



Introduction
There is a maxim that comes from the world of Python programming: “There should be one – and preferably only one – obvious way to do it.” (See The Zen of Python) in the references. While that is a good goal for any language, it is a difficult goal to achieve. T-SQL is no exception here!
Consider a simple problem: You have a customer transaction table with dated rows. You are asked to produce a list of the top transactions per day. “Top” could be defined as the one with the most items, the highest value, the most important customer or a variety of other criteria. However, you define it, at some point, you will want the maximum (or minimum) value of one of the columns. Then you will want to output the entire row (or rows, in the case of a tie) matching that value. Sounds simple, right? Well, it actually is simple, but the number of ways to do it may surprise you!
This article will look at the various ways to construct such a query and analyze each one for its performance characteristics. The goal is not so much about picking a winner as it is to learn how to analyze queries using a tool like ApexSQL Plan.
The transaction table
Let’s consider a simple transaction table. In all likelihood yours will be more complicated than this one, but it will suffice for the examples and analysis that follows.
CREATE TABLE [dbo].[Transactions] ( [TransactionID] [bigint] IDENTITY(1, 1) NOT NULL ,[CustomerID] [bigint] NOT NULL ,[Transactiontype] [tinyint] NOT NULL ,[TransactionTime] [datetime] NOT NULL ,[TransactionAmount] [money] NOT NULL ) ON [PRIMARY] CREATE CLUSTERED INDEX [IX_Transactions_TransactionID] ON [dbo].[Transactions] ([TransactionID] ASC)
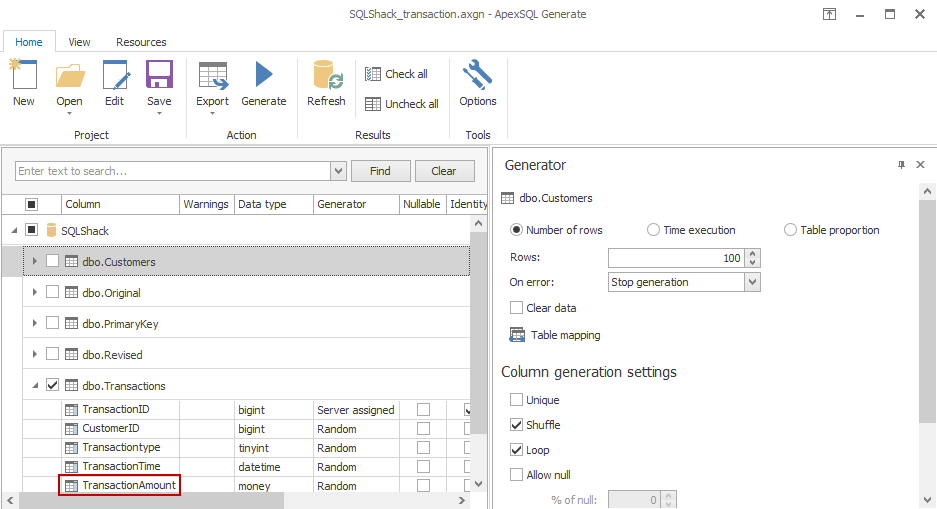
I’ll use ApexSQL Generate to populate this table with 100,000 rows, choosing random values except for the identity column, which is assigned by SQL Server.
The problem
For this exercise, let’s assume that the problem is stated like this:
“For each day, select the row containing the greatest value in the TransactionAmount column. Now that means that we need to find the greatest amount for each day and use that to get to the rest of the columns. Selecting the greatest amount for each day is a simple query with GROUP BY:
SELECT CAST(t.TransactionTime AS DATE) AS DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount GROUP BY CAST(t.TransactionTime AS DATE) ORDER BY CAST(t.TransactionTime AS DATE);
This [Grab your reader’s attention with a great quote from the document or use this space to emphasize a key point. To place this text box anywhere on the page, just drag it.] works just fine, but I’m troubled by something. Three times in this query we have the expression:
CAST(t.TransactionTime AS DATE)
The way this is written, I need the expression in at least two places, the SELECT statement and the HAVING clause. I could change the ORDER BY to use the column alias DateOfTransaction, since column aliases are available after the SELECT portion of a query, but I’d really like to get rid of the repetition altogether. I can use CROSS APPLY for that:
SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) GROUP BY dt.DateOfTransaction ORDER BY dt.DateOfTransaction;
Now, I bet you’re wondering how this change affects the performance of the query. To answer briefly, not at all! To prove it, let’s fire up ApexSQL Plan.
If we just look at the estimated plan for each query, we can see that they are the same:


The CROSS APPLY version is a little longer to type but eases maintenance since the original column name is now referenced only once. The query is DRY-er.
“Well,” you say, “an estimated plan is all well and good, but what happens when you run it?” Good question! Let’s do that!

