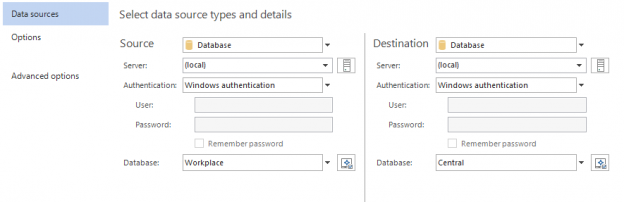
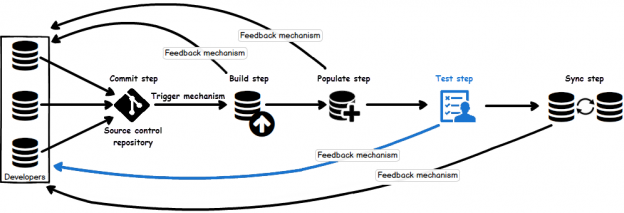
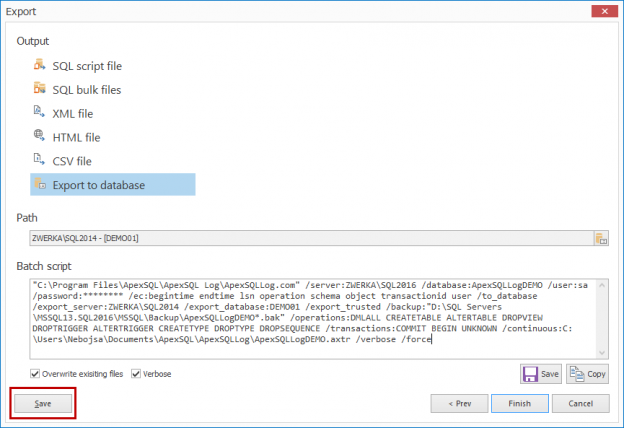
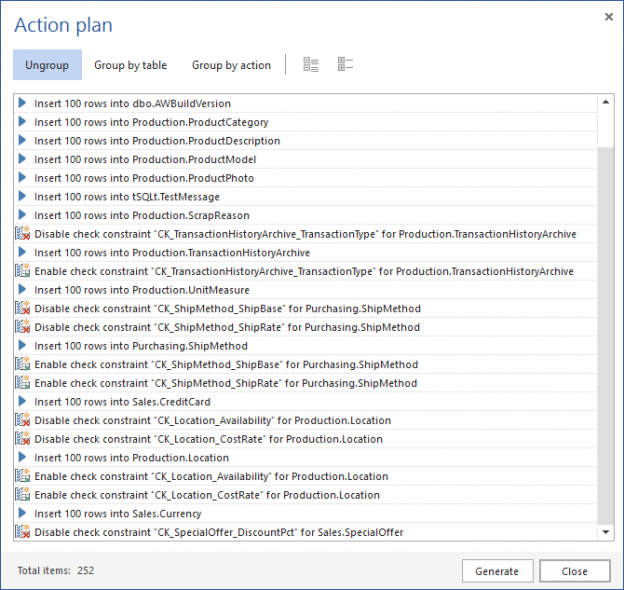
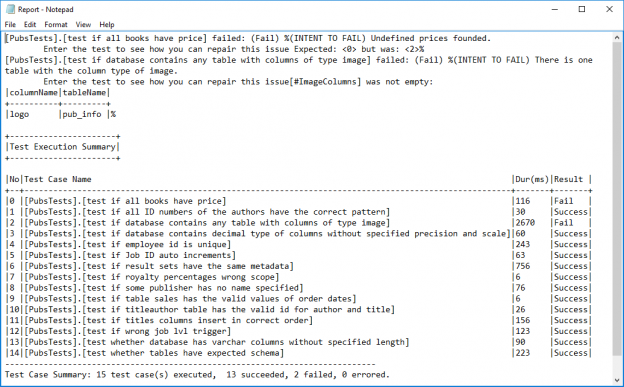
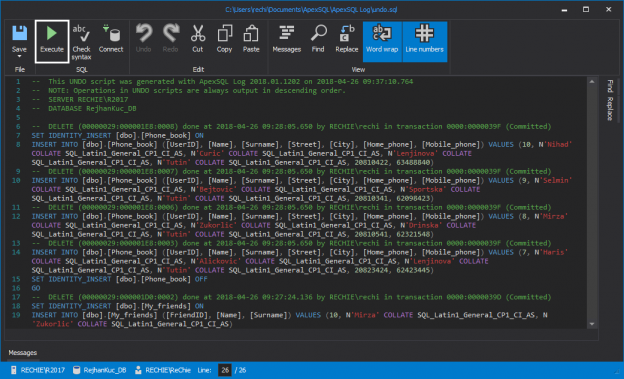
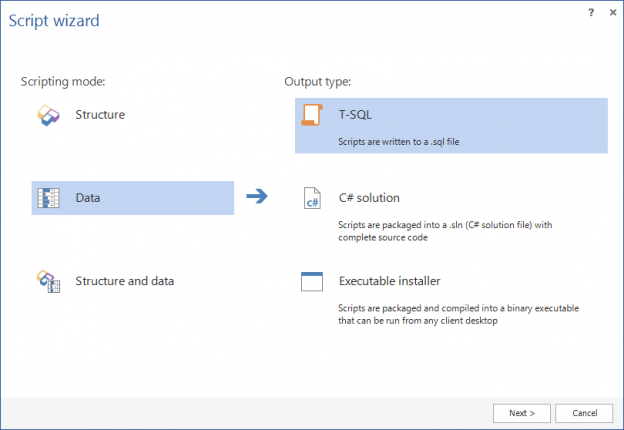
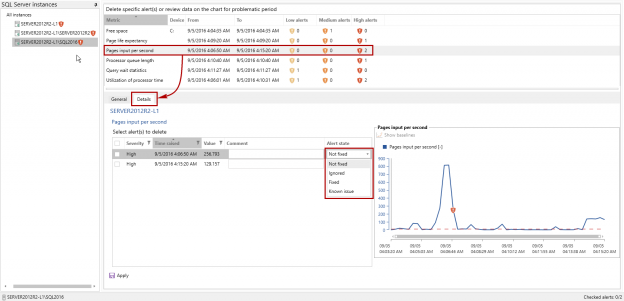
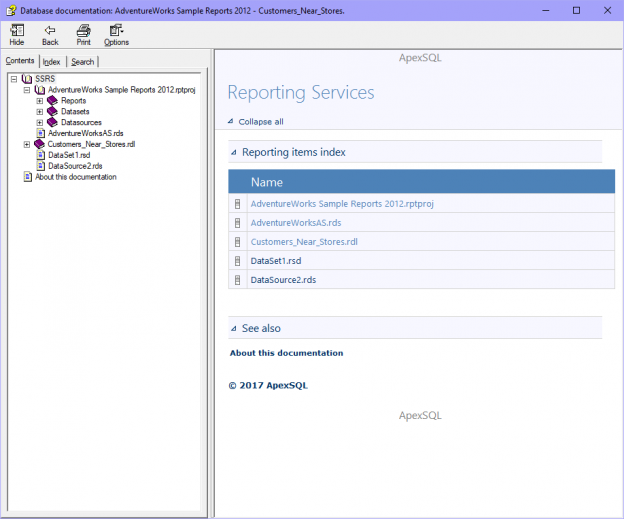
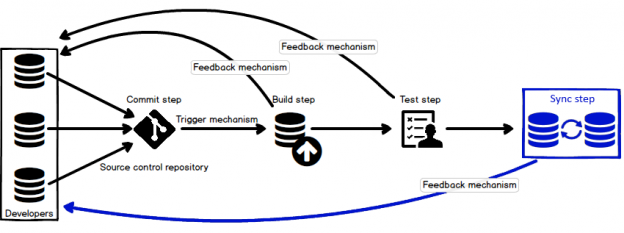
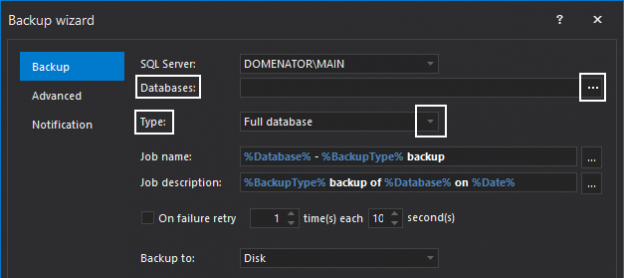
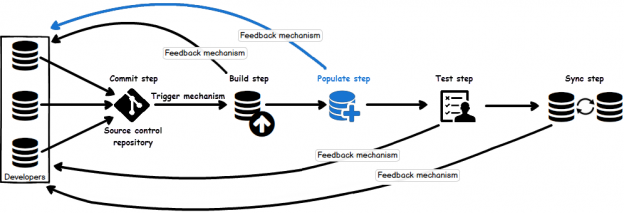
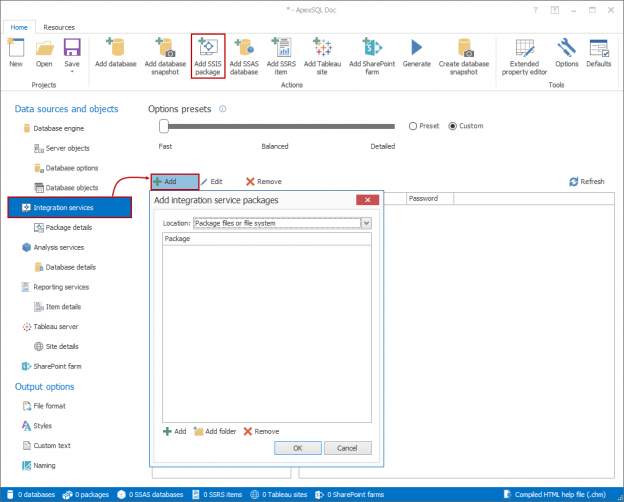
In case of database development, in the same way as for the application development, there are always tasks such as developing a new feature, fixing bugs from the current release, experimenting with code in order to improve performance, usability in any way and so on. Because of all of this, it is essential that any changes that have to be committed, but not immediately, are segregated to an isolated environment, that does not affect the rest of the team or the main code. For instance, when developing a new feature, it may require a lot of changes to be committed, before the feature, or even a functional part of the feature becomes useful, so the rest of the team can apply it on their local copies of a database. Without having the isolation while developing, the team will lack the freedom to code, without having to worry about breaking the existing code base.
May 25, 2016