



When synchronizing large databases that contain millions of records, you will come across several challenges The first challenge is to just compare such databases. When the database tables contain millions of records, their comparison through the ApexSQL Data Diff graphical interface will be very slow and in such cases, it is strongly recommend using the ApexSQL Data Diff command line interface. As there’s no need to show millions of records visually in the tool’s grid, such large databases are processed faster.
April 29, 2013Audit SQL Server database security changes
The saying “An ounce of prevention is worth a pound of cure” is ever so true when it comes to SQL Server security. Even if everything seems fine with your SQL Server environment from a security standpoint (i.e. no unexpected slowdowns or increased network traffic; none of the data or the objects are damaged corrupted or missing), as we’ve outlined in several articles before, having an auditing system up and running can be literally a life savior when it comes to any suspicious activities, such as unauthorized permission changes or compromised SQL logins. So, how can one set up SQL Server auditing?
April 26, 2013Audit SQL Server permission changes to improve overall security
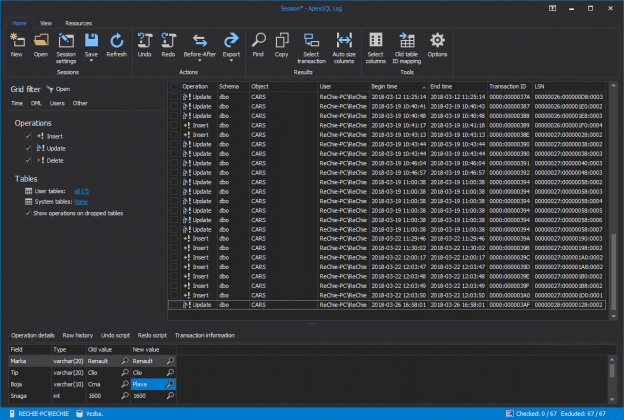
One of the most important tasks for a DBA aiming to keep database and the data in it secure and away from unauthorized access or, heaven forbid, malicious changes is to always stay on top of the effective SQL Server permissions his users have over the SQL instances as well as the databases, database objects and data stored in them. Although this might seem like a pretty straightforward task, as the number of database users grows on one hand, and the number of databases and objects on the other things can get really complicated. Add to that the ever changing business requirements, and soon, unless you have some kind of documenting system in place, you can end up with users not having sufficient permissions or even worse – users having more permissions that they actually require
April 23, 2013Improve the performance of an ETL process
Due to the sheer volume of data usually involved in an Extract – Transform – Load (ETL) process, performance is positioned very high on the list of requirements which need to be met in order for the process to go as smoothly as possible. Here are some guidelines which will help you speed up your high volume ETL processes
April 23, 2013Synchronize SQL Server databases in different remote sources
The scenarios
The applications used by travelling sales representatives, or other field workers – delivery drivers, visiting nurses, etc., are designed to collect data from remote locations and then send it to a data center. Also, the data from the data center, occasionally need to be sent back to these remote locations, to keep them up to date.
For example, whenever nurses pay a visit to a patient, they enter the information about the visit into the database on mobile devices. At the end of the day, all these entries created during the day are sent to the central database in a hospital. After that, the nurses can synchronize mobile devices with the database in the hospital data center, so they get the new information about their patients, and also, the information about any new visits they need to make the next day.
In the scenario such as this, there’s constantly a need to synchronize the information from a mobile device to a central database.
April 19, 2013Get to know an inherited SQL Server database
Taking over a database you’re not familiar with requires you to dedicate some time to analyze and understand it. Deciphering an inherited database takes some time, that among other factors, depends on the available documentation (if any), comments left in object SQL, and database complexity.
April 18, 2013Recover deleted records in Dynamics CRM 2016
Even though Dynamics CRM 2016 is very on clear on the fact that that record deletion is permanent and even provides a warning, it’s not unusual one or more CRM records to be deleted by accident. The bad news is that once the records have been deleted, there is no way to undo the deletion as removing a record from CRM actually translates to deleting it from the underlying SQL database.
That is one of the biggest differences between Dynamics CRM 4 and Dynamics CRM 2016. Unlike Dynamics CRM 2016, Dynamics CRM 4 uses the “soft delete” approach. This means that a deleted record in Dynamics CRM 4 could be recovered relatively effortlessly – to recover a deleted record from Dynamics CRM 4 all you have to do is to connect to the underlying database, locate the deleted record and simply update the value in that record’s IsDeleted column to false. So, how can one go about recovering deleted records from a Dynamics CRM 2016 database?