The I/O reads are identical, so I only pasted one copy. If you dig into the execution plan XML you won’t see any effect of the CROSS APPLY either, other than in the StatementText attribute. Since the CROSS APPLY only references columns in the current row in the input buffer, it has no effect other than making the query easier to read. Note that if the CROSS APPLY referenced another table, this would not be the case; it would function like a JOIN and the execution plan, CPU usage and I/O counts would reflect that.
First attempt: use a cursor
Many developers coming from a non-declarative language such as Java or C or Python might think in terms of writing a loop. In T-SQL, that would be a cursor. We can use the query above in just such a loop to produce the desired results:
-- Get maximum amount by day DECLARE MaxAmtCur CURSOR LOCAL FORWARD_ONLY FAST_FORWARD READ_ONLY FOR SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) GROUP BY dt.DateOfTransaction ORDER BY dt.DateOfTransaction; OPEN MaxAmtCur -- Create a table variable to hold the results DECLARE @DateOfTransaction DATE ,@MaxTransactionAmount MONEY DECLARE @Results TABLE ( [TransactionID] [BIGINT] ,[CustomerID] [BIGINT] NOT NULL ,[TransactionType] [TINYINT] NOT NULL ,[TransactionTime] [DATETIME] NOT NULL ,[TransactionAmount] [MONEY] NOT NULL ); -- Loop through the maximum amounts to find matching transactions WHILE 1 = 1 BEGIN FETCH NEXT FROM MaxAmtCur INTO @DateOfTransaction ,@MaxTransactionAmount; IF @@FETCH_STATUS <> 0 BREAK; -- Insert matching rows into the results table INSERT INTO @Results ( TransactionID ,CustomerID ,TransactionType ,TransactionTime ,TransactionAmount ) SELECT t.* FROM dbo.Transactions t WHERE CAST(t.TransactionTime AS DATE) = @DateOfTransaction AND t.TransactionAmount = @MaxTransactionAmount; END;
This script inserts the results in to a table variable. This lets me focus on the query and ignore the intermediate results. As for this one, well it certainly works but I didn’t have the patience to wait for it to complete. Here’s why: After the initial query to find the maximum amounts by day, the loop inserts one row at a time (RBAR = Row By Agonizing Row – an acronym created by Jeff Moden, long-time SQL Server MVP.) Now, the table of maximum values by day has over 2100 rows. How does the INSERT perform inside the loop? The plan diagram will show us!
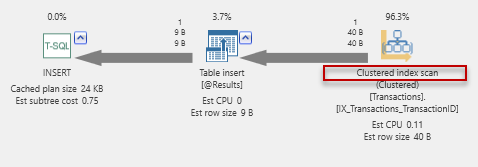
It does a clustered index scan! Recall that there are 100,000 rows in the transactions table. That means 2100 iterations * 100000 rows to read all the rows to complete the job. I’ll let you do the math. The result is not pretty.
There is an ABC lesson here: Anything But Cursors! If you can do it any other way, it will perform better than a cursor-based approach. Keep in mind that a relational database is based on relational algebra, which combines set theory with predicate calculus. Think in sets, not rows!
Second attempt: Use an inner join
Here is a join-based query:
SELECT TransactionID ,CustomerID ,TransactionType ,TransactionTime ,TransactionAmount FROM dbo.Transactions t INNER JOIN ( SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) GROUP BY dt.DateOfTransaction ) t1 ON CAST(t.TransactionTime AS DATE) = t1.DateOfTransaction AND t.TransactionAmount = t1.MaxTransactionAmount ORDER BY t1.DateOfTransaction
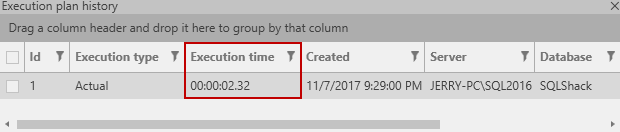
This is an enormous improvement! According to ApexSQL Plan, the query above runs in
The execution plan is a little complicated though:
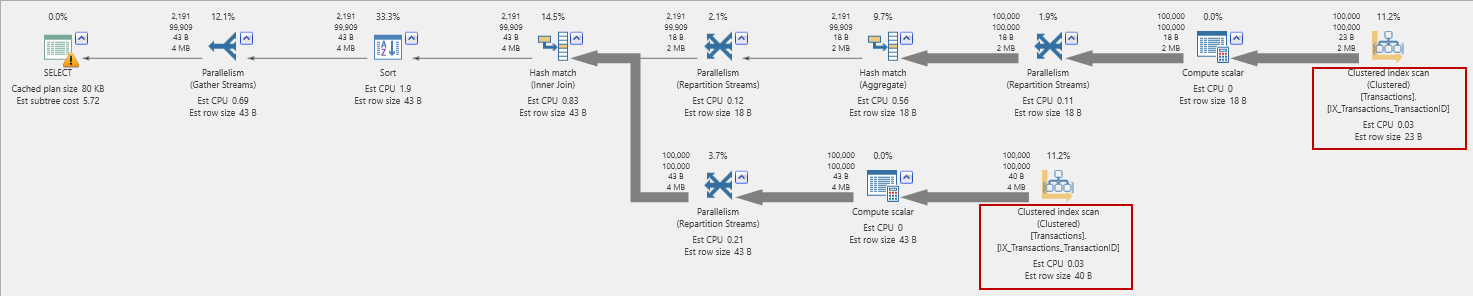
And has two clustered index scans of the transactions table. What about the I/Os?

