



The goal of this article is to explain how to use branches in order to diverge from the main development line aka master branch and leave it unaffected by all the committed changesets that are not yet tested and confirmed as good ones. As long as a separate branch is used to commit changes, a master branch can be used to deploy a working copy of a database from source control for any purposes.
For the purpose of this article, a Git repository hosted on Bitbucket.org is used for SQL database version control, but the same applies to any other source control system that supports branching. As a starting point, we have a sample database linked to a repository and all objects initially committed. To show how branches can help in safer SQL database version control we’ll show two scenarios.
The first one for using a single branch to commit all SQL database changes and another one where a developer creates a new branch, related to the next version of a database, we called it 2018R1, to be committed and tested first, before merging with the master branch and deploying to another environment.
Challenge
The challenge is to find a way to have untested changes not being committed to the master branch which should always have a working state of a database. For the purpose of this article, we’ll need a new branch where changes related to bug fixes should be committed in order to be tested and later merged with the master branch.
Pre-conditions
Once a database is linked using ApexSQL Source Control and all objects are initially committed, we’ll have the Action center tab showing no differences:
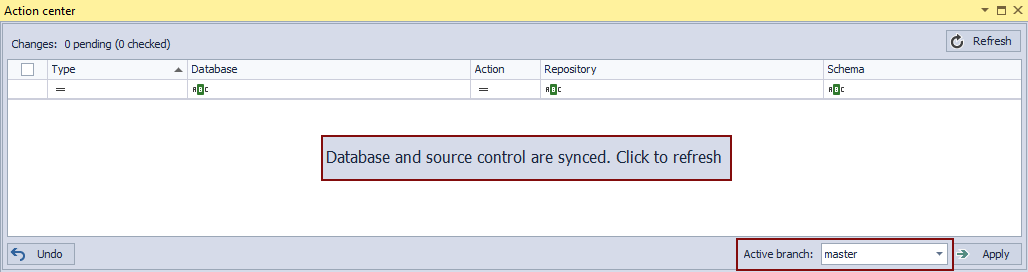
By looking at the repository directly, we could confirm that everything is committed:
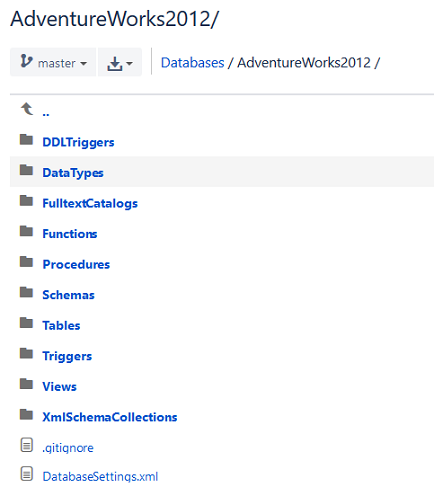
Now that we have a SQL database under source control and we know this is a stable version, SQL scripts of all committed database objects could be pulled at any point, either to build a new database or to apply/synchronize changes to an existing database.
