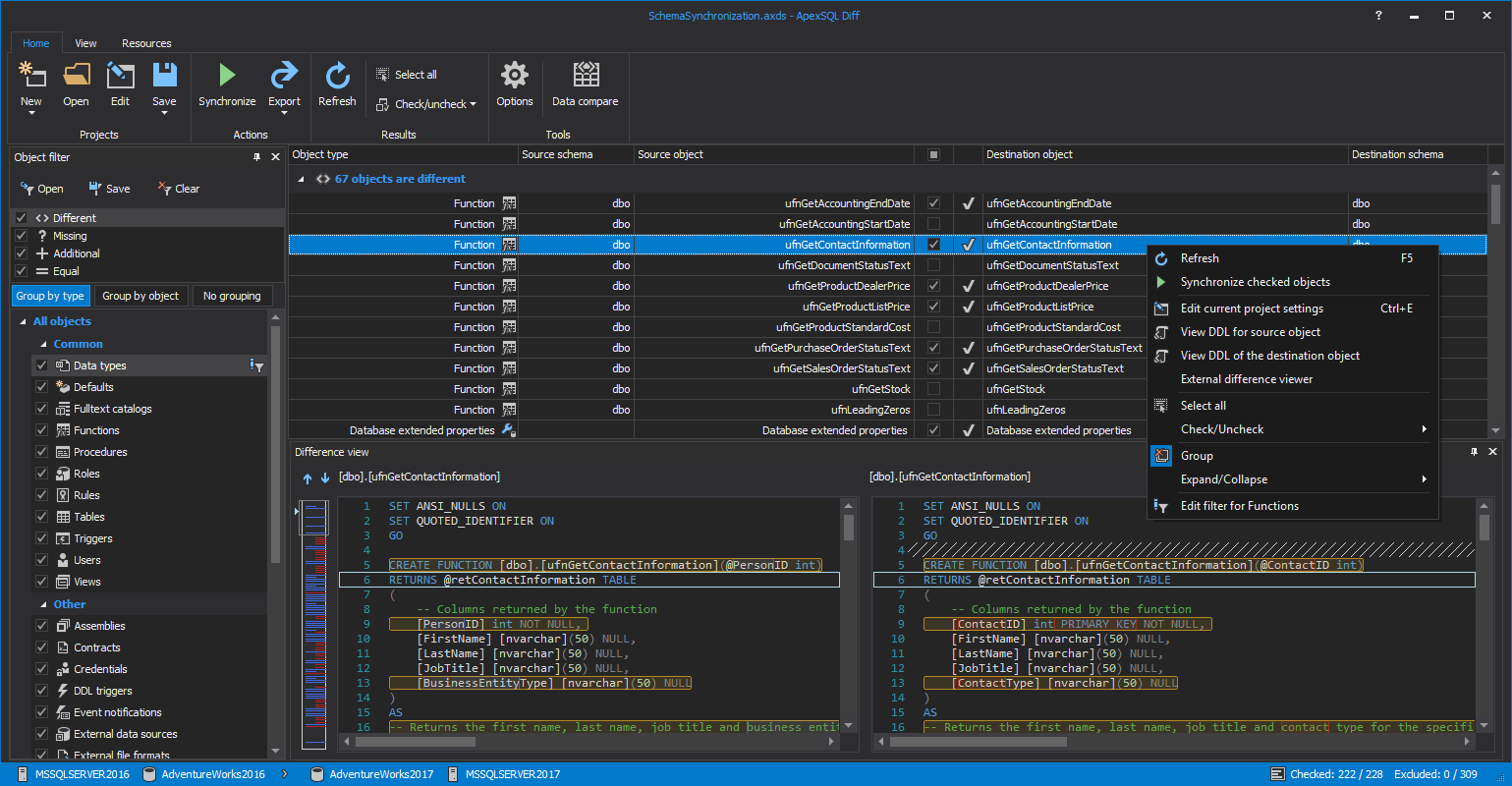
ApexSQL Data Diff performs the corresponding function for data, and in the context of CI, CD can be used to compare and synchronize static data
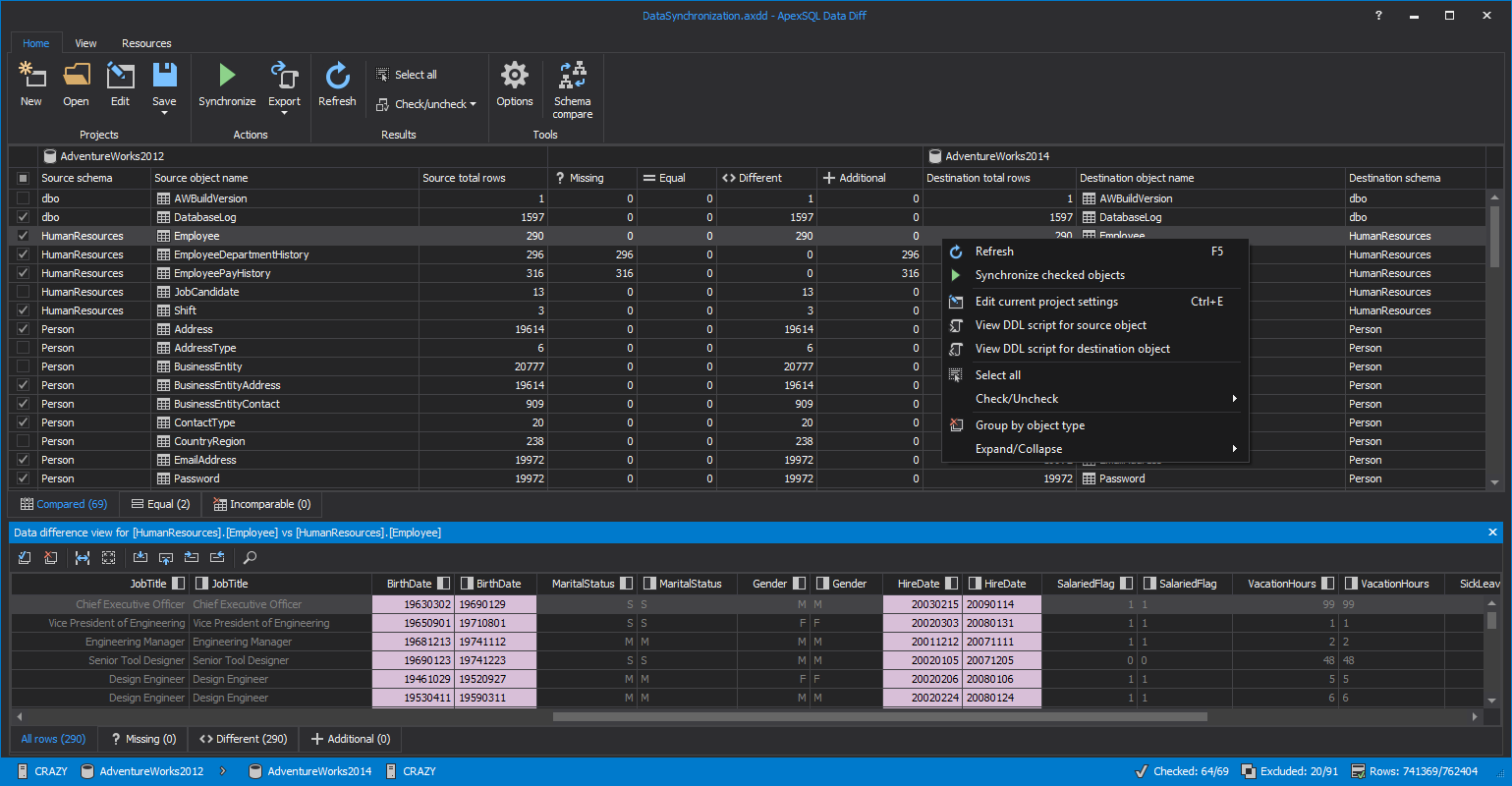
-
Two types of data
Two types of data require two types of solutions.
