



Challenge
In order to perform any continuous integration or delivery process, an important requirement – to be able to pull out the database (which was previously versioned in source control), automatically and repeatedly, to recreate the database in a QA environment at a click a button (or scheduled on a commit).
The important thing is to pull out the database in the correct order of parts in which it exists in source control:
- The database creation script – e.g. Database.sql
- The individual database objects creation scripts – e.g. CustomerList.sql
- Static data scripts, one per table – e.g. CustomerList_Data.sql
Regarding this order, the first thing that needs to be done is to pull out the database creation script and execute it against a SQL Server, creating a database.
The next thing is to pull out all of the individual database objects creation scripts and execute them in the correct order – this is required to avoid dependency errors. An example of a dependency error is when a stored procedure A contains a dependency to another procedure B, but that stored procedure B doesn’t exist yet, because it hasn’t been created when stored procedure A is. The creation script for stored procedure A will raise an error because of the missing dependency.
In the final step of building a SQL Server database from source control, static data scripts should be pulled out from source control, and executed, so that all static tables will be populated with data.
Solution
ApexSQL Build is a 3rd party tool, designed for building SQL databases from various inputs. It is well suited for the Build step for any SQL Server database continuous integration process.
ApexSQL Build has options to:
- Be configured and have the settings saved for future iterations via a project file
- Be fully automated via a Command line interface (CLI)
- Run unattended on a schedule
- Process all objects in correct order to script execution errors
- Preview all of the action steps prior to execution
- Produce a job summary to file for a complete audit of the job
- Import, reference and/or create a Create Database script
- Return a code for success or error to a calling process or application
- Follow the order in which scripts exist on the source control and pull them out in correct order
Configuring the project
First, the job will be designed manually, via the GUI of ApexSQL Build. It can be done by following these steps:
- Run ApexSQL Build
-
Click the Build button under the Database section from the Home tab:
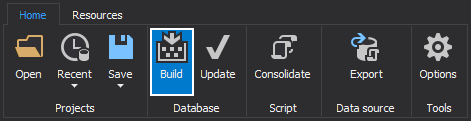
-
Choose Database in the Output type step:
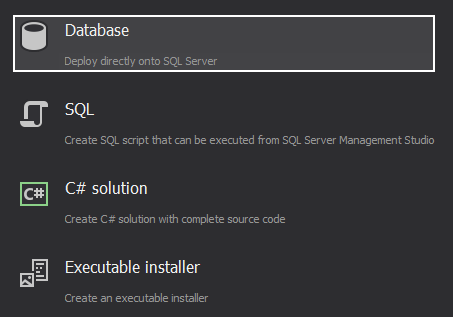
-
Select Source control as an Input source (database has been versioned in a source control repository), and click the Setup button to set the source control repository options:
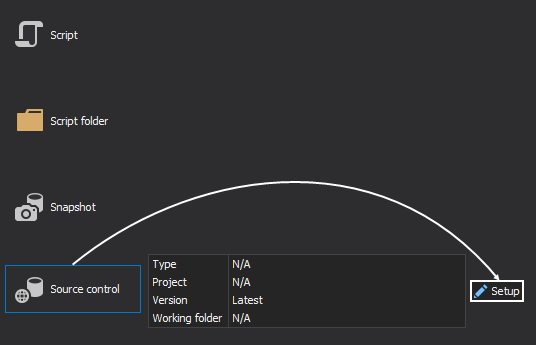
- Set configuration for source control. In this example Git will be used. For more information on how to set up a repository in Git follow this link.