Problem
Single branch
Since we do not have any other branches in this example, any changes will be committed to the master branch. Let’s make a simple change, assuming that this one is related to a bug that should be fixed in a database. We’ll add a new column in the Address table, using the following script:
ALTER TABLE Person.Address ADD TestColumn nchar(10);
We’ll commit this change to the master branch using the Action center tab:
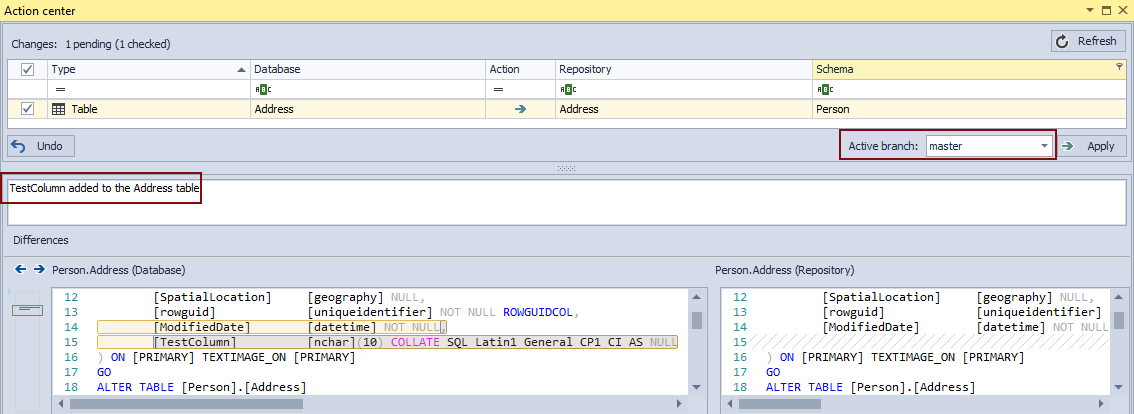
However, besides the initial commit, for which we know it is good, for any additional changes (including the added TestColumn) we cannot guarantee that they won’t cause the process of building a SQL database from source control to fail. Since we are using a single branch for all the changes, there is no way to build a database from any other branch rather than the master branch.
The next challenge is that it isn’t the case that only a single changeset and a single developer could cause a problem. Assuming that we have a team of developers working on the same database in parallel, there will be a lot more than a single changeset that should be tested. While one group of developers may work on a new feature, another one may work on bug fixing, changes etc. To summarize, the master branch could have a number of changes that are not tested, while we won’t have another source to build a database from, but only the master branch where all changes are committed.
Solution
Creating a new branch(es)
Let’s get a step back where we have a SQL database linked and all objects initially committed to the master branch. Assuming that we want to add a new column to the Address table, but we don’t want that change to go to the master branch, we’ll need to create a new branch first.
There are two ways to create a new branch. Directly on bitbucket.org, by choosing the Branches tab from the list on the left and clicking the Create branch option in the upper right corner:
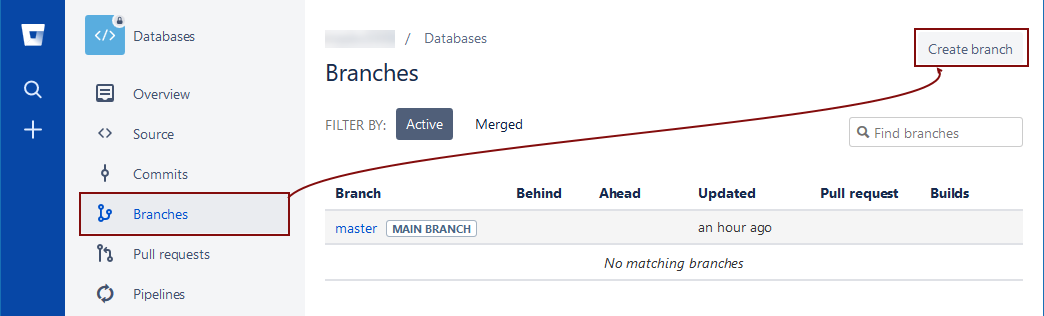
This initiates the Create branch dialog to specify a name for the new branch. We’ll name it 2018R1:
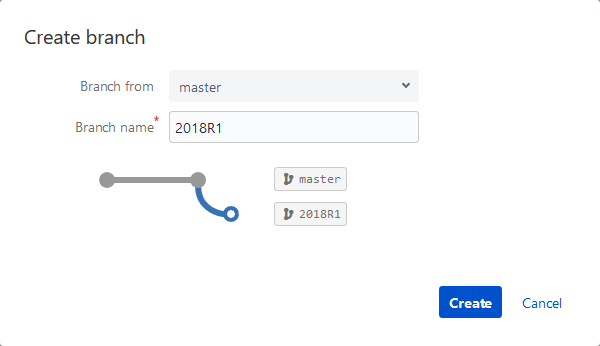
As shown in the image above, a new branch is created from the master branch. That means anything that is committed to the master branch at the time we created a new branch will be duplicated and available in a new branch.
