



In this article we will explain how to create a simple batch file to automatically synchronize database schema changes with a source control repository from any individual object changes detected in the database.
Not rich
This wouldn’t be classified as a “rich man’s” approach to database source control management as it
- doesn’t involve direct integration of all development environments between the database and source control,
- can be set up once and run continuously unattended and
- can be managed by a single person
- can utilize free hosting for the source control integration e.g. bitbucket.org.
Not poor
Even so, it wouldn’t be regarded as a “poor man’s” either as this solution does ensure that a database is fully versioned on an individual object level, vs simply backing up the database or scripting the entire schema to source control.
Also, it provides for updating an object’s change history only if there were changes, vs simply updating the repository with every object schema, regardless of whether it has been changed or not. By logging only changes, the history of revisions to isolate specific changes becomes a very straightforward task. If there is a version for every update cycle, isolating a specific change among hundreds or thousands of versions is essentially impossible without additional, specific information about the context of the change e.g. day or week of the change.
And finally, it will require the use of a 3rd party tool, ApexSQL Diff, in addition to the source control system used (in this example Git, which is free was used).
To read an article describing a true “Poor man’s” solution using only native tools e.g. SSMS, scripting (bat files, Power Shell, etc.) and a free source control system, click here.
Summary
This system will automatically compare and synchronize database schema changes with a source control repository, unattended and on a schedule e.g. nightly. The repository itself and any specific objects will be updated, only when changes were detected.
This provides a great “first step” into database source control integration, and can be used as the basis for next steps including, direct integration of source control and database development as well as full continuous integration of changes.
Setting up the task
Before we consider automating anything, we want to prepare and configure a comparison and synchronization job manually. Once everything is set, we can utilize the save project file to re-run the job manually, or easily automate it.
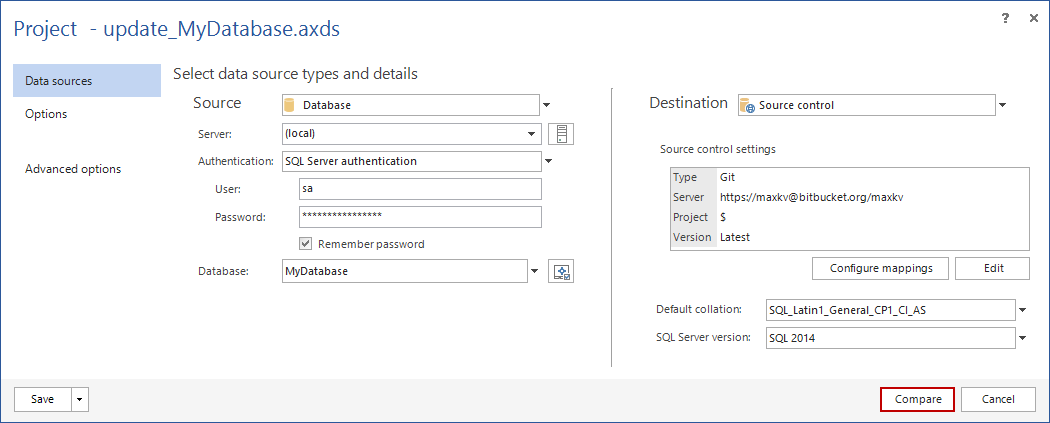
An ApexSQL Diff project file contains the information about the sources to be compared and synchronized. In this case, we’ll provide the path to project file for the ApexSQL Diff CLI as an argument. In this way, the project file will be executed in the same way, as it will be processed through the ApexSQL Diff GUI. To create the project file, start ApexSQL Diff, and in the New project form on the Source side, set a database which changes will be deployed/committed to the repository (in this case MyDatabase from a local server):
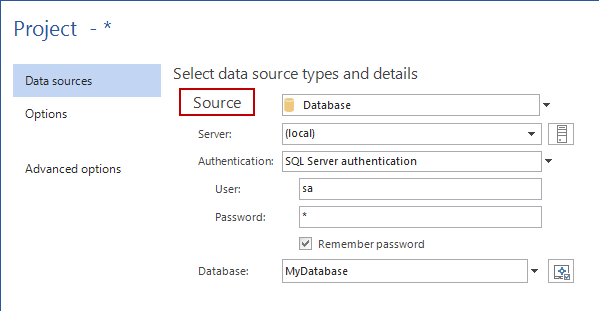