Quite respectable, really!
Alternatives to inner join
There are a few different alternatives to using an inner join. Perhaps you wondered if I could use CROSS APPLY? Indeed:
SELECT TransactionID ,CustomerID ,TransactionType ,TransactionTime ,TransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) CROSS APPLY ( SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) GROUP BY dt.DateOfTransaction ) t1 WHERE CAST(t.TransactionTime AS DATE) = t1.DateOfTransaction AND t.TransactionAmount = t1.MaxTransactionAmount ORDER BY t1.DateOfTransaction;
This query produces the same plan and statistics as the INNER JOIN variant, so I won’t waste space here showing it. Changing the join operation to a CROSS APPLY (and the ON clause to a WHERE Clause) changes nothing on the inside. Note that in this case, the second CROSS APPLY performs the aggregating sub query and is not an intra-row operation as is the first one.
A more interesting alternative would be this:
WITH MaxAmts ( TransactionDate ,TransactionAmount ) AS ( SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) GROUP BY dt.DateOfTransaction ) SELECT t.TransactionID ,t.CustomerID ,t.TransactionType ,t.TransactionTime ,t.TransactionAmount FROM dbo.Transactions t WHERE EXISTS ( SELECT 1 FROM MaxAmts m WHERE m.TransactionDate = CAST(t.TransactionTime AS DATE) AND m.TransactionAmount = t.TransactionAmount )
The Common Table Expression (CTE) used in this example doesn’t change the plan. Recall that, except for the recursive variety, a CTE is just a way to write a sub query before the main query instead of after it. Used in this way, CTEs can make for more readable code. If you thought the correlated sub query in the WHERE EXISTS clause would change the plan, you’d be mistaken! The plan and performance characteristics are identical to the previous two queries. So, which one do I prefer to use? In general, when given a choice, I like queries that are easy to read. While I admit that that is subjective, for me it generally means opting for fewer subqueries and shallower levels of parentheses and indentation. With that in mind, I like this, hybrid version best:
WITH MaxAmts ( TransactionDate ,TransactionAmount ) AS ( SELECT dt.DateOfTransaction ,MAX(TransactionAmount) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(TransactionDate) GROUP BY dt.TransactionAmount ) SELECT t.TransactionID ,t.CustomerID ,t.TransactionType ,t.TransactionTime ,t.TransactionAmount FROM dbo.Transactions t INNER JOIN MaxAmts m ON CAST(t.TransactionTime AS DATE) = m.TransactionDate AND t.TransactionAmount = m.TransactionAmount ORDER BY m.TransactionDate
This has the same execution plan and run characteristics as the first three and is – from my perspective at least – the easiest one to read.
There is one other thing these three variants have in common: All report a missing index.

