



If only schema changes are made in the source control repository, a 3rd party tool – ApexSQL Diff can be used to perform the schema synchronization. ApexSQL Diff is a tool that can be used to compare and synchronize schema differences between live SQL database, source control repositories, database backups, script folders and ApexSQL snapshots. It can handle any dependencies, triggers, etc. and create an error-free synchronization script, while ensuring a database integrity.
January 13, 2017How to automatically process SQL Server databases with Unit tests
In order to begin this process, first the tSQLt, (SQL Server database unit testing framework) has to be installed on the database which will be used for unit testing. This can be done manually in SSMS by right-clicking the selected database in the Object explorer, find the Unit tests menu and select Install tSQLt.
January 13, 2017How to automatically create synthetic test data for a SQL Server database
ApexSQL Generate is a tool that can populate SQL databases with test data using multiple generators for each column. It supports a full range of SQL data types and has an ability to recognize them in a loaded SQL database and provide real-world test data based on contained data types. It can generate: randomized test data using the Random generator and various options, and using the Regular expression generator, sequential data using the Incremental generator, and much more.
January 13, 2017How to automatically build a database from SQL Server source control
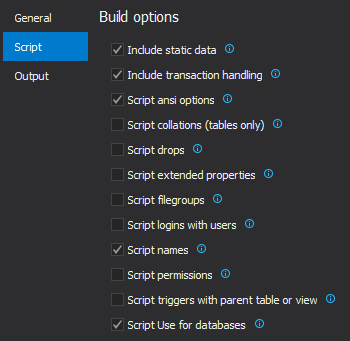
ApexSQL Build is a tool that can build a new SQL database, update an existing SQL database, and consolidate scripts. Additionally, it can deploy databases directly from the source control repository, create C# solution or executable installer, and build SQL databases from scripts, ApexSQL snapshots, or script folders.
January 13, 2017How to commit database objects to SQL Server database Source control
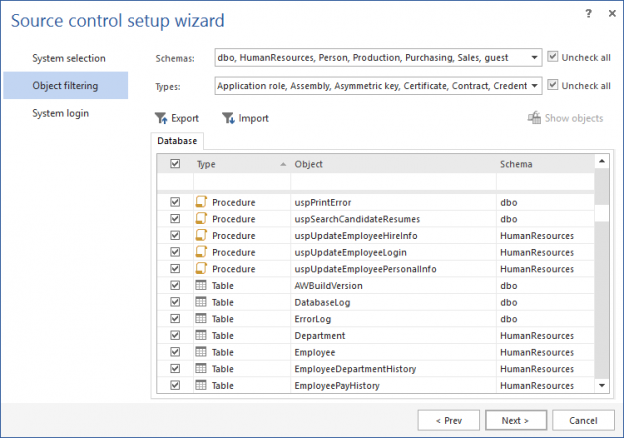
Before proceeding with committing database changes, a database first needs to be linked to the source control repository:
January 13, 2017How to automatically trigger a SQL Server database CI and/or delivery process on a new commit
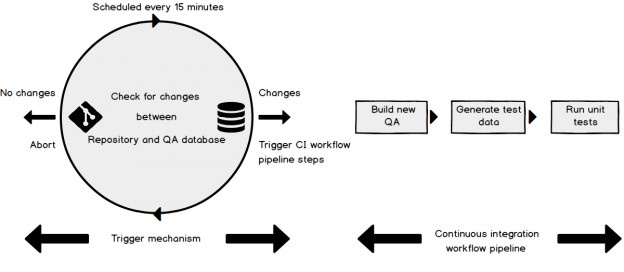
Once you have your continuous integration (CI) and or continuous delivery (CD) aka Database lifecycle management process built, configured, successfully testing and ready to roll, the next decision point is when to run it and how.
January 13, 2017How to monitor SQL Server failover events automatically
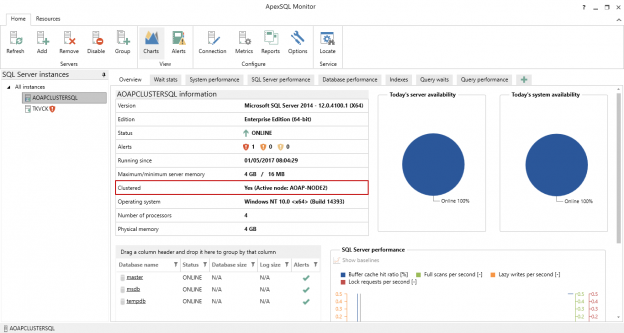
Failover event overview
In general, the term “failover” refers to switching from a previously active machine, other hardware component, or network to a passive (or unused) one, to sustain high availability and reliability. In most cases, a failover event is an automatic process, while a the similar event, switchover, requires manual intervention in switching between the active/passive elements.