Transactional data is the essence of your data. It stores all of the information gathered and processed on your database on a day to day, or second to second basis. It is both dynamic, by its nature, which would preclude it from being versioned (unlike static data) and it is also voluminous, making storage in a source control repository impractical.
Not only isn’t transactional data suited for storing in a source control repository, it shouldn’t even participate in continuous integration or delivery processes. The master copy of your data is in production and that is where it needs to stay, untouched.
So why even include it here? We include it because we need data in our test/temporary database for continuous integration, so we can test the build prior to releasing to production.
Two solutions to this include:
- Provision then populate and/or mask: This involves taking a copy, or clone, or your production database and copying it to test and then either filling in sensitive tables, in which data was excluded during the provisioning process or if it was included, masking it
- Populate: This involves creating a test/temporary database directly from source control and populating the transactional tables with synthetic test data that can be made to look as real as your production data
For the provisioning option, there are lots of options using containers like and cloning, like WinDocs and PSDBAtoolsclone. Once copied/cloned data for sensitive tables can be populated, with synthetic test data, with ApexSQL Generate, or masked with ApexSQL Mask.
To populate, all that would be required would be ApexSQL Generate
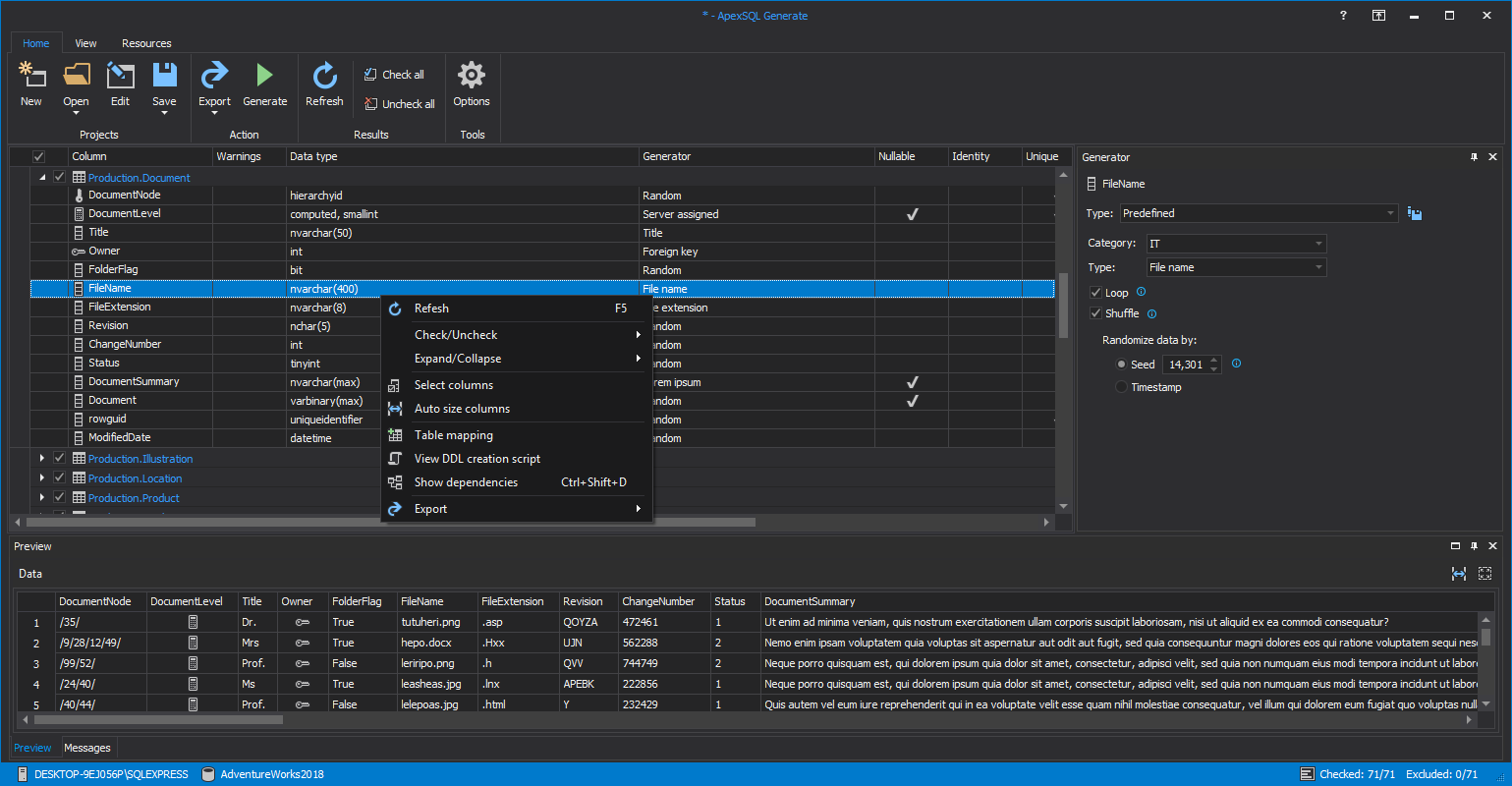
Static data is, as its name would indicate, data that is generally not dynamic, as it doesn’t change much, or at all. Static data is also referred to as code table or list data. An example might be a list of key accounts, models of cars etc. Since static data tables don’t change much and are usually small, they lend themselves well to versioning. Also, by including real production data, it will make testing scenarios more realistic.