I’ll come back to the problem of the missing index a bit later. For now, let’s continue with a different approach:
Third attempt: using window functions
Starting with SQL Server 2005, Microsoft began introducing window functions. These are not Microsoft’s invention but rather their implementation of the ANSI/ISO Standard SQL:2003 which was later extended in ANSI/ISO Standard SQL:2008
Since we want to find the maximum/minimum value of some column, the MAX() OVER() and MIN() OVER() functions come to mind. Let’s start there!
SELECT t.TransactionID ,t.CustomerID ,t.TransactionType ,t.TransactionTime ,t.TransactionAmount FROM ( SELECT * ,MAX(TransactionAmount) OVER (PARTITION BY dt.DateOfTransaction) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) ) t WHERE t.TransactionAmount = t.MaxTransactionAmount ORDER BY t.TransactionTime;
This query produces a complicated plan:
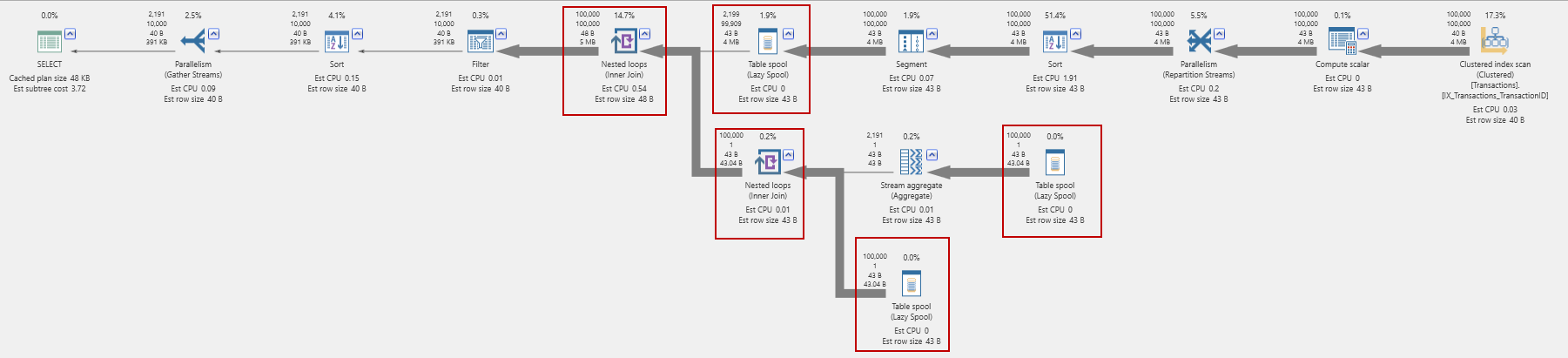
With two nested loop joins and three table spools! The I/O counts reflect this:

Just look at those worktable reads! I think we can discard this version out of hand.
Using FIRST_VALUE
The FIRST_VALUE() window function takes the first value from each partition based on some ordering. For the working example, this should do the trick:
SELECT t.TransactionID ,t.CustomerID ,t.TransactionType ,t.TransactionTime ,t.TransactionAmount FROM ( SELECT * ,FIRST_VALUE(TransactionAmount) OVER ( PARTITION BY dt.DateOfTransaction ORDER BY TransactionAmount DESC ) AS MaxTransactionAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) ) t WHERE t.TransactionAmount = t.MaxTransactionAmount ORDER BY t.TransactionTime;
How does this one compare? Here’s the execution plan, split onto two lines for readability:
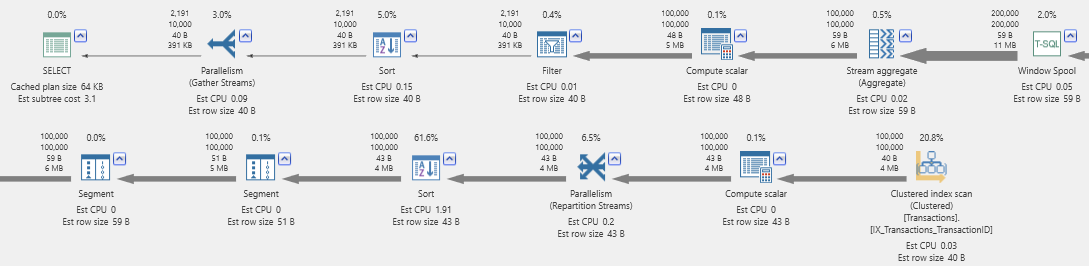
This plan is a straight line. There are no joins of any type. What about the I/Os? (Hint: There is a Window Spool operator in there.)