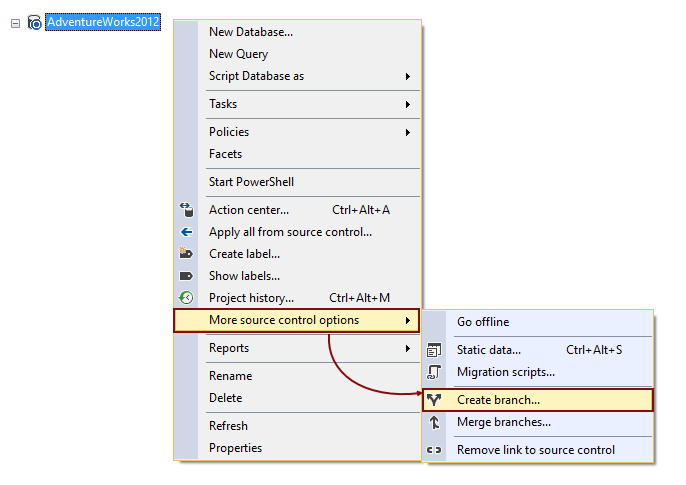
The same can be achieved directly from SQL Server Management Studio, using the option to create a branch from the Object Explorer context menu:
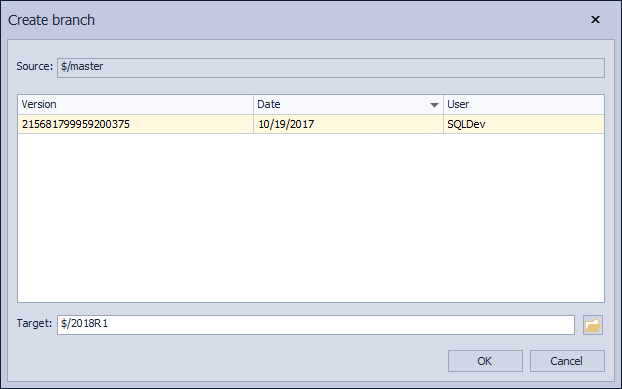
This initiates a dialog to create a new branch. We’ll specify 2018R1 as a name for the new branch, in the Target field, which will be created from master that is by default set as a source branch:
Now that we have a new branch created, any changes that are committed to the new branch will not affect the master branch in any way. Once it is created, the important step is to set a new branch as active. To do so, we’ll choose a newly created branch from the Active branch drop down list in the Action center tab:
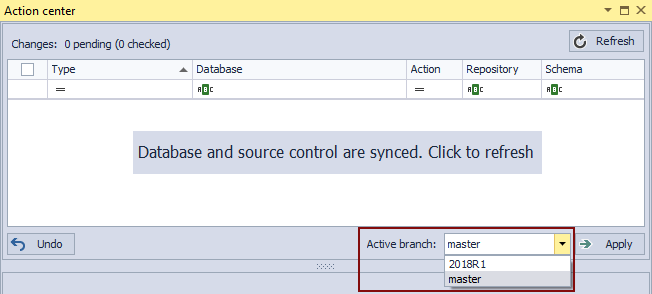
From now on, any change in a database, detected by ApexSQL Source Control and shown in the Action center tab can be committed to a newly created branch. Let’s make the same change again with adding a new column to the Address table, but this time we’ll commit to the 2018R1 branch, instead of the master branch:
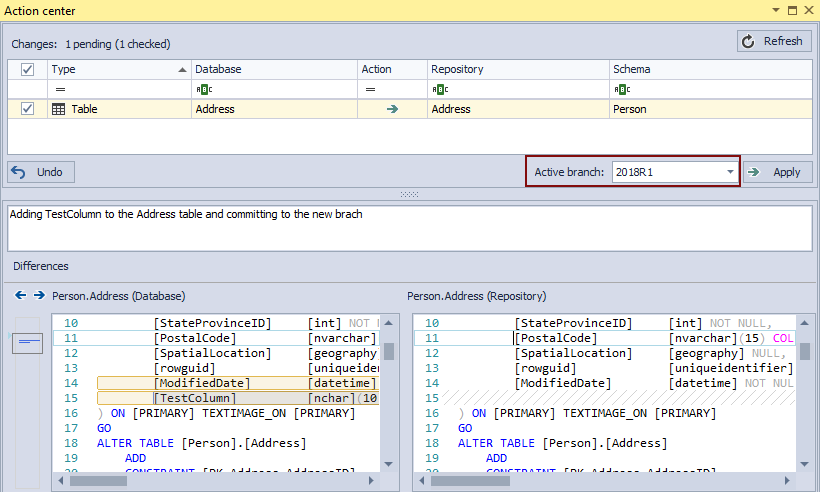
Assuming that we can build a database from the 2018R1 branch to the environment where it can be tested, we have the master branch unaffected containing the working version of a database.