On the Destination side, provide the information about the source control repository where changes will be automatically deployed. To do so, select the Source control option from the Destination drop down list, and click the Edit button:
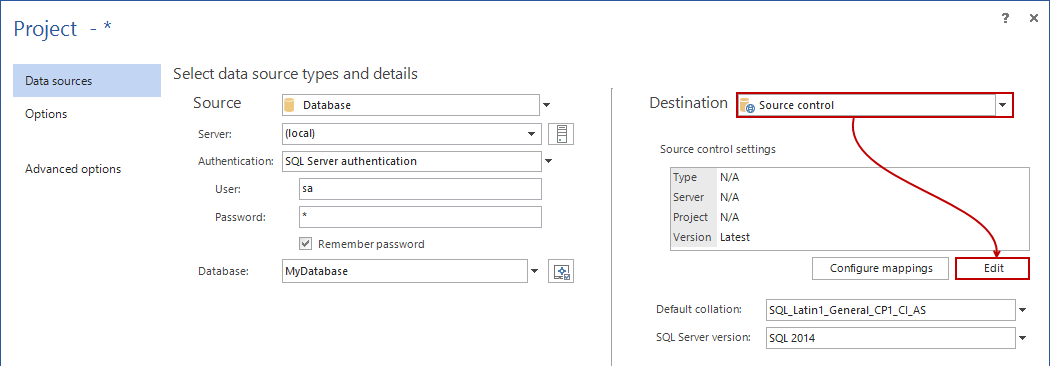
This will initiate the source control wizard. As a starting point, a source control system should be selected from the Source control system drop down list. In this example, we’ll use Git.

The final step is to provide repository credentials, along with the repository path:
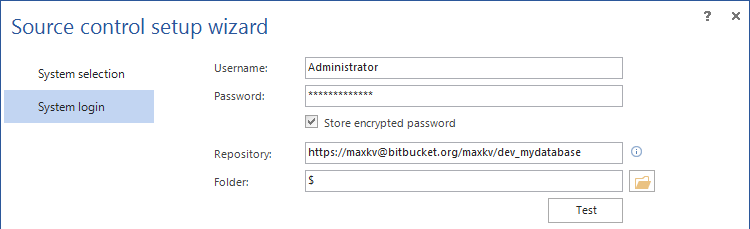
For more information on how to configure ApexSQL Diff to work with source control, please check this article.
Once the project is set, save it, using the Save or the Save as button in the lower left corner of the Project form. We’ll save this project as update_MyDatabase.axds:

Re-running the project manually
Once the project is saved, you can run it manually at any time using ApexSQL Diff GUI. To do so, start ApexSQL Diff, and open the previously saved project using the Open button to initiate the Project management form:
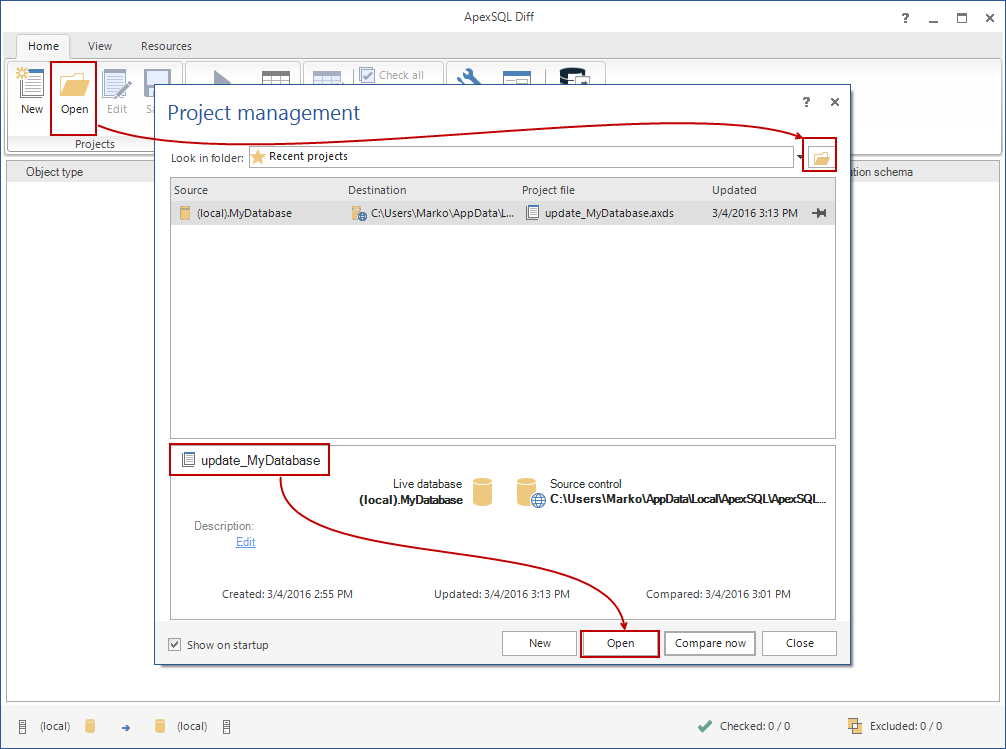
If the project is listed in the Project management form, select it by using the Open button at the bottom of the form. Otherwise, browse the filesystem using the browse button marked in the upper right corner of the Project management form, as shown in the above image.