April 12, 2013Use database backups as live SQL Server databases to reduce downtime
Being able to revert to the latest available backup immediately is a key requirement that every SQL Server DBA needs to meet. There are so many scenarios in which immediate action needs to be taken – starting from actual disk failure or corruption, system failure all the way to UPDATEs without WHERE clauses, malicious INSERTs or accidental DELETEs, DROPs or TRUNCATE operations. However, usually this is easier said than done
Even if you take meticulous care of your database backups, have the last available database backup verified and at hand and are sure that restoring it won’t overwrite any valid changes made to the database since the accident has occurred – the fact that the system will experience downtime until the backup is fully restored still remains. Luckily, downtime caused by the time needed for a full database backup restore can be minimized
April 12, 2013How to check whether you can safely deploy to production database
The time when source control systems were used only for code development is gone. Today, database versioning is quite common, even in small companies.
As there are many different source control systems, with different features and options, there are no strictly defined rules how to use them. Each company can create its own standards and rules for using a source control system for database versioning, following the best practices and recommendations.
Depending on which source control system is used, and what the usage schema and environment flow are, the goals of using source control systems are safety, easier team-based database development, and deployment automation.
In a multi-environment system, each environment represents a state through which a database must pass, until it reaches its final destination – production. For example, development of new features and fixing of existing issues is carried out in Development, then they are tested in Integration (or Testing) and Production is where your live databases are.
One of the common rules is that all deployments come from source control. In other words, all database changes must go into source control first and then be deployed to production.
Does it always have to be so?
It should, but unfortunately, it isn’t. Despite all the benefits that a source control system brings, the key factor is still human. If there’s no discipline, developers can skip a step or two, ignore a rule, or do something that doesn’t comply with the standards. A developer in a time crunch might have applied a change directly to production, skipping both the development and testing environments, and never adding the change to source control.
The good news is – in a versioned environment, this can be easily fixed. Furthermore, possible problems caused by this undisciplined approach can be prevented by checking the production database before deployment.
No matter how small the change is, and how small the difference between the production and the source control version is – it’s still a difference. Even just changing a column data type from int to e.g. nvarchar(50) in production, makes a difference that can cause headaches when deploying a new version from source control. Next time the new version is deployed to production, either scheduled, or on demand, deployment can fail.
If lucky, all that will happen is that the latest version cannot be deployed. In a worse scenario, even some data can be lost.
How can be made sure there were no direct modifications of your production database?
Before the deployment starts, check whether there are any differences between the production database and the source control system version that was deployed last. Another option is to compare the live database to a full database backup created immediately after the last deployment if they are available.
ApexSQL Diff is a SQL Server database comparison and synchronization tool which detects differences between database objects in live databases, full and differential database backups, databases versioned in source control systems, script folders and database snapshots. It generates comprehensive reports for the differences and can automate the synchronization process.
- Start ApexSQL Diff
-
Once the New project window is shown set the following in the Data sources tab:
- Select Database as a source type
- Select the production database as the source
- Select Backup as a destination type
- Select the full database backup taken immediately after the last deployment as the destination
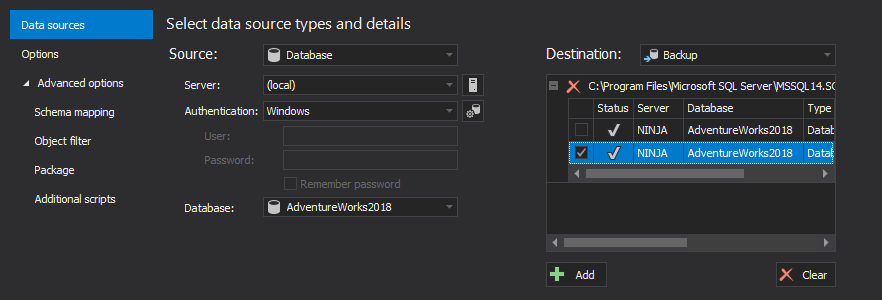
- Click the Compare button
-
To switch how to view differences, on the View tab, click one of the buttons under the Grouping section. By default, the Group by difference type option is selected:

- All objects in the Results grid will be grouped as equal, different, in source or in destination only.