ApexSQL tools work well with static data across various integration steps.
- ApexSQL Source Control allows developers to check-in, change and check-out static data, just like the world with objects.
- Static data can be incorporated into the initial build of a test/temporary database with ApexSQL Build.
- And, in the event that any static data tables were changed, the changes can be synchronized to production in the Sync (data) step with ApexSQL Data Diff
-
Test data
The requirement to create realistic, synthetic test data is critical for continuous integration because a realistic test/temporary database should be created with each build, to ensure the changes can be fully tested.
Even if a new test/temporary database is provisioned from production, certain data e.g. sensitive data, personal information can’t be used, and still comply with most data governance rules. If this data is excluded it needs to be re-populated, which is where ApexSQL Generate comes in. ApexSQL Generate can create millions of rows of realistic test data quickly and easily.
If a new database is created directly from source control, synthetic data is even more important as it will be required to populate all of the transactional tables
-
Data masking: Another key pain point is data masking. Provisioning data from production is great but sensitive data can’t be used for testing without violating the confidentiality of your customers and perhaps the law e.g. GDPR. That is where masking comes in. A data masking process can obfuscate the code aka pseudonymise it. This involves identifying sensitive data columns and running a process on them that irreversibly masks the data, such that it can be simply and easily unmasked.
Fortunately, ApexSQL has you covered here as well, with ApexSQL Mask, a tool to intelligently pseudonymise production data to allow it to be used for testing
Schemas
-
Destructive changes:
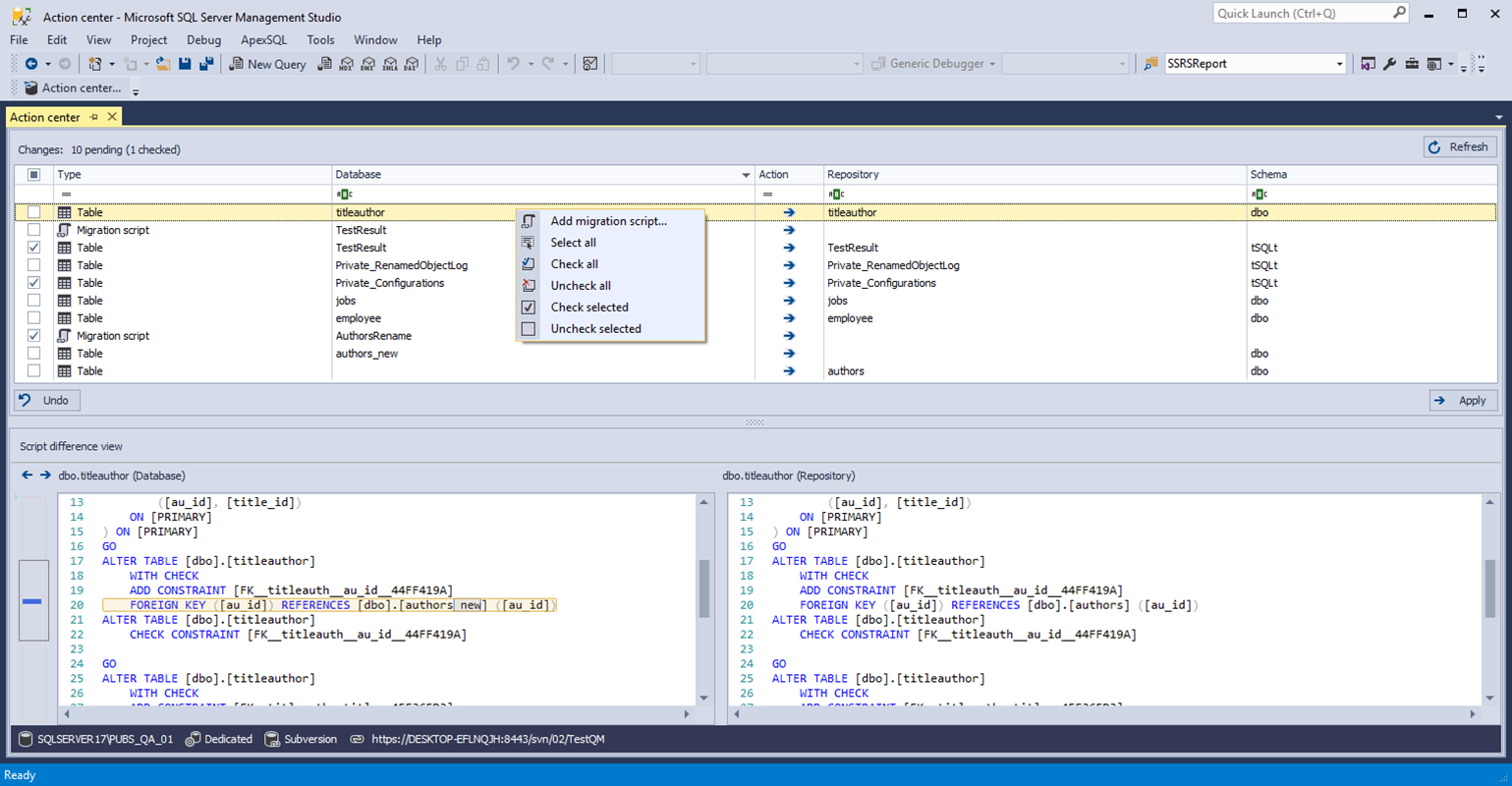
As mentioned previously, database objects just can’t be copied over old versions like EXEs and DLLs for example, because database tables contain data which would be lost. SQL Server offers the ALTER function to change an object without destroying and replacing it but sometimes the change can still break the object, in relation to its data, for example by adding a new constraint for which the existing data would be in violation, or the changes could be so extensive that an ALTER wouldn’t work, necessitating the object’s data being copied, the object being dropped and recreated, and then the data being copied back. This is a very delicate operation and it requires a sophisticated analysis of the table’s underlying structure and the potential change, and the ability to proceed with the change, non-destructively, if possible and if not, raise a warning.