When the project is opened, the Project form appears with all the prepared settings for the source and destination. We’ll compare these sources, by clicking the Compare button, to check if anything is changed in the database:
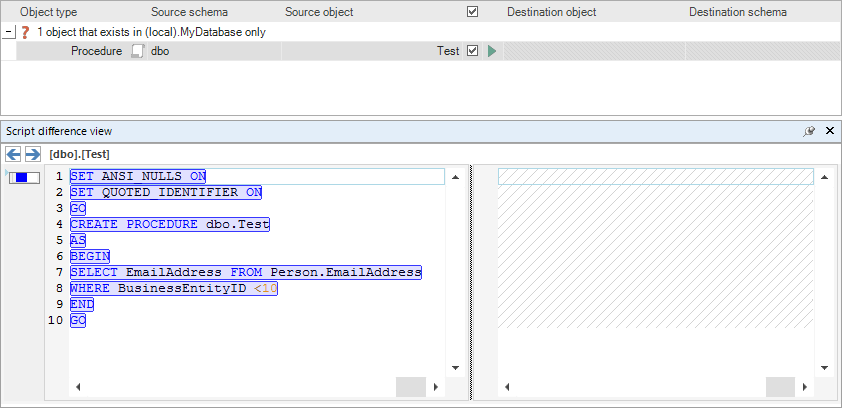
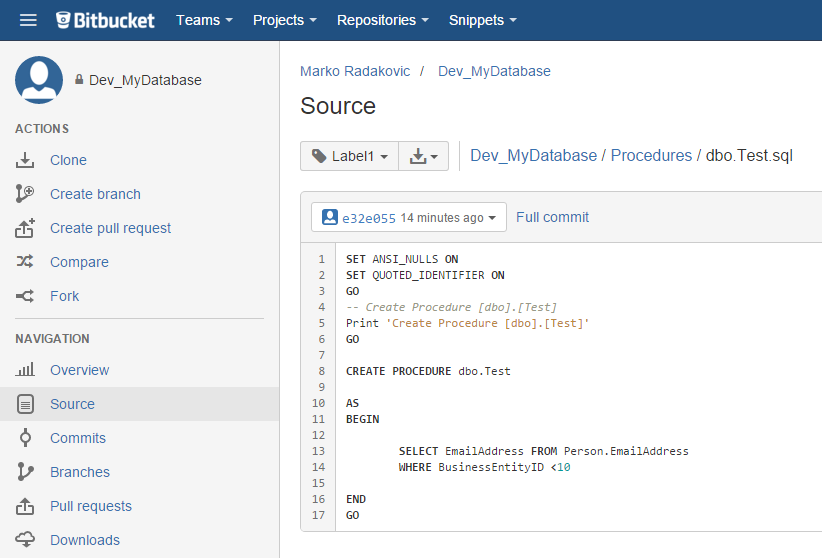
After the comparison is done, results will appear in ApexSQL Diff main grid. For the purpose of this article, we have created a new procedure in the database dbo.Test. The comparison results include a new procedure showing it as a different object:
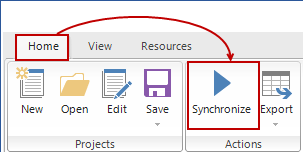
To synchronize database schema changes with the repository, we’ll select the checkbox for the procedure in the main grid, to include it in the synchronization. By clicking the Synchronize button from the Home tab, we’ll initiate the synchronization wizard:
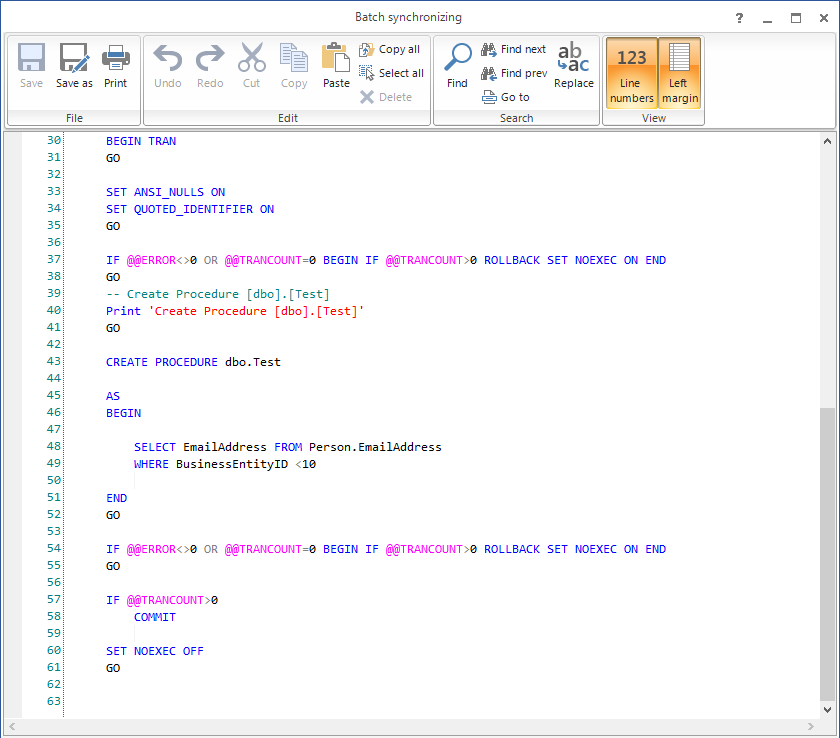
If we choose to create a synchronization script, it will be created as follows:
However, we want this script to be committed to source control, so in the Output options step of the Synchronization wizard, we’ll choose the Update files in source control option:
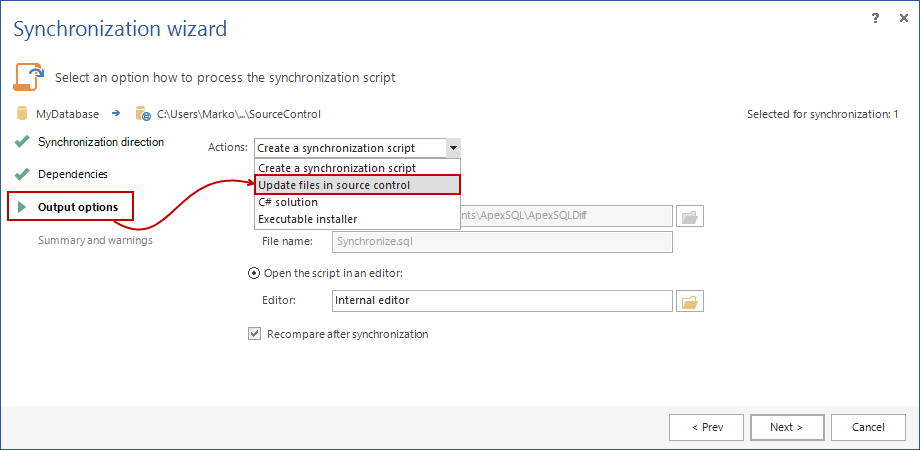
After the confirmation message, all changes (in this case newly created stored procedure) will be committed to source control. We can check the repository, to make sure the selected procedure is properly committed:
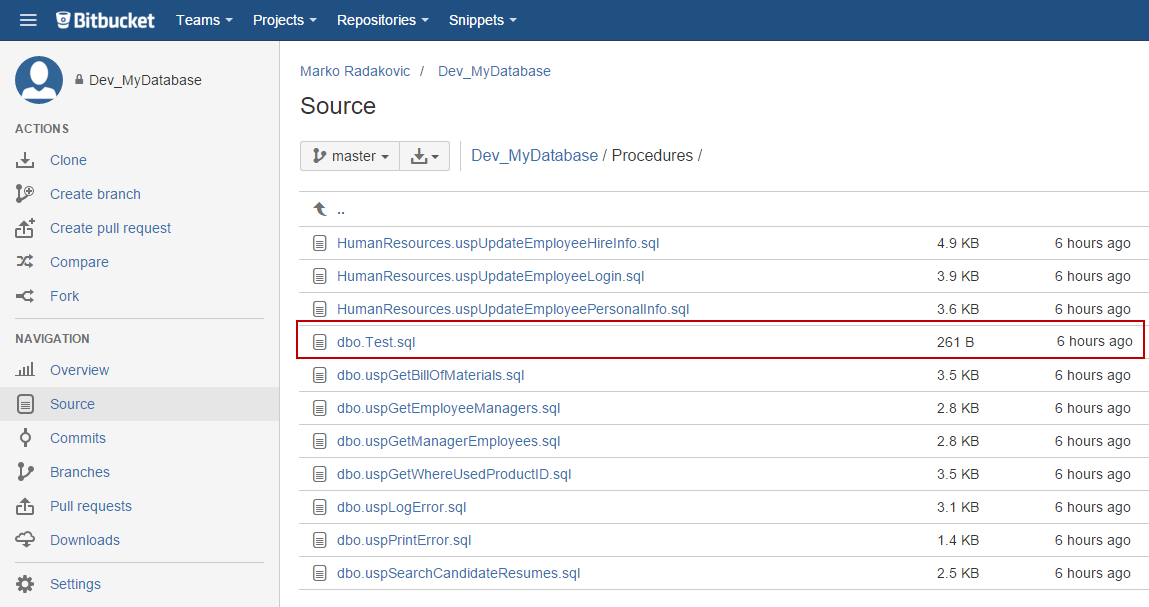
By going one step deeper, we will see the actual sql script of the procedure:
Re-executing a project automatically
As we previously saved the project file as update_MyDatabase.axds, the CLI command that will run the previously saved project file is:
ApexSQLDiff.com /pf:update_MyDatabase.axds /sync
Please note that the /sync switch is mandatory in order to commit changes from the database.
Executing this in the command prompt gives the following result:
ApexSQL Diff 2016.01, (C) 2016 ApexSQL LLC
Version:
Professional edition
Return codes:
0 – success
1 – general error
2 – illegal switch (or combination of switches) is specified
3 – invalid value specified for a switch
4 – error reading/writing data
5 – no permission to perform requested operation
No output format was specified, so T-SQL is being assumed
No output encoding was specified, so Unicode is assumed
Loading Project…
Connecting to (local).MyDatabase…
Connection successful
Reading the script folder: ‘C:\Users\Marko\AppData\Local\…\SourceControl’
Retrieving metadata for $ – Reloading principals…
Retrieving metadata for $ – Reloading data spaces…
……
……
Starting…
Updating the file C: dbo.Test.sql
The synchronization was completed successfully
Additionally, you can execute the following command:
@echo ApexSQL Diff exit code is %errorlevel%
It will throw the appropriate error level code, based on the status of the executed command. If the above command is added to a batch file, the result will be the same, with one additional row:
……
……
Parsing dependencies in MyDatabase…
Starting…
Updating the file C:\dbo.Test.sql
The synchronization was completed successfully
ApexSQL Diff exit code is 0
The last line shows the “0” exit code which confirms the success of the command execution.
