



When it comes to monitoring SQL Server performance, there are a few native SQL Server solutions that provide out of the box performance monitoring. We have written about some of them here: A DBA guide to SQL Server performance troubleshooting – Part 2 – Monitoring utilities.
The problem comes in when you aren’t able to constantly actively monitor your systems. For example, if you experience a performance spike while your monitor is unattended, and this ultimately results in a system slowdown or failure, your systems were essentially unmonitored. If certain metrics like disk space usage hit a critical point, during off hours, vacations, holidays, etc., similar consequences can occur. So, unless you can actively observe them essentially 24×7, you risk monitoring gaps that could result in system slowdown or even failure.
By setting the alerting properly, you can be allowed to passively monitor your systems while proactively getting alerts.
SQL Server Alerts
Alerting in SQL Server is available via Alerts. This feature allows you to be notified when the metric reaches a specific threshold value. SQL Server Agent can send messages, launch applications, or execute tasks if an alert is triggered.
To configure an alert:
- Start SQL Server Management Studio
- Start SQL Server Agent if it’s not running
- Open the SQL Server Agent node and right-click Alerts
- Select New Alert
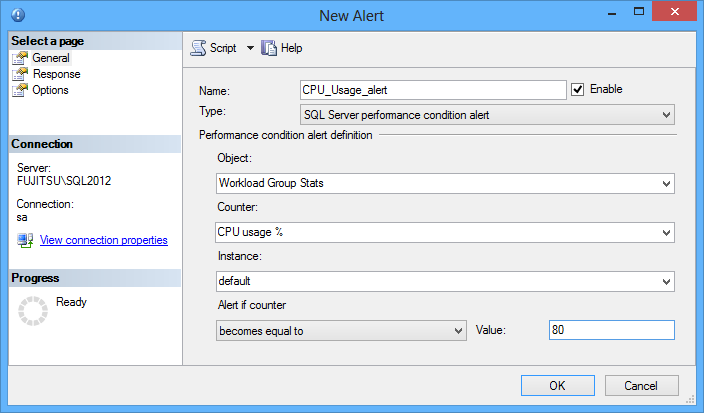
- In the General tab of the New Alert dialog, set SQL Server performance condition alert as Type
-
In the Performance condition alert definition section, specify the performance metric you want to be alerted for and the threshold value
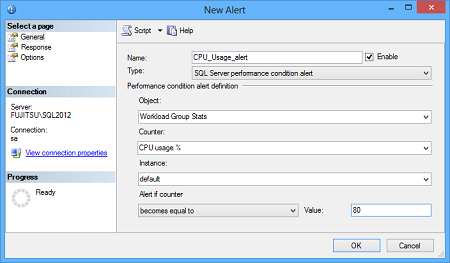
-
In the Response tab, select whether you want to execute a SQL Server job, or send a notification by email, pager, or net send. The latter two options will be removed in future versions of SQL Server
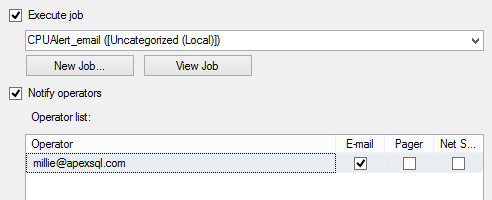
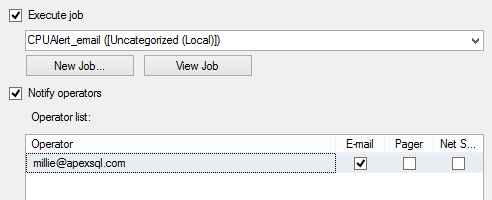
Note that for sending emails, Database Mail in SQL Server Management Studio has to be configured.
SQL Server Alerts provide a mechanism to be proactively notified of any performance issues on your SQL Server instance. They provide granular configuration of SQL Server performance metrics and multiple actions for each triggered alert.
For each metric, you can set different threshold values and actions. However, to do that, you must create multiple alerts, as a single alert can have only one threshold value.
Although the dialogs are self-explanatory, setting an alarm requires a number of steps. For a large number of alarms and several threshold values for each, this can be very time consuming. Reviewing, modifying and purging them can also be time-consuming.
Some metrics cannot be configured at the SQL Server instance level, you have to configure them for each database, even if the threshold values is the same for all databases. If the SQL Server crashes, you will not be notified that something went wrong and might think that there are no performance issues.
As Alerts are based on SQL Server Agent, the feature is available only in the Enterprise and Standard editions. The performance metrics for the system performance are not available.
November 9, 2017