ApexSQL Diff has a synchronization mechanism that can analyze the impact of potential changes and make them in the safest, least destructive way possible. If there is any chance of data loss, ApexSQL Diff can provide a warning and even halt the synchronization process with a failure return code. This will send a notification of why the pipeline failed so it can be re-run, supervised, or the change can be improved or reverted.
-
Creation order:
Another challenge is that order matters. When copying files to a webserver, the order files are copied, normally has no import or consequence. On the other hand, almost every database object has some interdependency that could trigger an error, if it were created out of sequence to other objects it has a relationship with.
A good tool to inspect the interdependencies in your database is ApexSQL Analyze. It will respect and review each relationship and chart them visually. You can drill down to see the potential impact of removing or changing any object
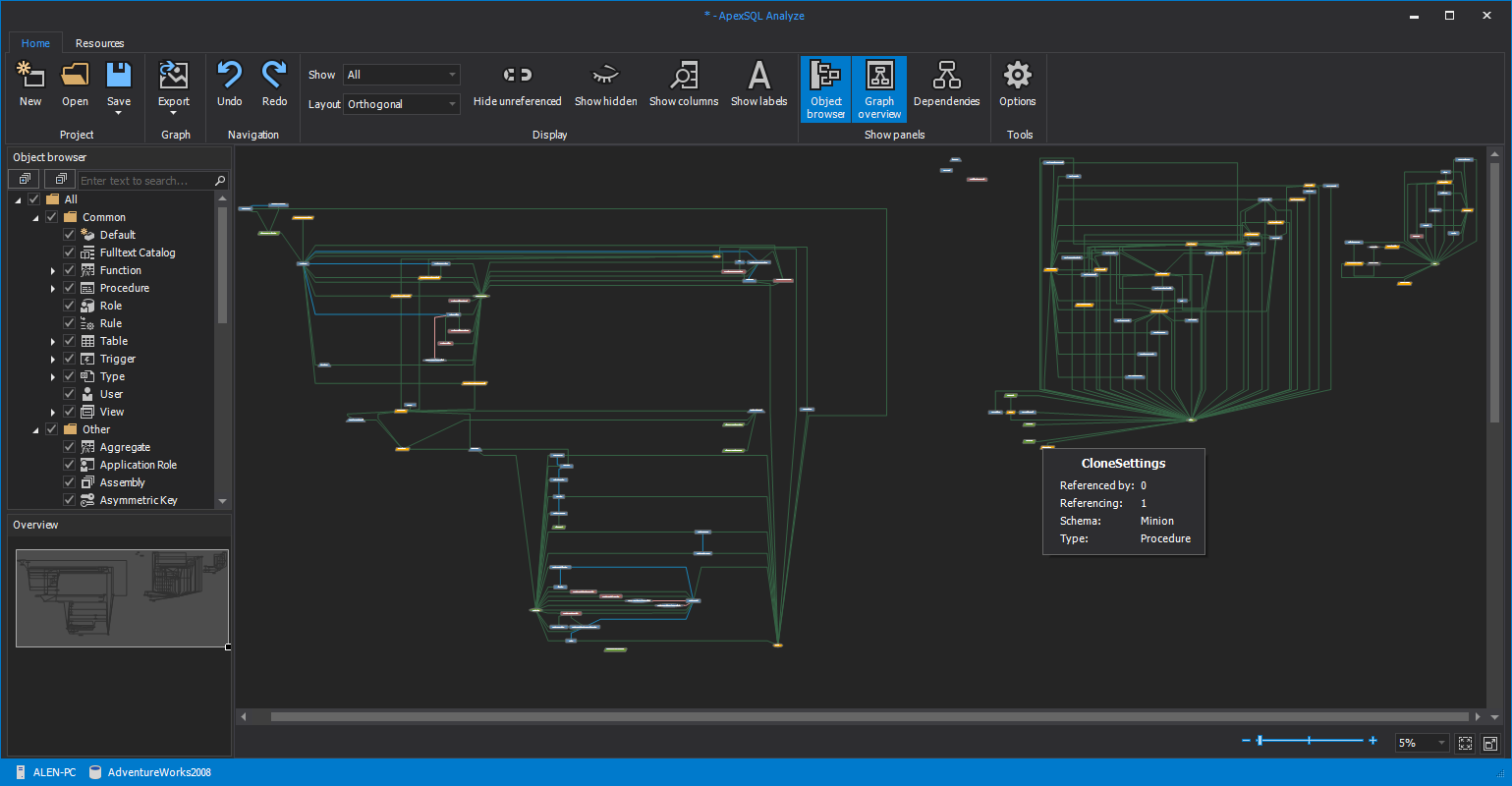
ApexSQL Refactor is a great tool to make risk-free changes like changing the name of a table or even a column in a table. It will analyze the dependencies and create a script that will not only update the object, for the change, but will also update all of the dependent objects to avoid any errors.
