



The article How to detect whether index fragmentation affects SQL Server performance explains how and in what cases the Index fragmentation affects SQL Server performance, and when a DBA should and should not have to deal with fragmented indexes. This article will deal with the situation when Index fragmentation affects SQL Server performance and has to be dealt with
There are two approaches to SQL Server index maintenance to fix the index fragmentation – REORGANIZE or REBUILD commands. SQL Server index maintenance is an expensive operation performance-wise, and it must be planned and executed carefully, especially in situations when dealing with large indexes. Therefore, it is important for acquiring an understanding of index maintenance and how it can affect SQL Server performance, to learn how indexes work in the background and the data structure behind SQL Server indexes.
SQL Server index structure
SQL Server stores indexes in the disk using the data structure format known as the B+tree (not to be mixed with B-tree, which isn’t the same format). The B+tree is hierarchical structure that consists of 3 segments (levels) – Root, Intermediate and Leaf.
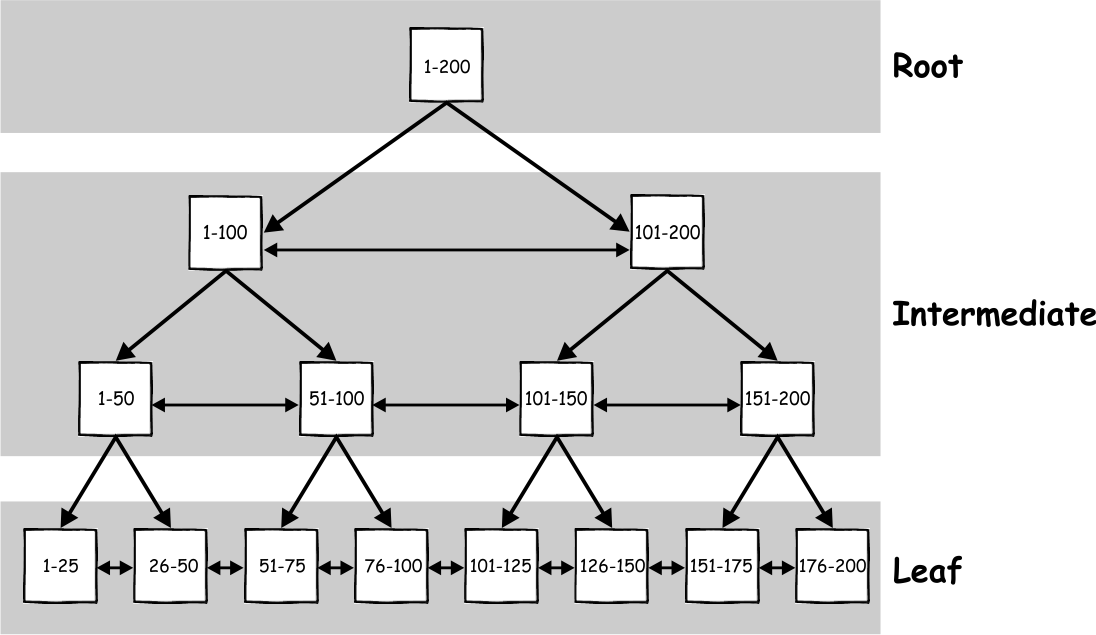
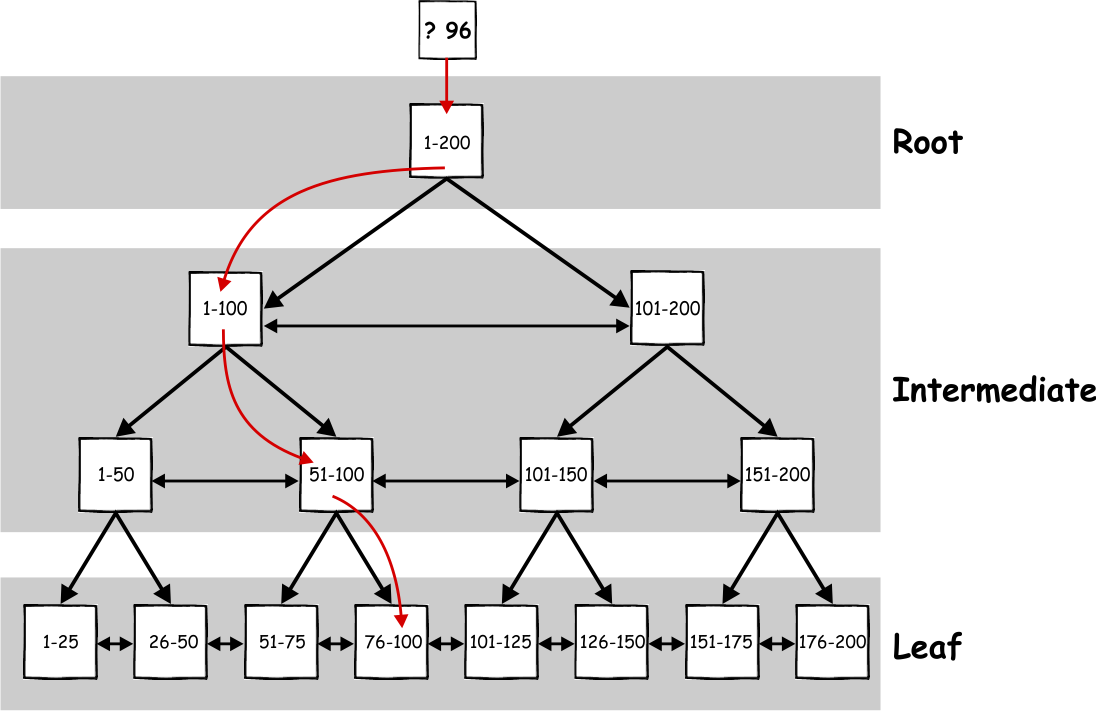
In the B+tree index structure, all of the data is hosted in the leaf pages, while the key values and pointers are hosted in the root and intermediate segment. Also, the B+tree index structure has some pointers that are used to point to the previous and next page at the same level. Thanks to this structure, a query can perform index scan in one direction, from root to the leaf without a need to go up and down between the segments to locate the result. For example, if a query is issued with a predicate WHERE Id = 96, it will start at the root where the adequate page will be referenced in the intermediate level. In the example above, the first page references values between 1 -100, so it will go from root to that page. That page will reference the second page in the next intermediate level (51-100), and from there the query would go to the leaf node page (76-100) for value 96
Knowing this will help understand what the REORGANIZE and REBUILD commands will do. The REORGANIZE and REBUILD commands perform their job in a quite different way and with different effects. Commands themselves are not subjects of this article so those will not be explained in depth, but rather at the level that will allow the user to understand how to detect and recognize when the performance of SQL Server is affected
ALTER INDEX REORGANIZE