If there are no differences, all objects will be shown as equal.If there are any different objects, check out their differences in the Script difference view panel:

- To create a synchronization script, check the objects in the Results grid that should be synchronized
-
Click the Synchronize button from the Home tab to initiate the Synchronization wizard:

-
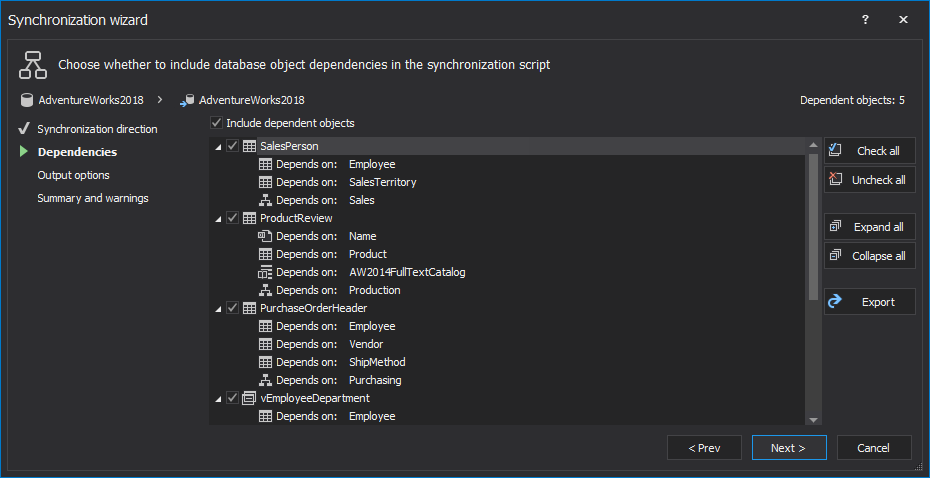
In the first step of the Synchronization wizard, the synchronization direction will be shown, while in the second step, any dependent objects will be automatically checked and added in the synchronization script:
-
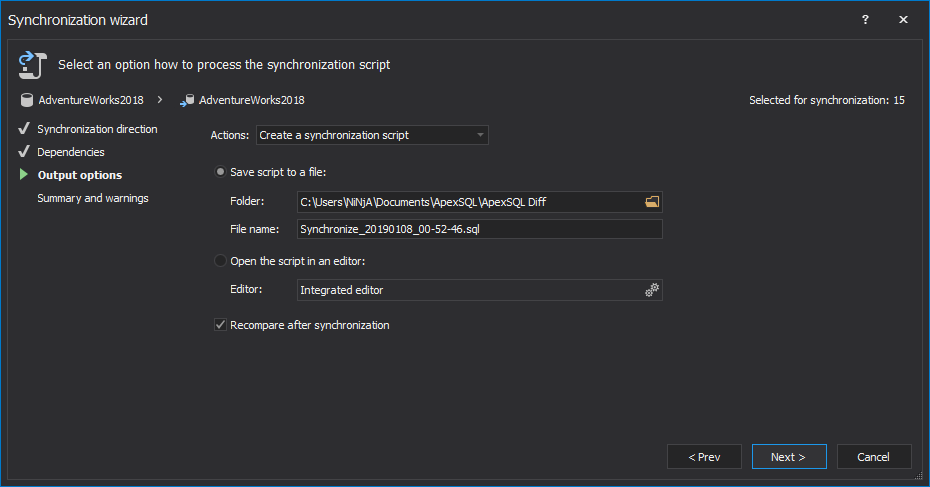
Under the Output options step, leave the Create a synchronization script action and choose the Save script to a file option:
-
In the last step, review the Summary and warnings and click the Create script button to finish the process:

Get back to developers, investigate the differences, and decide the best course of action in this specific situation. The generated script can be used in desired sandbox to synchronize the testing database with the production one.
To avoid deployment problems, caused by changes in production that didn’t come from source control, use SQL server comparison tool ApexSQL Diff. If there are any differences detected in production, it’s not recommended to make any further changes to the production database without testing them first.
How to script encrypted SQL database objects
One of the ways to keep stored procedure, function or view schema hidden is using the With encryption statements. In this way, access to objects’ DDL script can be locked, so that unauthorized users cannot see them:
April 8, 2013Create a database script from a backup without restoring it
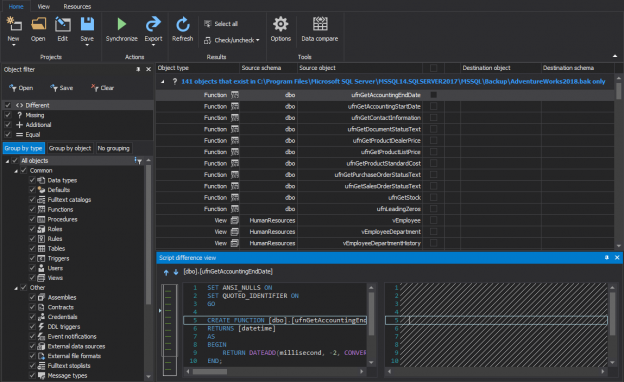
There are certain situations when creating a build script from a database is necessary – when a specific object (table, view, stored procedure, user, etc.) needs to be recreated or rolled back to a state it had earlier. If an online database doesn’t contain this object anymore or contains a newer version of it, the only places to look at are full database backups. If a database is versioned under source control, an object can be easily found there, but let’s assume that only SQL backups are available.