-
Enter SQL Server name and authentication way in the Connect to SQL Server step, where a database will be created:
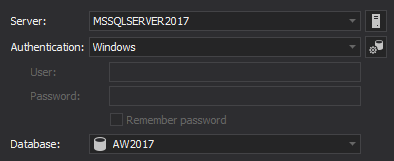
- Configure the tool to create the new database. Three scenarios are possible in this case:
-
A script for the database exists in the repository itself e.g. Database.sql. In this case, just specify the details for the target SQL Server, and select the From source control as an option for creating the database:
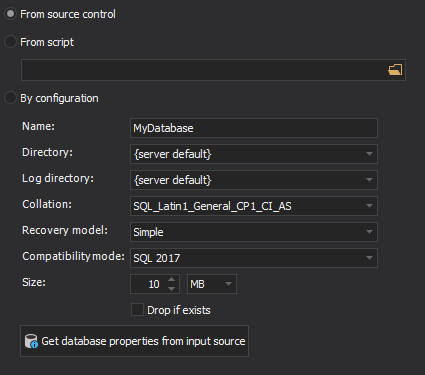
-
In case the database script isn’t in the repository, but it does exist locally on the machine, the script can be loaded into the application by selecting the From script option and then choosing the script file from folder:
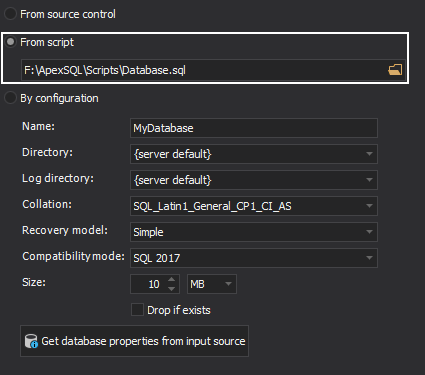
-
If no script exists in the repository, nor in some file locally, one can be created from within the application itself, when the By configuration option is selected:
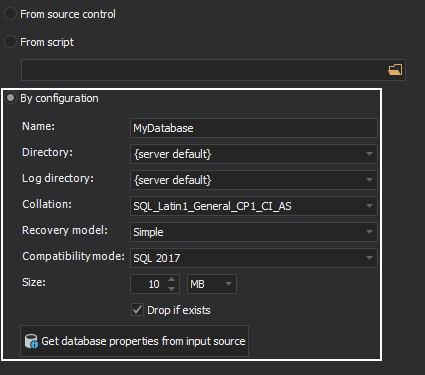
Here, instead of specifying all database properties, those can be loaded with a click on the Get database properties from input source button.
The Drop if exists option, which when checked, will drop the existing database of the same name, before creating the new database creation script.
-
-
In the Build objects step, objects can be selected to be included in the build. All objects pulled out from the source control will be presented, and selected by default:
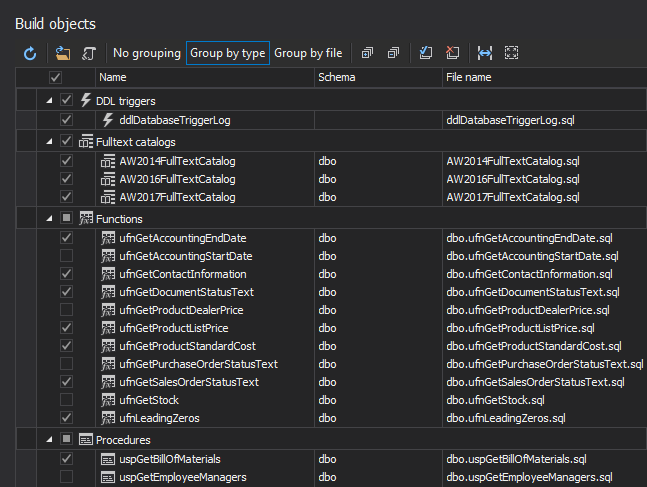
-
The Preview step shows the summary of all actions that will be taken while executing the build script:
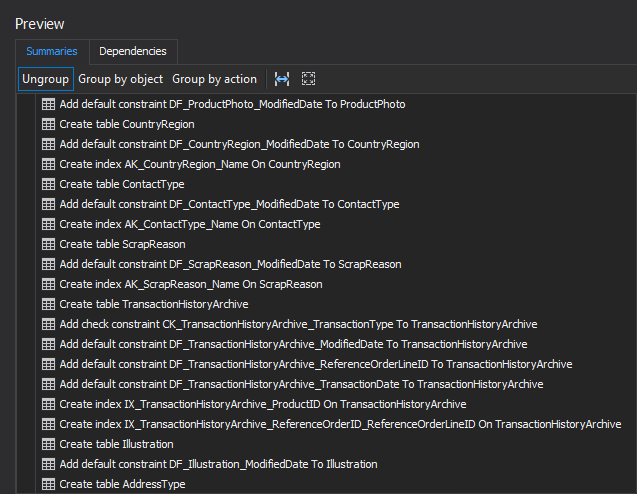
-
The next step in the process of building a SQL Server database from source control is to include static data. In order to include static data, ApexSQL Build has an option, which is checked by default, under the Script tab in the Options window, from the Home tab:
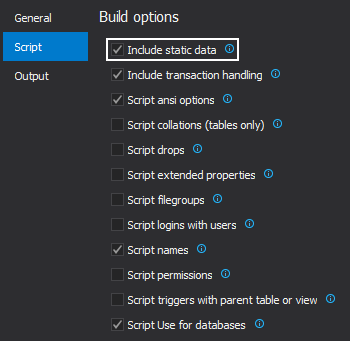
The Include static data option, when checked, collects all static data, that exists in the source control repository, associated with selected tables, and includes them in the build process.