Even worse! Rule that one out, too.
Using RANK
The RANK() function seems like a possible good fit here. The query would look like this:
SELECT t.TransactionID ,t.CustomerID ,t.TransactionType ,t.TransactionTime ,t.TransactionAmount FROM ( SELECT * ,-- OK, I'm lazy! Don't use SELECT * in production code! RANK() OVER ( PARTITION BY dt.DateOfTransaction ORDER BY TransactionAmount DESC ) AS RankAmount FROM dbo.Transactions t CROSS APPLY ( SELECT CAST(t.TransactionTime AS DATE) ) dt(DateOfTransaction) ) t WHERE t.RankAmount = 1 ORDER BY t.TransactionTime;
This query yields the execution plan:

This plan is also a straight line and the spool operations are gone. The I/O picture looks like this:

No worktable I/O and a linear execution plan! This is half the number of I/Os of my preferred JOIN-based query. We have a winner!
To me, one interesting thing is that the windowing queries using MAX() and FIRST_VALUE() have such different characteristics. When you think about the problem I’m solving, they are just alternate ways of stating the solution. Seeing this means that you should always look at a few variants before deciding on the query to use. Using MAX() here seems the closest to the problem statement but if performance matters, you may want to use RANK() instead.
Note that I said, “if performance matters”. Well, doesn’t it always matter? Sometimes, not as much as you might think. If the result sets are on the small side (for various values of “small”) and the query is infrequently used (that is, not hundreds of times a second), I would use MAX() since it produces readable code that reproduces the problem statement in SQL.
What about that index?
ApexSQL Plan told me there is a missing index. What happens if I actually implement it? ApexSQL Plan will show you the suggested index if you right click on the missing index message:

Using the highlighted Copy button, I can copy this to another session (or SSMS) and actually create the index. How does this change things? My favorite JOIN-based query, above, now has a new plan:
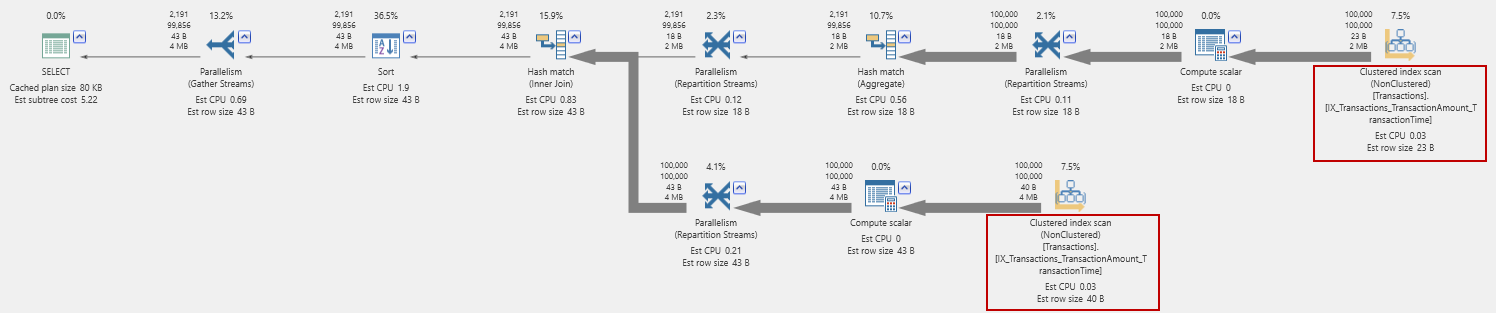
Notice that it now reads from the new index (highlighted) to get the maximum amount values per day. Then it joins back to the same index to get the other columns.
The I/O reads though, actually went up, from 1748 to 3924. For this particular query, the index did not help. Also, I wonder if a new, covering index is really the right idea? It has to be maintained, after all and it contains the same data as the clustered index. At the very least, this means that you should not accept the missing indexes at face value. Take time to consider the consequences.
How about the query using RANK()? No difference! It did not even use the new index and really, it doesn’t need it. SQL has to read every row in the table any way, to compute the maximum transaction amount per day.
Summary
Given a simple problem, I’ve shown several approaches to solving that it in SQL. The JOIN-based solutions perform respectably, but are completely blown away by the RANK-based window function query. However, that doesn’t mean that all your queries for similar problems should use RANK. It means that you do need to consider alternatives and test them. There is no one-size-fits-all solution. Take the time to look at the execution plans of various queries before deciding on one. Using ApexSQL Plan I was able to try many variants and compare their results, both with and without the reported missing index. This makes ApexSQL Plan a great tool for every SQL developer!
References
- The Zen of Python
- DRY: Don’t Repeat Yourself
- Using the APPLY operator
- Window functions in SQL Server
See also
- SQL query performance tuning with I/O statistics and execution plans
- How to identify and solve SQL Server index scan problems
- T-SQL commands performance comparison – NOT IN vs NOT EXISTS vs LEFT JOIN vs EXCEPT
November 22, 2017