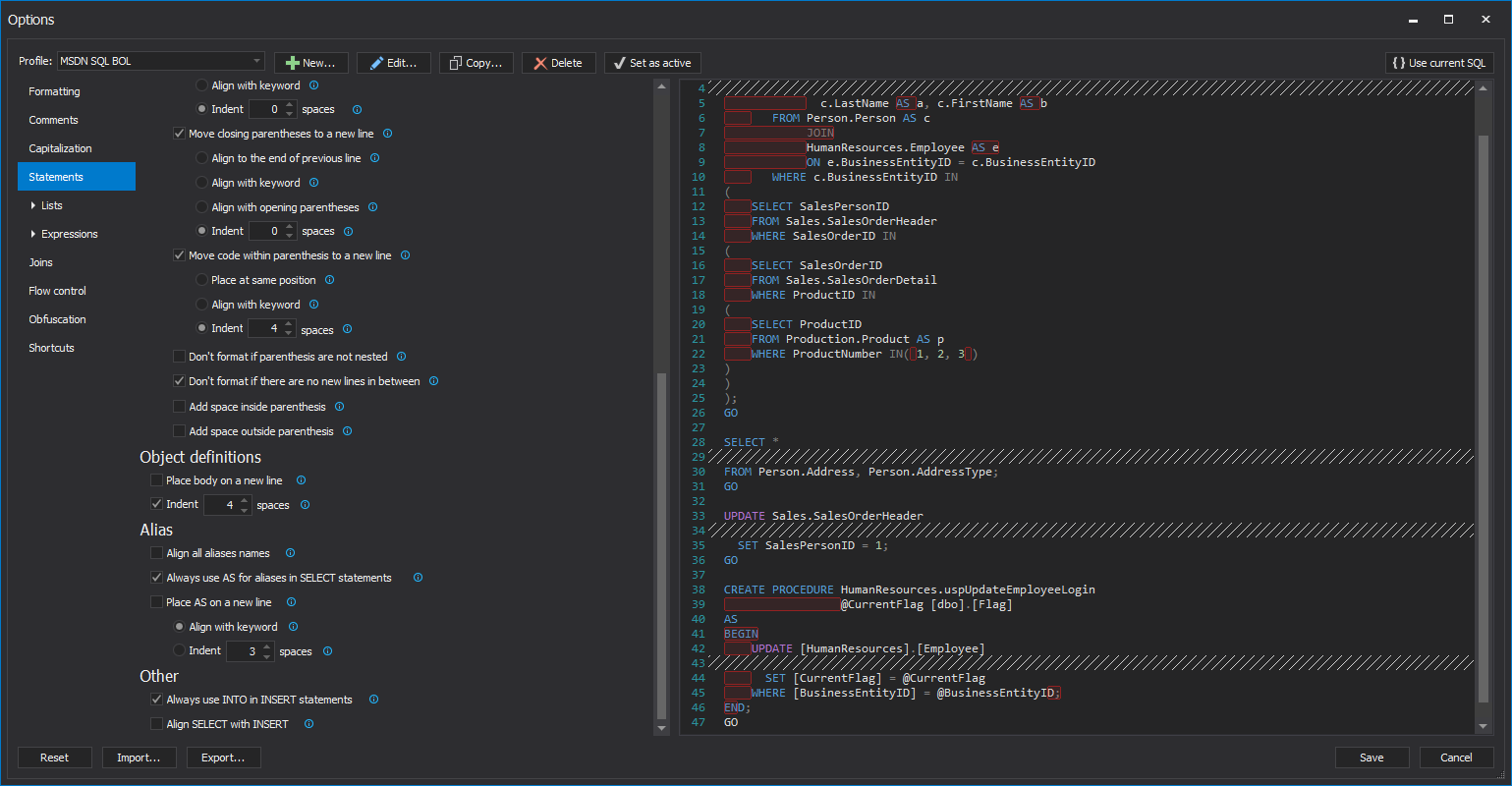
But to integrate this processing into your CI and CD pipelines you can use ApexSQL Build and ApexSQL Diff
ApexSQL Build drives the “Build” step in the ApexSQL CICD toolkit. It creates a database from source control, scripts etc and always processes them in the correct order, avoiding any and all potential dependency related errors
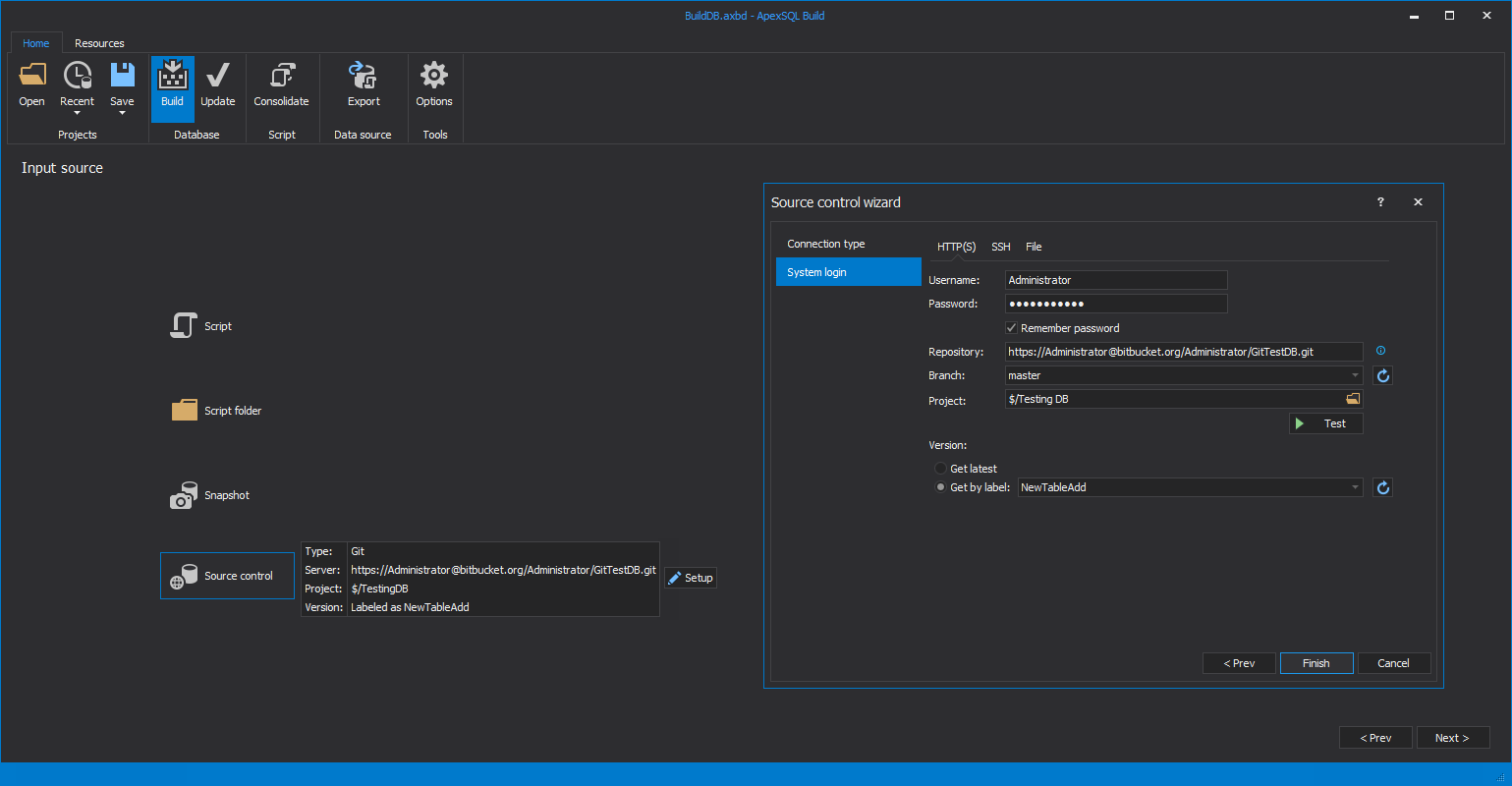
When it comes time to deliver the changes to production, ApexSQL Diff can compare the test/temporary and production environments and create a script to synchronize the changes, again in correct dependency order
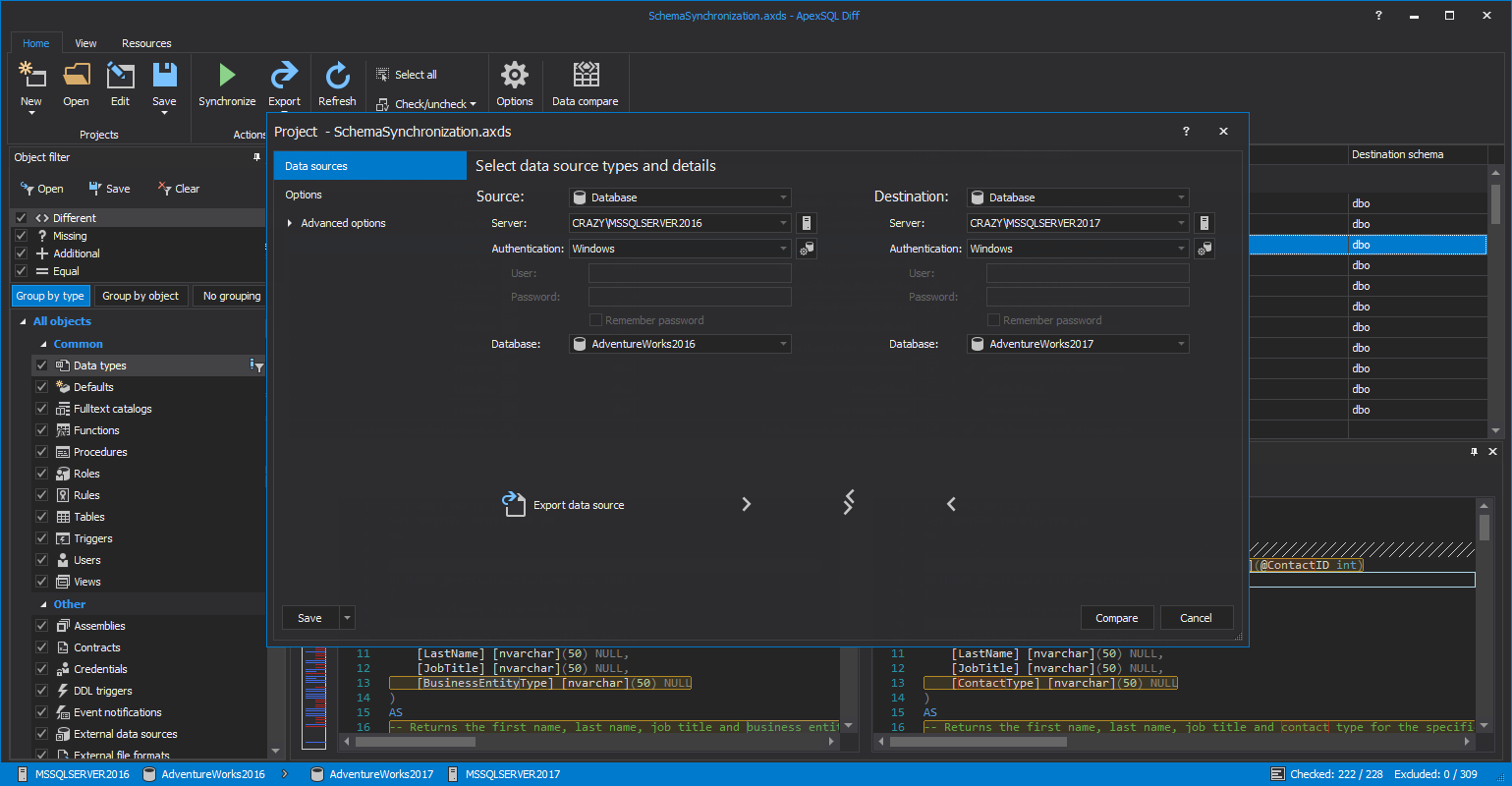
Tools
-
Multiple IDE requirement
Client developers have been blessed with an IDE like Visual Studio for years which allows development in a variety of programming languages. Database developers, due to the nature of coding procedural, script-based objects like functions and stored procedures vs relational, data objects like tables have to straddle multiple IDEs. For coding, an IDE like SQL Server Management Studio or Visual Studio works great. But for designing tables and database diagrams, you really need a tool that specializes in that to do it right.
Fortunately, ApexSQL has tools that can connect these dots. ApexSQL Source Control directly integrates into SSMS and Visual Studio [1], allowing developers to work seamlessly with source control.