Adding a column to the Address table is just an example of modifying a database, just as 2018R1 is an example of a branch where changes related to the next version of a database will be committed. Similar to this, we could create branches, for each new feature, for other fixes, or anything else where an isolation from the master branch is needed.
Once a new feature is fully developed and tested, or a bug fix is confirmed and changes are verified as good ones, changesets committed to other branches can be merged with the master branch and in that way, keep the master branch up to date, but at the same time keep the working state of a database in the master branch.
Similar to creating a new branch, merging can be performed directly on the repository or from SQL Server Management Studio using ApexSQL Source Control.
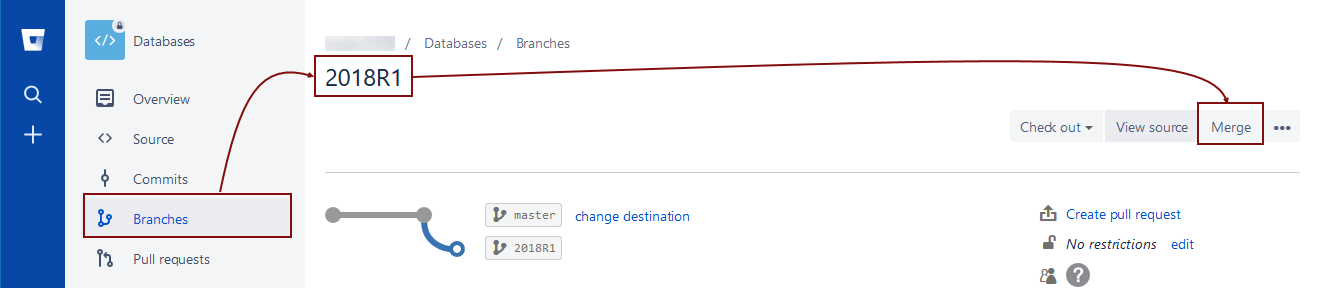
To merge branches on bitbucket.org, navigate to a newly created branch and choose the Merge option in the upper right section:
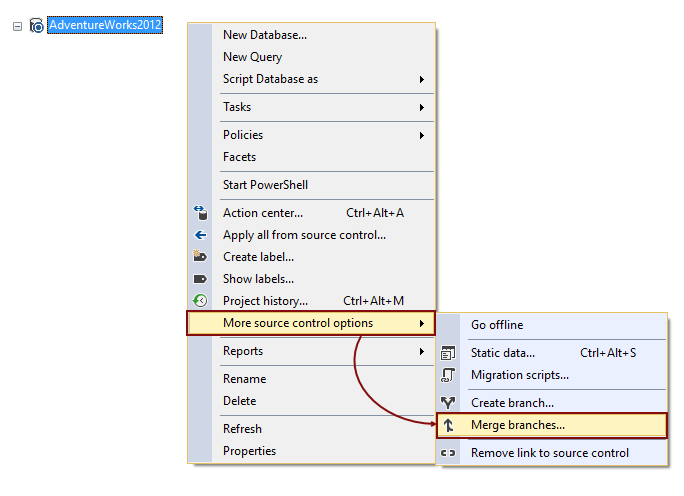
To achieve the same in SQL Server Management Studio directly, right click a linked database in the Object Explorer pane and from the context menu, select the Merge branches option:
This initiates the Merge branches dialog where source and target branches need to be specified in order to merge changes. For the purpose of this article, we want to merge changes from 2018R1 with the master branch:
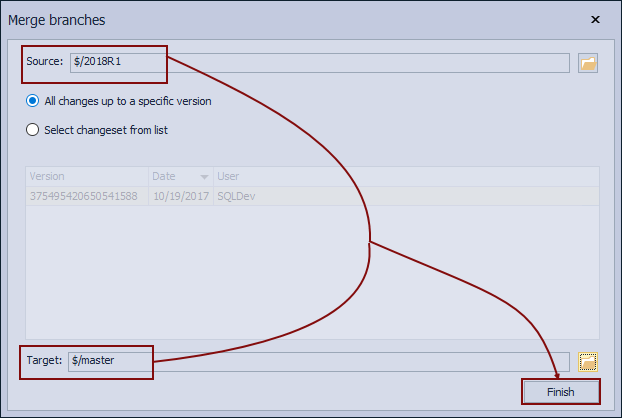
By doing so, we will apply all the differences to the master branch. To verify that everything is as expected, we should see TestColumn added to the Address table in the master branch. If we navigate to the master branch and find the Address table, the following is a result:
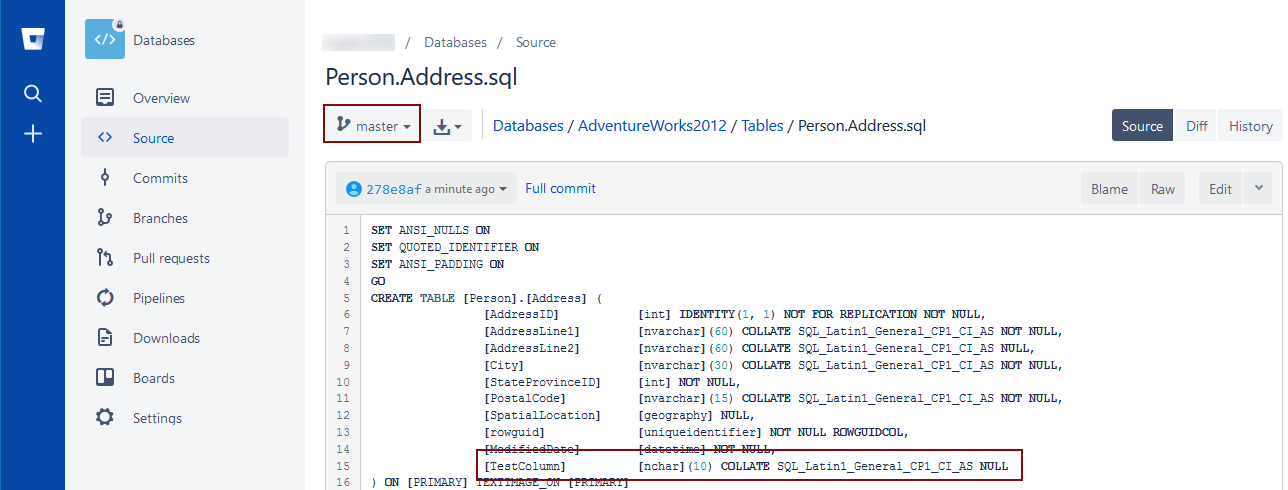
As shown in the image above, TestColumn is added to the Address table in the master branch.
Conclusion
By using branches, code changes can be made to diverge from the main development line, keeping it secured from untested changes, but allowing new development to continue unfettered. Since a new branch represents a duplicate of the original, it allows teams to experiment with new changes, and to iterate in making changes until the team is satisfied with the result, in a low-risk environment without concerns of damaging the main branch. All of the changesets remain in isolation. After testing these changes, and verifying them as good, changes can be merged from the created branch with the master branch allowing others to use them, without breaking the database.
October 23, 2017