The Index reorganize operation is a light weight operation that is always performed online in any SQL Server edition and it shouldn’t cause any serious blockings. Reorganize has some advantages and disadvantages, due to the way it works… and it works completely different compared to the index rebuild operation
First, an index reorganize will not defragment the whole index, but just the leaf part of the index. This means that in case of large and heavily fragmented indexes, the intermediate section could be quite large and highly fragmented as well, but it will not be defragmented. While the reorganize operation will not cause the plan recompilation which is good, it does not update statistics and this has to be handled manually after the reorganize operation completes. Since it is the single threaded only operation, it will work slower.
The big pros for index reorganize is that it can be killed/canceled at any moment, and it will not cause any massive rollback – it will just leave the leaf as is, and already defragmented part will remain. Still, it does not allow the user to set the fillfactor and compression options
For large databases with large indexes, an index reorganize operation will not always grant the desired results, and therefore the index rebuild operation must be used, so the rest of the article will be focused on the index rebuild operation
ALTER INDEX REBUILD
A SQL Server index rebuild operation is a higher impact option in the SQL Server index maintenance process. A rebuild operation is generally used when an index is heavily fragmented, and it will do exactly what the word states – SQL Server will drop the old index and then it will build the new one (equivalent to CREATE INDEX … WITH DROP_EXISTING). Therefore, a rebuild operation will fully remove fragmentation (defragments the leaf and intermediate pages), it will reclaim the disk space by compacting the pages and finally it will allocate new pages if required to ensure that index comprises the set of continuous pages. In addition, due to the fact that SQL Server will actually create the new index, it will also update statistics for that index
When an index rebuild operation is executed unattended as part of the regular SQL Server maintenance, if blocking occurs, it can last quite a long time. Therefore, it is smart to investigate any wait types that will be described in the rest of the article when it has excessive wait times
Offline index rebuild operation
What is important from the performance point of view, is that a rebuild operation is an offline operation by default and it causes blockings during execution. Often, the table will be completely unavailable until the rebuild process completes.