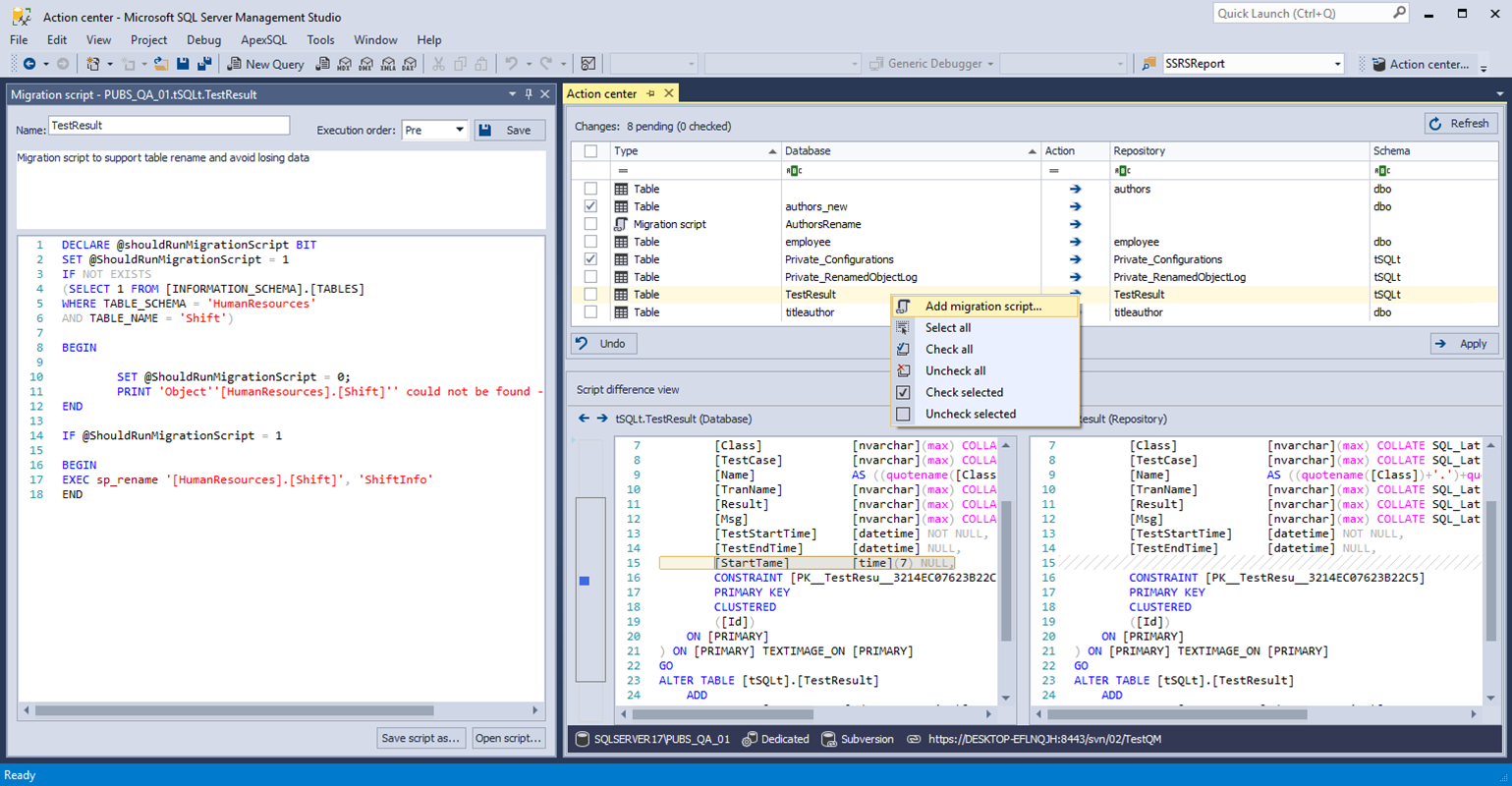
ApexSQL Model [1] provides the same functionality with database modeling, allowing tables, and even the whole model, to be checked-out, changed and then checked back into source control as the same user.

-
Insufficient or under powered tools
Database source control tools have lagged behind their client counterparts for years. Database “Source control integration” has often been under-implemented and difficult to set up and use properly. Often the integrations that did exist didn’t have support for popular systems like Git or Perforce
Today, ApexSQL Source Control offers database developers a first class seat for source control integration via both Visual Studio [1] and SSMS including native integration with all of the popular source control systems like TFS, Git, Perforce and Mecurial. With ApexSQL Source Control you can have all of the popular features like check in/out, locking and development policies that client developers have enjoyed for years
-
Lack of pipeline automation
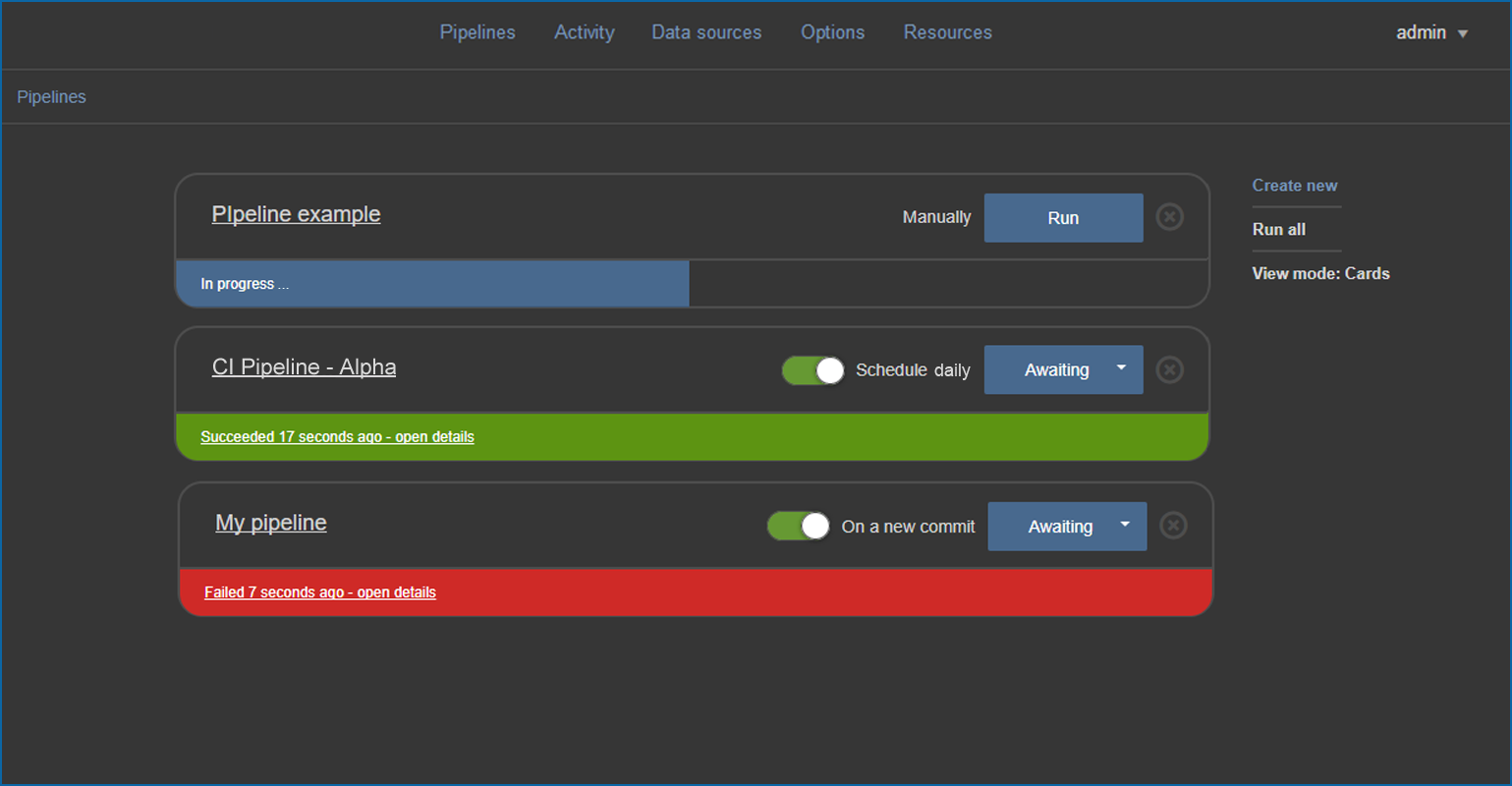
All ApexSQL SQL developer tools have console applications and rich command line interfaces. That allows them to be readily automated and even chained with PowerShell. The ApexSQL CICD toolkit makes this even easier by providing a set of free, pre-written and tested set of open source PowerShell cmdlets hosted on a GitHub repository.