The most logical solution is to take a full database backup, restore it, and get what is needed and in most cases, this is the best and quickest solution.
This is a perfectly viable solution for small databases where backups take several hundred of MBs. For large databases, besides significant time needed to restore a backup, the lack of space on hard drives might be encountered as well. The time needed for a database restore depends not only on the backup size, but also on the server configuration and current load. The space needed is at least equal to the size of the full database backup.
ApexSQL Diff is a SQL Server database comparison and synchronization tool which detects differences between database objects in live databases, backups, snapshots, script folders and source control projects. Although it is most commonly used for comparison and synchronization, its features can be used to achieve some other tasks. Here is a simple trick used for this solution: comparing a data source such as a live database, a database in a source control system, a backup, or a snapshot to a blank destination will actually create a build script that creates SQL objects that exist in the source.
This means that with ApexSQL Diff there is neither the need for additional space on hard drives, nor the need to restore a database backup; at the same time a DDL script can be created for the selected object in the database. If there are any dependent database objects, they can be scripted too and will be created in a proper order.
The process is as following:
- Create a new folder. This is the folder where individual build scripts for each scripted object will be saved
- Start ApexSQL Diff
-
Click the New button in the Project management window:
-
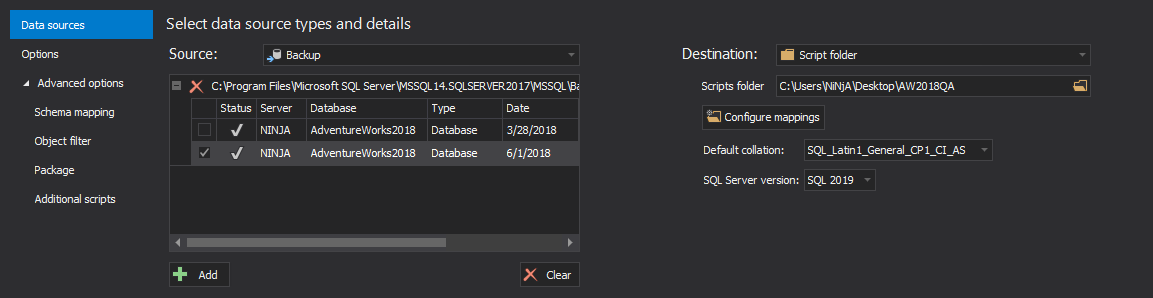
In the Source panel:
- Select Backup from the Source drop-down list
- Click the Add button and navigate to the folder where the backup file resides
- Select the backup and click the Open button
-
In the Destination panel:
- Select Script folder from the Destination drop-down list
- Click the Folder button to navigate to the newly created folder from the 1st step
-
Select the Default collation and SQL Server version for a DDL script that will be created:
- For additional object filtering prior to the comparison process, check out article on this link
- Click the Compare button in the bottom-right corner of the New project window
-
The objects read from the database backup are shown in the Results grid. As the destination script folder is empty, all objects are shown as missing:
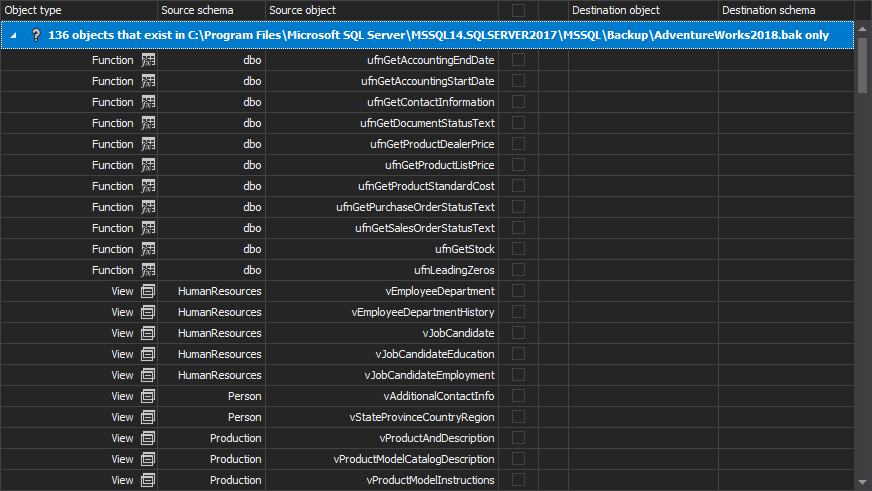
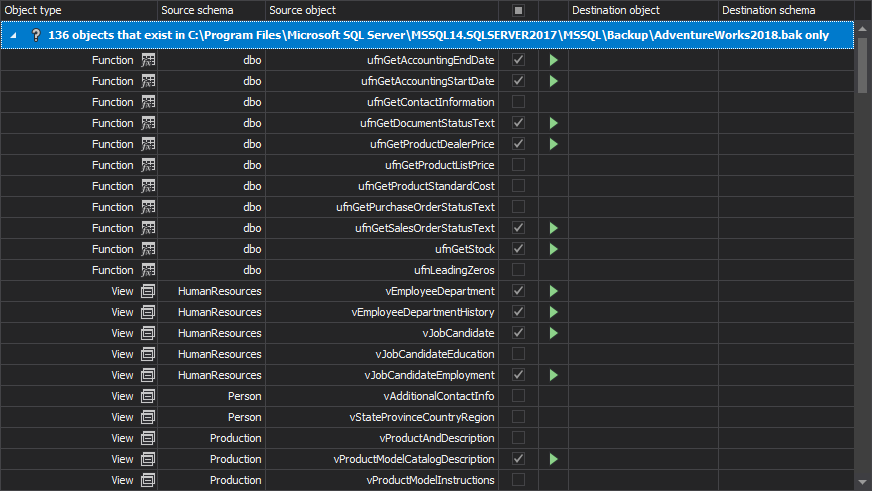
- Check the check-boxes to select the objects that need to be scripted:
-
On the Home tab, click the Synchronize button:

- In the Synchronization direction step of the Synchronization wizard, click the Next button
-
The Dependencies step shows the objects that the objects selected for synchronization depend on. By default, they are all selected:
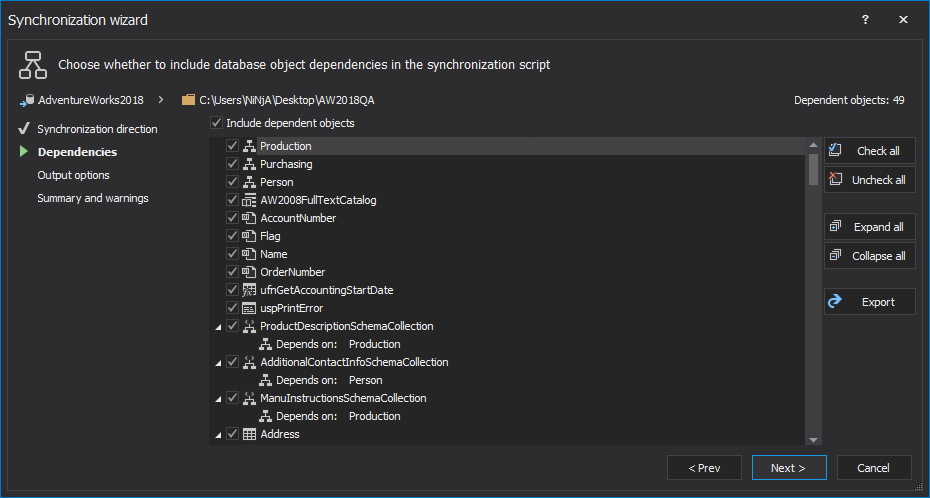
Uncheck the Include dependent database objects checkbox to avoid updating objects other than the ones selected in the Results grid.