To demonstrate the issues caused by a rebuild operation when used offline, the rebuild operation will be executed against a database hosted on the conventional hard drive with the following query
ALTER INDEX pk_bigTransactionHistory ON dbo.bigTransactionHistory REBUILD WITH ( FILLFACTOR = 1, SORT_IN_TEMPDB = ON, STATISTICS_NORECOMPUTE = ON ); GO
A conventional hard drive and fillfactor=1 are used in this query just for demonstration purpose to ensure that rebuild operation will take long enough (in absence of some really large index)
While the index rebuild operation runs, execute a new SELECT query that will request data from the same table where the index rebuild process still running
SELECT Quantity FROM dbo.bigTransactionHistory; GO
Online index rebuild operations
The Enterprise Edition of SQL Server has an additional option that can be called via the rebuild command and it will allow a rebuild process to be performed online (ONLINE=ON option). This can significantly reduce the blockings when performing SQL Server index maintenance.
In the online mode, the rebuild operation will create a new index in the background to allow the existing old index to be accessible for read and writes. Therefore, any change on the existing index will also get applied to the newly created index, while an anti-matter column will be used during the rebuild operation to track conflicts between the rebuild process and the updates performed (i.e. delete of the row which wasn’t copied at the moment of delete).
However, there are some weaknesses when the online option is used
-
The rebuild process will still acquire a Shared Table Lock when operation starts and an exclusive lock on the table at the end (very high level Schema Modification Lock – SCH-M) which ensures replacing the old index with the new one. So, this is not a real online operation as stated, but rather partially online
-
Rebuilding indexes online will take a much longer time to complete (for large indexes alongside with high database activity it could be up to 30x slower) and will use much more resources (e.g. memory, processor, I/O). In case that these system resources become a bottleneck, SQL Server might cause concurrent queries to experience waits and blockings related to those resources
-
Some short period of blockings will still be present
-
Additional disk space required for online index rebuild operation
-
For tables that contain BLOB data types, online index rebuild is not supported in SQL Server 2005/2008/2008R2. Starting with SQL Server 2012, online index rebuild restriction on BLOB is removed, but for the old legacy BLOB data types image, ntext, and text online rebuild operation remains unsupported, and offline index rebuild must be used in that case
-
It is not supported for the non-clustered index that contain the BLOB column itself
-
Online index rebuild is not available for an XML and Spatial index
-
It cannot be used for the index that is on a local temp table
While it is the fact that the ONLINE option resolves some problems primarily with blocking, in a highly active environment there is a great chance that blockings might still cause the problem primarily as shared table lock and schema modification lock must be acquired, so it could be more precisely called “almost online” index operation
The script below will create the test database, a table with the clustered index and will insert some data, and it will be used for all examples in the rest of the text:
CREATE DATABASE TestOnlineIndexRebuildBlocking GO USE TestOnlineIndexRebuildBlocking GO CREATE TABLE RebuildTest (Column1 INT IDENTITY(1, 1) NOT NULL, Column2 INT NOT NULL, Column3 INT NOT NULL) GO CREATE UNIQUE CLUSTERED INDEX idx_Column1 ON TestOnlineIndexRebuildBlocking (Column1) GO INSERT INTO TestOnlineIndexRebuildBlocking VALUES (1, 1), (2, 2), (3, 3) GO
For the purpose of demonstration, a new transaction that will perform an update in the newly created table will be started
BEGIN TRANSACTION UPDATE RebuildTest SET Column3 = 5 WHERE Column1 = 1
This transaction will impose exclusive lock on the data that is to be changed, and an intent-exclusive lock on the corresponding page and the table itself. This mean that it creates the classic locking chain in SQL Server: Table -> Page -> Data
Now let’s execute an online index rebuild
ALTER INDEX idx_Column1 ON RebuildTest REBUILD WITH (ONLINE = ON) GO
The online index rebuild operation at its start will try to acquire the shared lock, but it is not compatible with the intent-exclusive lock on the table level acquired by the update transaction. This will create a typical blocking scenario
When online index rebuild operation is executed unattended as part of the regular SQL Server maintenance, the blocking can last for quite a long time
Online index rebuild operations with WAIT_AT_LOW_PRIORITY option
The change made with introduction of WAIT_AT_LOW_PRIORITY is that the queries executed against the table where SCH_M lock is acquired will not be held up, but rather the SCH_M lock will be set in the lock wait list as a “lower priority” wait, and the lock will be granted in case that for a fragment of time there are no queries that are executed against the table and there are no locks that are granted on the table content. The whole idea of this is that if SCH_M waits long enough in wait list, there is a great possibility that the needed fragment of time without anything happen on the table will occur
The use of low priority must be explicitly granted by user in the syntax of the ALTER INDEX command. Besides defining the low priority, there are additional options that are in use with WAIT_AT_LOW_PRIORITY:
-
Option to define the time in minutes the command should wait
-
The action that will occur when the wait time expired and command is not yet executed. There are three options for this:
-
Change the priority to normal, which will roll back the priority to normal which is the regular priority, and command will work as before (ABORT_AFTER_WAIT = NONE)
-
Abort the online index rebuild DDL operation without any action taken (ABORT_AFTER_WAIT = SELF)
-
Kill all blocking transactions that prevents online index rebuild DDL operations to acquire lock (ABORT_AFTER_WAIT = BLOCKERS). This specific option requires ALTER ANY CONNECTION permission granted to the login
-
Now let’s review the previous example again, but this time the WAIT_AT_LOW_PRIORITY option will be used and all three ABORT_AFTER_WAIT options will be presented. All below queries will use MAX_DURATION of 1 minute
WAIT_AT_LOW_PRIORITY with ABORT_AFTER_WAIT = NONE
ALTER INDEX idx_Column1 ON RebuildTest REBUILD WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY(MAX_DURATION = 1, ABORT_AFTER_WAIT = NONE))) GO
In this particular case, the online index rebuild command will wait at low priority for 1 minute, and then it will change the priority to normal.