Even better, the toolkit offers a free web dashboard for point and click pipeline creation. Pipelines can be created in minutes and then set to run manually, on a schedule or even on each new commit
-
Build-server integration:
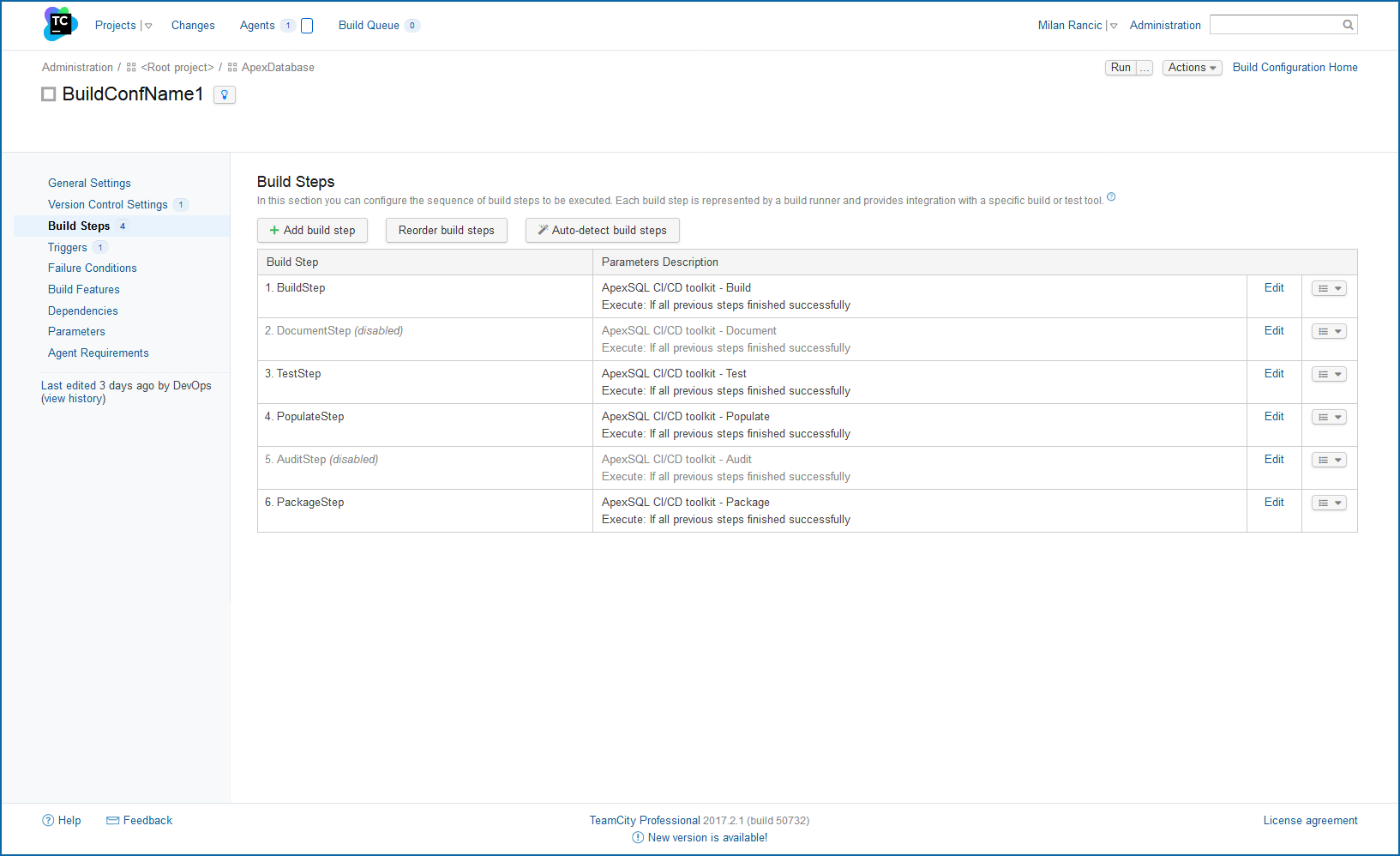
Getting your SQL Server development integrated with source control and even fully automated as part of a CI or CD pipeline is a huge accomplishment. But to create reliable pipelines that can integrate your database DevOps activities with those from other teams, you will most likely need a solution to orchestrate all of these activities.
If all teams use PowerShell, then the cmdlets from the CICD toolkit can just be added to the existing ecosystem. Custom steps [1] can even be added to the CICD toolkit web dashboard to accommodate steps from other team. Or you can integrate the ApexSQL CICD toolkit into your existing environment using one of any popular build servers like TeamCity
Costs
Just because new systems and solutions are emerging, doesn’t mean that they are all within reach. High costs and onerous licensing on all developers, regardless if they are actively involved in constructing and integrating pipelines or just checking in changes, made these systems cost prohibitive for many teams
The good news is that that professional editions of ApexSQL tools only need to be purchased for developers directly involved in automation aka build-masters and the ApexSQL CICD toolkit itself is free, and as for the PowerShell cmdlets, also open source
In conclusion, yes database source control has been a pain point for years, and that doesn’t even include continuous integration and delivery, let alone build-server integration with the rest of your team. But with ApexSQL console applications, command line interfaces and the ApexSQL CICD toolkit, such problems are a thing of the past. You can quickly, easily and cost effectively set up continuous database integration and delivery pipelines in minutes and only pay for the tools you need and the users who will be directly working on DevOps automation.
[1] Feature was not available at the time this article was published
August 7, 2018