Let’s try to mess things up a bit, in order to force a failure. For instance, we’ve added the switch that should create a label on the repository called Label1, but the problem is that Label1 already exists on the repository, and another one with the same name cannot be added. The command is as follows:
ApexSQLDiff.com /pf:update_MyDatabase.axds /sync /scsl:Label1
The result of this command is:
……
……
Parsing dependencies in MyDatabase…
Starting…
Updating the file C:\ dbo.Test.sql
An error occurred while labeling a script folder Source control error: Label with name ‘Label1’ is already exists.
Source control error: Label with name ‘Label1’ is already exists.
The synchronization has failed
ApexSQL Diff exit code is 3
In the last few lines an error message is shown which explains the actual error, another message that the synchronization process failed, and exit code 3 which means that one of the switches specified contains invalid argument. In this case it is the argument Label1 for the /scsl switch.
Process automation
To automate this process simply save your CLI code as a .bat file and schedule it to run unattended. For instance, let’s modify previously created dbo.Test procedure:
ALTER PROCEDURE dbo.Test AS BEGIN SELECT EmailAddress FROM Person.EmailAddress WHERE BusinessEntityID < 20 END GO
The batch file created from the CLI command is as follows:
ApexSQLDiff.com /pf:update_MyDatabase.axds /sync /v /out:C\out.txt
>@echo ApexSQL Diff exit code is %errorlevel% >> C:\out.txt
After executing the batch file, the result is shows in the out.txt file placed on local C drive:
Parsing dependencies in MyDatabase…
Parsing dependencies in MyDatabase…
Starting…
Updating the file C:\dbo.Test.sql
The synchronization was completed successfully
ApexSQL Diff exit code is 0