-
In the Output options step, select the Synchronize to script folder as an output action to have a DDL script created in the script folder for each of the selected database objects:
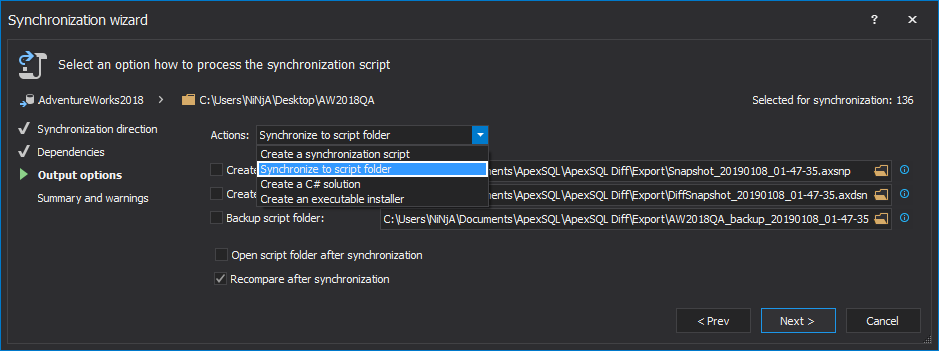
To create a single deployment script that creates all objects selected in the Results grid, select the Create a synchronization script output action:
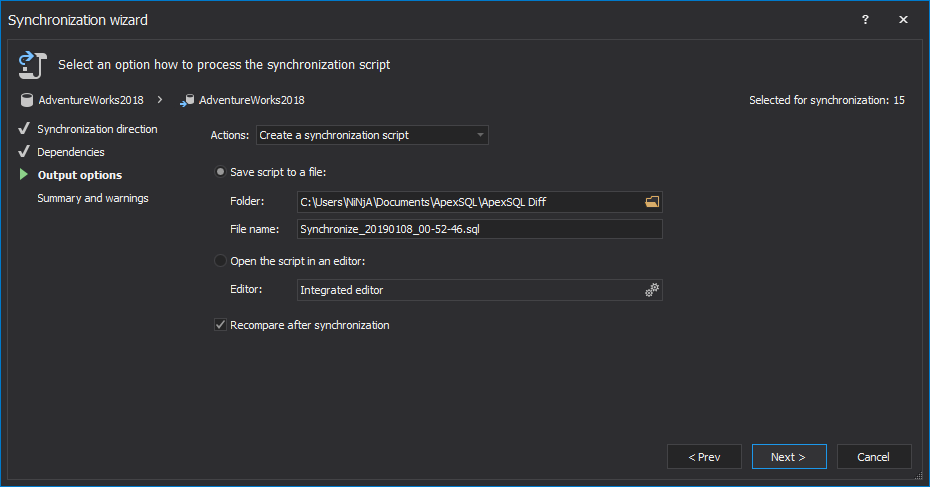
-
In the Summary and warnings step, review the order of the actions that will be made and click the Synchronize or Create script button:
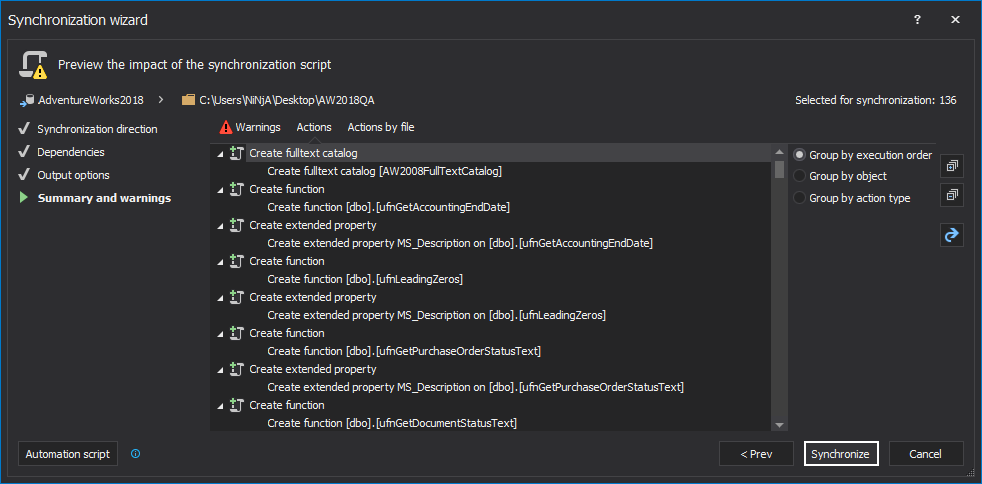
-
Depending on which output action was chosen, two buttons can be shown in the last step and the following will be done:
-
The Synchronize button – if the Synchronize to script folder action was chosen, separate sub-folder will be created for each object type has, such as Tables, Functions, etc. The database settings are scripted in the DatabaseSettings.xml file, saved in the specified script folder:
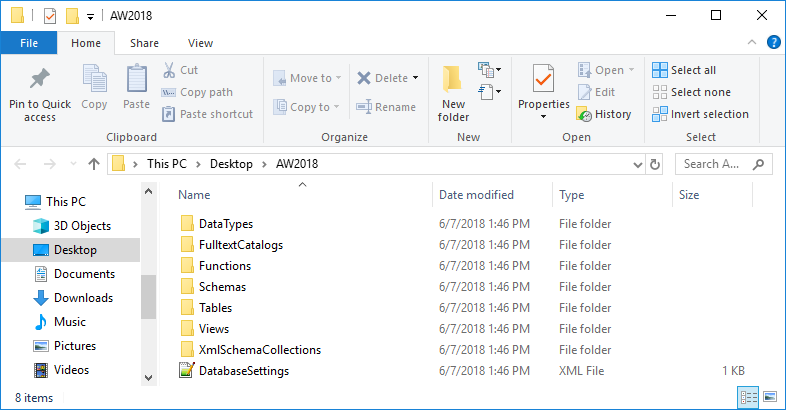
-
The Synchronize button – if the Synchronize to script folder action was chosen, separate sub-folder will be created for each object type has, such as Tables, Functions, etc. The database settings are scripted in the DatabaseSettings.xml file, saved in the specified script folder:
-
The Create script button – if the Create a synchronization script action was chosen, the created script will be created and it can be executed directly from the Integrated editor, with a click on the F5 key. If dependent objects are created, there is no need to worry which object will be created first; ApexSQL Diff determines the correct object creation order and generates the script:
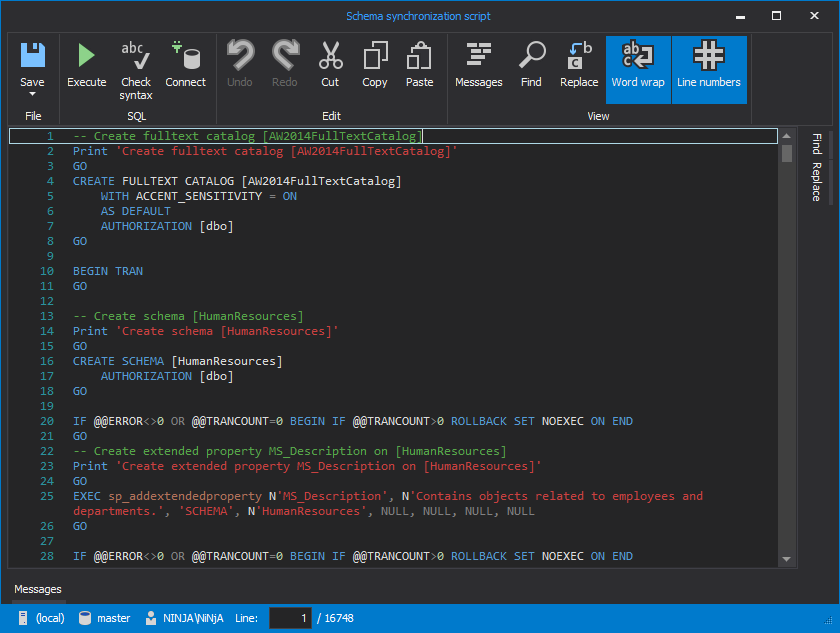
A database backup doesn’t have to be a black box accessible only when it’s restored to a SQL Server. Database comparison and synchronization tool – ApexSQL Diff can read its content without restoring it and thus help out to work with SQL objects stored in it.
Script a database for specific DML records only
Sometimes the best test data is the data in a live, production SQL Server database. Since using production data is most often not an acceptable option, this requires retrieving the data from a live database table and inserting it into a new table. The challenge arises if there is no need to insert all records from the original table, but only the records that comply with certain conditions.
April 5, 2013How to deploy SQL database on several different SQL Server instances and databases
When work on a database in a development environment is completed, developers are required to send the new version in for testing. If the testing is done on one or two machines – this is not a problem. However, if there is a need to test the new version on 10 or 15 machines (with different operating systems, SQL Server versions, or service packs installed), this can be tedious.
Another situation where scripts need to be executed on multiple servers is if there are many databases for different clients that were all derived from the same database and share many common objects. Any changes made in the development must be pushed to all users.
April 4, 2013How to recover a specific dropped object
Even with all precautions taken, mishaps with databases are still a possibility. Although it is good to be prepared for a disaster – the database is in the full recovery model and transaction log and database backups are created regularly, there are still some situations when a problem cannot be solved using an out-of-the-box solution.
One of these issues is restoring a single object. It’s not unusual to delete a SQL database object (e.g. a stored procedure) that is still needed, or modify it when the old version might be required later.