-
When this option is checked, the Static data window will be presented in the wizard where the user can see the static data files, which will be included in the database:
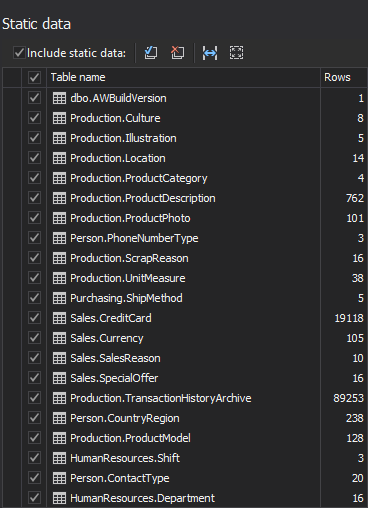
-
The Post deployment scripts step offers an option to add scripts which will be executed after the database has been created (this is optional and it can be skipped):
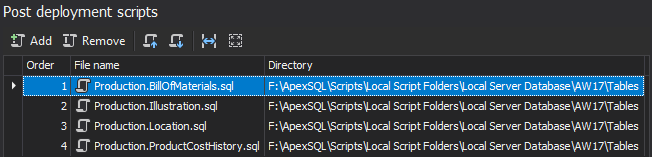
-
The Output options step is the last step in the database creation process. In this window under the Script tab an output action can be selected – such as Save a copy of the script:
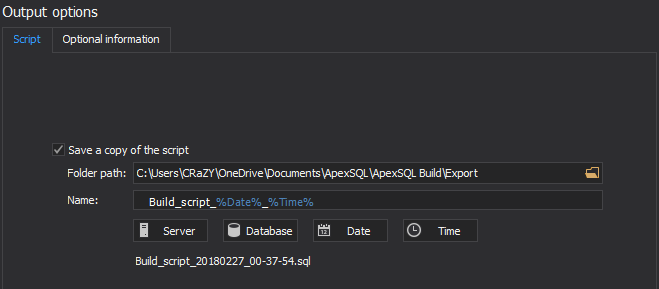
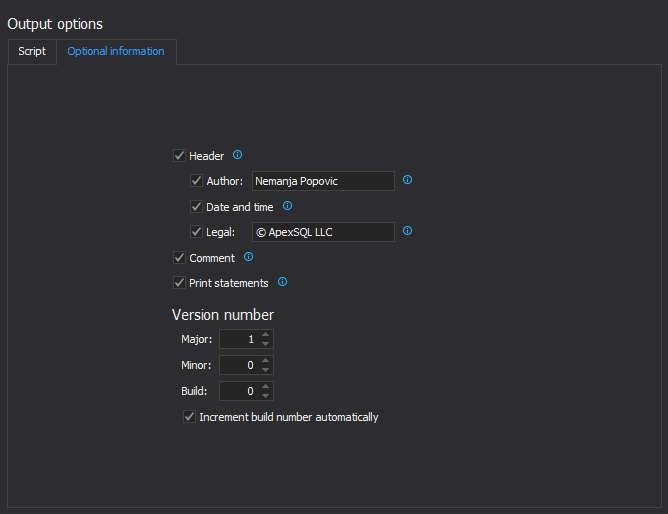
In the Optional information tab version options can be set – which can be useful in the continuous integration workflow build step, along with an option to insert header, with its options, to the build script:
After everything is set, save your project by clicking the Save button from the Home tab:
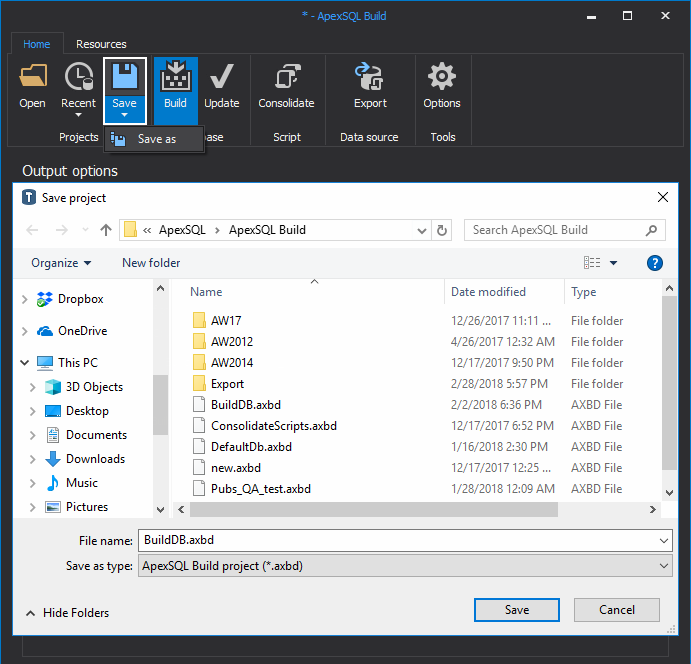
After this whole process has been saved in a single project file, it can be run on demand whenever is needed to recreate SQL Server test environment.
-
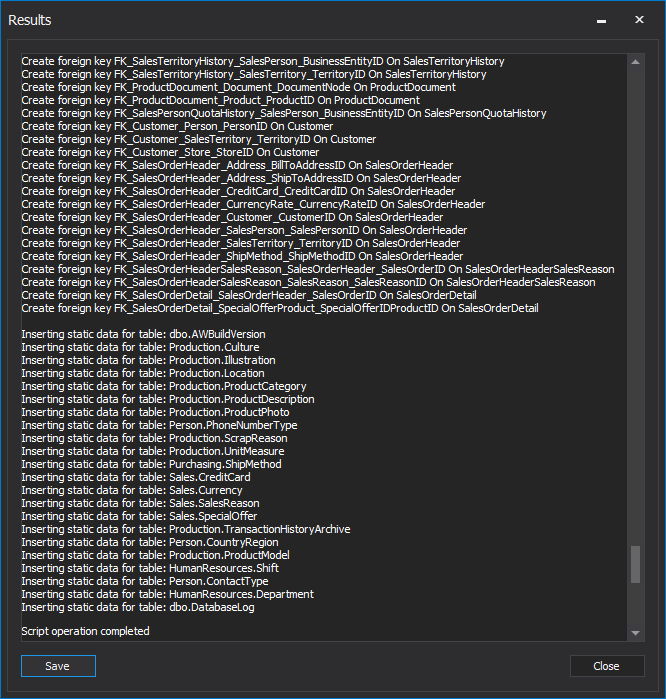
After clicking the Finish button, the entire database will be built from the source control, without writing a single line of code. After the database creation process has been done, in the Results window will be shown if the process was successfully finished, or with errors:
Automation
Automating this process to run on a schedule, unattended, can be performed to make this process repeatable. This can be accomplished with a small PowerShell script.
This type of scheduled project should include the following:
- Start time and the frequency should be defined for the task
- The task name should be provided along with the path to the task
- An output type should be provided for the called application (ApexSQL Build)
- Return code should be provided by the called application when the execution process is finished
The PowerShell script will include the following elements:

Note that PowerShell project can call and execute the application’s CLI code only if it is under the single quotation marks, and if the code is written in single line.
For more information about using the ApexSQL Build via the CLI check out the article about ApexSQL Build Command Line Interface (CLI) switches.
The project file previously created in the ApexSQL Build contains all needed information including the passwords, which will be saved and encrypted in it. Learn more about using the project file in the CLI.
In this example Windows authentication was used, but you can learn more from the article about Four ways of handling database/login credentials during automated execution via the CLI
After an execution of the PowerShell, all execution messages will be visible in the output file which is similar to the Results window explained earlier:

In case that some error occurs while the execution process is running, an appropriate return code will be shown in ApexSQL Build.
Each alteration in the source control repository will be applied in the process and accurate order for the execution will be provided, regardless of using the project file or individual switches.
March 10, 2017