As shown in the portion of the verbose above, the exact file dbo.Test.sql is updated to source control, the synchronization was successfully, which is confirmed with the exit code value – “0”.
Looking at the repository, we can see that the procedure has been recently updated:
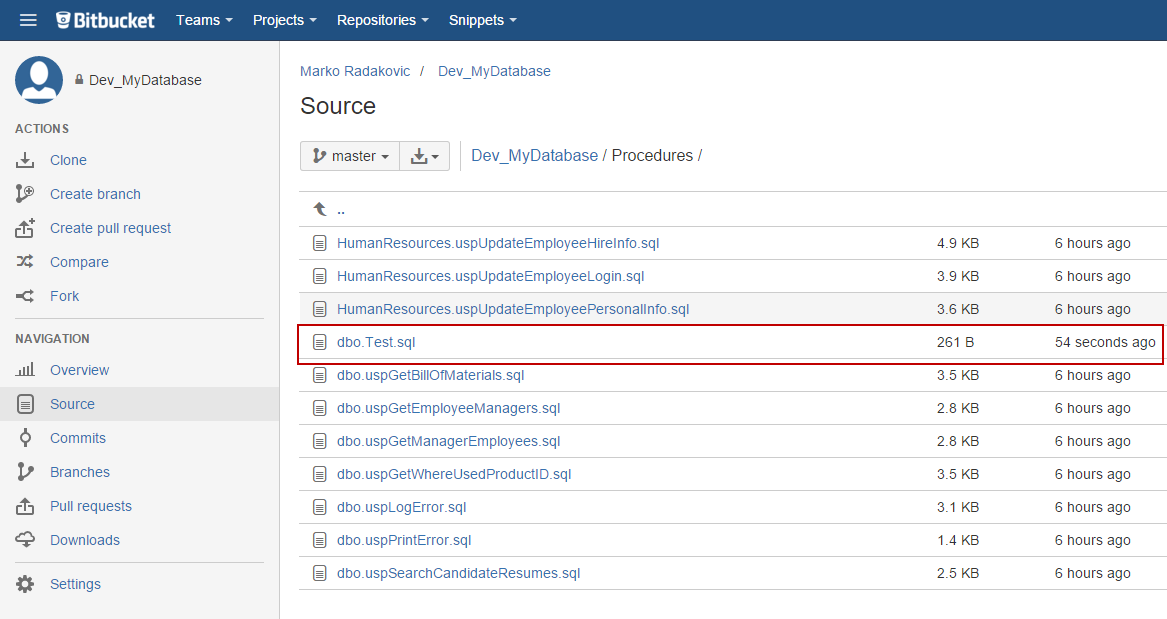
Investigating the particular script, we found that the WHERE clause is updated and contains the newly specified value:
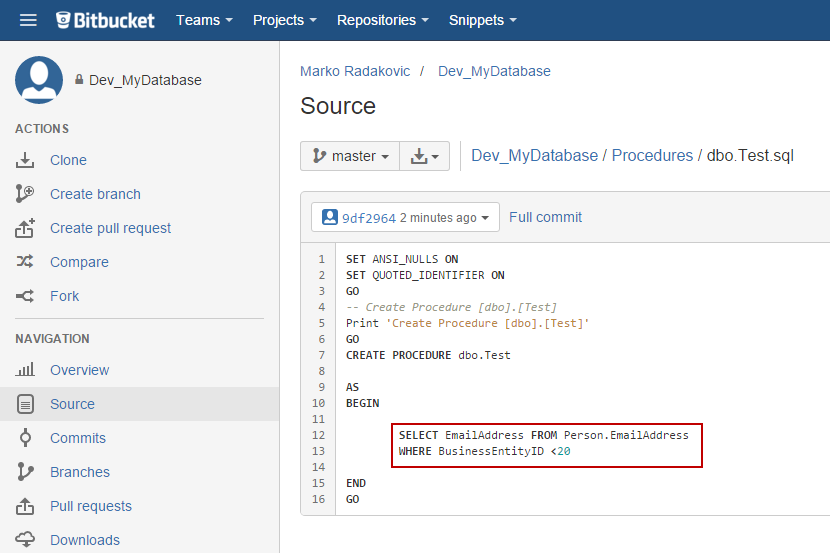
In case of any changes in the database between two executions of the batch file, they will be synced with the repository. Synchronization means that the latest version on the repository will be replaced with the changed object from a database. An older version of the synchronized object will be available through the history on the repository. The rest of the objects which are not changed will not be affected/overridden:
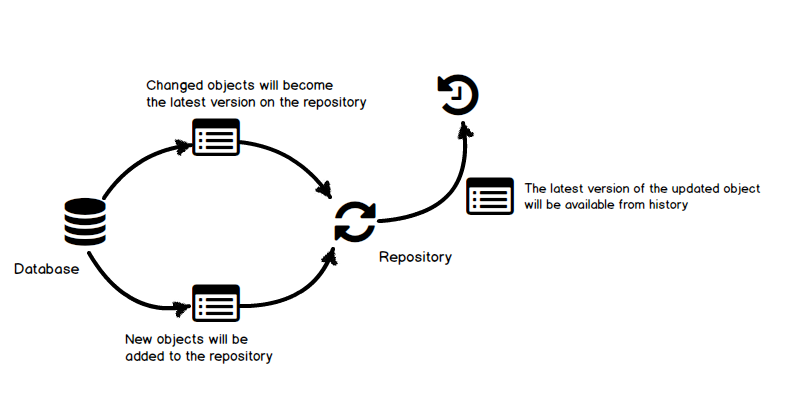
After the batch file is executed, the user can check the repository at any time for any changes. In case there are no differences between the repository and a database, nothing will be committed.
In case a new object is created in the database, it will be scripted and added to the repository. In the similar way, if an object is dropped from a database, during the synchronization process, the latest version of an object will be removed. However, all previous versions will be available from source control history.
In case the user wants to create a label on the repository after each commit, one additional switch should be added /scsl:<Label_name> to the CLI command. Also, each commit can be followed by a specified comment. The switch for the comment is /scsc:”Some comments”, and this switch should be added in the CLI command.
March 8, 2016