WAIT_AT_LOW_PRIORITY with ABORT_AFTER_WAIT = SELF
ALTER INDEX idx_Column1 ON RebuildTest REBUILD WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY(MAX_DURATION = 1, ABORT_AFTER_WAIT = SELF))) GO
When the SELF argument is used with ABORT_AFTER_WAIT, the index rebuild operation will be set in the low priority for 1 minute, and if not able to get the time fraction without table activity in that time, it will terminate itself with message
Msg 1222, Level 16, State 56, Line 1
Lock request time out period exceeded.
What this means is that the user will be put in control over the process, and can define before the fact that index rebuild is not priority operation, so if it doesn’t manage to acquire a lock, it will be terminated, which is a predictable outcome in the maintenance process
WAIT_AT_LOW_PRIORITY with ABORT_AFTER_WAIT = BLOCKERS
ALTER INDEX idx_Column1 ON RebuildTest REBUILD WITH (ONLINE = ON (WAIT_AT_LOW_PRIORITY(MAX_DURATION = 1, ABORT_AFTER_WAIT = BLOCKERS))) GO
When the index rebuild operation is the highest priority, the BLOCKERS argument could be used as it will grant that the index rebuild will eventually acquire the shared lock after 1 minute (if it doesn’t get the fraction of time with no table activity during that period) and the operation will be completed
Besides the LCK_M_S_LOW_PRIORITY wait type, there is in total 21 new low priority wait types introduced in SQL Server 2014. The full list of those wait types can be found in appendix
Appendix
List of Low priority wait types introduced in SQL Server 2014 with links to detailed description
- LCK_M_BU_LOW_PRIORITY
- LCK_M_IS_LOW_PRIORITY
- LCK_M_IU_LOW_PRIORITY
- LCK_M_IX_LOW_PRIORITY
- LCK_M_RIn_NL_LOW_PRIORITY
- LCK_M_RIn_S_LOW_PRIORITY
- LCK_M_RIn_U_LOW_PRIORITY
- LCK_M_RIn_X_LOW_PRIORITY
- LCK_M_RS_S_LOW_PRIORITY
- LCK_M_RS_U_LOW_PRIORITY
- LCK_M_RX_S_LOW_PRIORITY
- LCK_M_RX_U_LOW_PRIORITY
- LCK_M_RX_X_LOW_PRIORITY
- LCK_M_S_LOW_PRIORITY
- LCK_M_SCH_M_LOW_PRIORITY
- LCK_M_SCH_S_LOW_PRIORITY
- LCK_M_SCH_S_LOW_PRIORITY
- LCK_M_SIX_LOW_PRIORITY
- LCK_M_U_LOW_PRIORITY
- LCK_M_UIX_LOW_PRIORITY
- LCK_M_X_LOW_PRIORITY
For more details about wait types, please check the SQL Server wait types article
Useful links:
- New functionality in SQL Server 2014 – Part 3 – Low Priority Wait
- ALTER INDEX (Transact-SQL)
- Guidelines for Online Index Operations
- Online Indexing Operations in SQL Server 2005
- Recommendations for Index Maintenance with AlwaysOn Availability Groups
May 5, 2017






