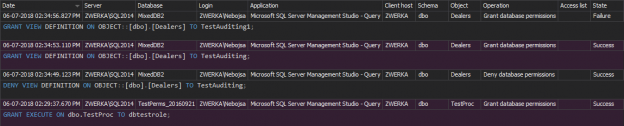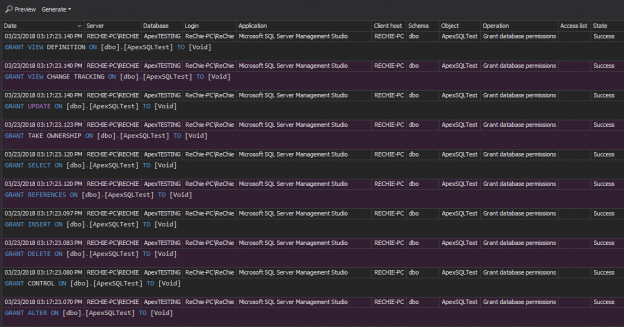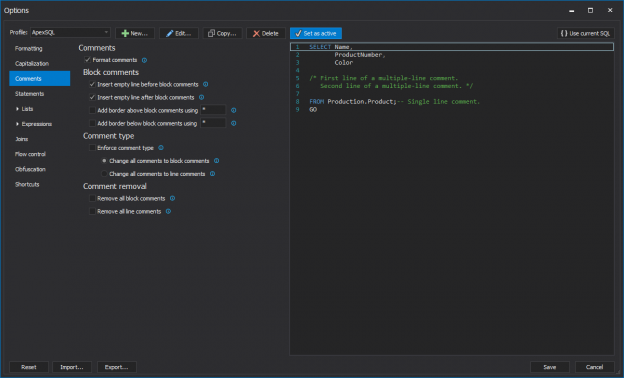
In this article, tips on T-SQL code commenting and improving productivity will be given, while using the ApexSQL Refactor’s Comments feature. ApexSQL Refactor is a SQL Server and Visual Studio SQL formatting add-in with nearly 200 formatting options.
The main purpose of comments is to document our code and write descriptions of what code is doing.
February 12, 2014