April 4, 2013How to automatically compare and synchronize SQL Server data
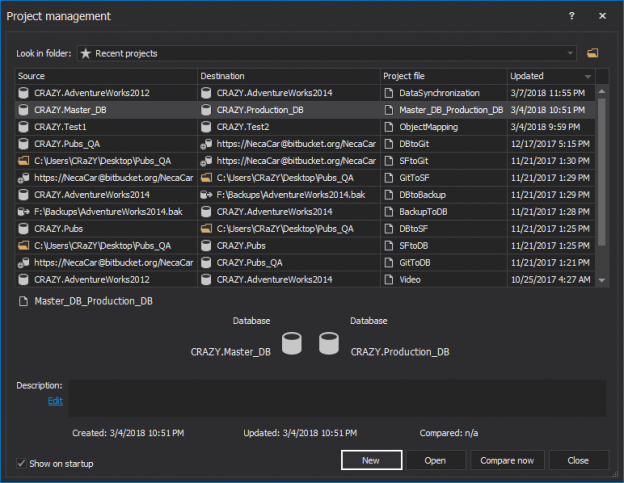
There are numerous scenarios when data synchronization between the two databases is needed, such as distributing data to different locations, integration of data from different locations into a central repository, or just a simple synchronization between a test and production database.
The recommended solution is to use database replication.
However, even with database replication there’s a need to check whether all the data is synchronized and to synchronize it if needed.
April 4, 2013Compare SQL Server database schemas automatically
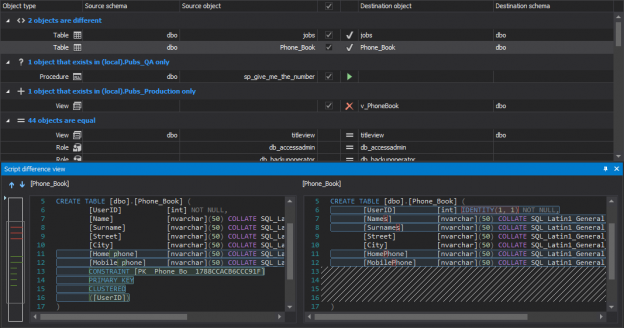
It’s common knowledge that running database changes directly in production, without thorough testing first, should be avoided.
If there are enough resources in the environment, there would be at least one testing and one production SQL Server instance. However, that introduces another challenge. When everything is set up in the test, and runs smoothly and as expected, how can it easily be applied to the production instance?
April 4, 2013Integrate source control with SQL Server to reduce database development time
Collaborating on database development introduces a series of challenges. For instance, having the development team change the tables, views, stored procedures and other objects in a single, shared database, although intuitive, can introduce severe issues down the road as valid changes can be lost or overwritten by an unsuspecting teammate. This issue might be mitigated by restoring a database backup – under the assumption a valid backup exists. Even if it does, overwriting the development database with a backup means losing all of the valid database changes that have occurred since the backup was taken; not to mention the fact that restoring a large backup can take time – during which none of the developers can work on the database being restored.
April 4, 2013Using SQL database backups instead of live databases in a large development team
In scenarios where a development project of a large scale is being completed, DBA skills can really be put to the test. Due to the nature and the dependencies of the software which is being developed, it’s not uncommon for the DBA to be in charge of dozens of environments, used by multiple development teams working on different aspects of the project. In some cases, this scale of development doesn’t only require for multiple SQL Server instances to be set up across environments – more often than not it requires different versions of SQL Server to be accessible across environments as well
April 4, 2013How to quickly search for SQL database data and objects in SSMS
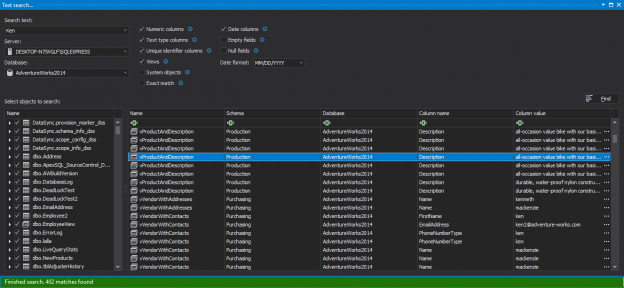
Frequently, developers and DBAs need to search databases for objects or data. If a database function that contains a specific table column or a variable name, or for a table that contains specific data is searched, the simple solution for finding those values, does not exists.
April 4, 2013SQL Formatting standards – joins, lists, structure, operations
The first part of the series – SQL Formatting standards – Capitalization, Indentation, Comments, Parenthesis, explains the importance of having clean SQL code. In short, deciphering someone else’s code is time-consuming. Clean and neat SQL code can be read faster; SQL reviewing and troubleshooting is more efficient; joint development efforts are more effective; handing off projects from one team to another is smoother than for inconsistently written SQL.
As there are neither style nor standards to format SQL, it’s up to the team to create its own set of formatting standards. Here are some recommendations to format joins, value lists, code structure, arithmetic, comparison and logical operations.
April 4, 2013