January 13, 2017How to work with version controlled SQL Server database static data
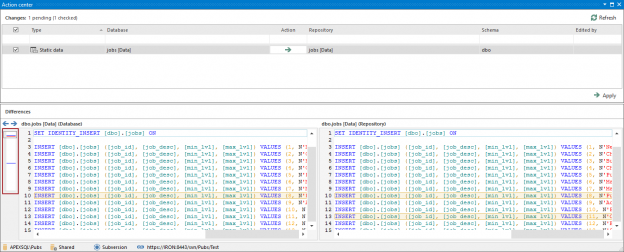
Challenge
When working with SQL Server database static data in the context of version control, there are several key requirements.
January 12, 2017How to automatically monitor a SQL Server database for schema changes and create an audit log in source control
The challenge
As a DBA considering version controlling a database, there are a lot of challenges to setting up the team with software to check in changes, to manage the development environment (shared or dedicated models) and set the rules of the game – locking vs not locking etc. But before committing to this fully, a potentially preliminary stage would be to set up a centralized system, where the database was automatically committed to source control each night. This could be done by a single person and wouldn’t require developer participation or even knowledge.
January 10, 2017How to build a “smart” SQL Server Data dictionary
In the article, “What is a data dictionary and why would I want to build one?” a data dictionary was described and compared to other alternatives to documenting, auditing and versioning a database. The article also described the difference between a Dumb and a Smart data dictionary.
Now that we’ve whetted your appetite, this article will explain how to create a smart data dictionary using XML schema change exports from ApexSQL Diff.
January 10, 2017How to automatically keep two SQL Server database schemas in sync
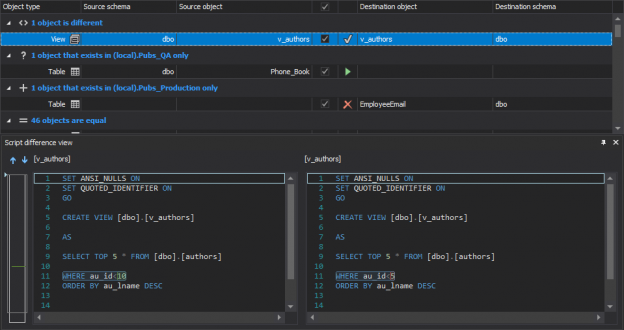
Challenge
When working on a SQL database development, there is sometimes a requirement to keep two databases in sync. For example, in a development environment there is a need to automatically synchronize changes with a QA database frequently, so that tests can always be run on the most recent version. The implemented mechanism should handle this by detecting a specific schema change in the DEV database and automatically synchronizing with the QA database, fully unattended and on a schedule. The whole process should be run unattended and to be fully automated and the databases will be updated in near real time as we’ll schedule the process to run every 15 minutes.
January 9, 2017How to keep a source control repository updated with the latest SQL Server database changes
One of the challenges SQL Server development teams face is whether to version control a database and if so how to keep the development database in sync with the source control repository.
January 9, 2017How to automatically monitor SQL Server availability
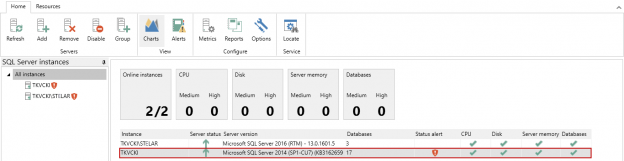
SQL Server availability overview
The core component of SQL Server is the Database Engine service. It is identified with the Windows service named MSSQLSERVER (sqlservr.exe) for the default instance, and for the named instance, the customized instance name is appended to the name of the service, e.g. MSSQLTESTDEPT.
January 5, 2017How to see the full version history of a SQL Server database object under source control and, if needed, revert changes
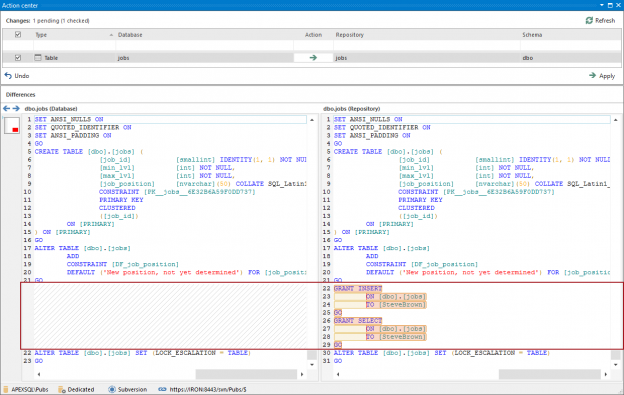
Challenge
One of the main benefits of a SQL database version control is that any version of an object committed to the repository, is available through the revision history. With that being said, browsing the history allows seeing all versions of the specific database object, committed over time, and reverting any version from the history in order to apply it against a database. By utilizing such functionality, a database can be brought back to a working state in case some change caused a problem
December 30, 2016How to link and initially commit SQL Server database static data
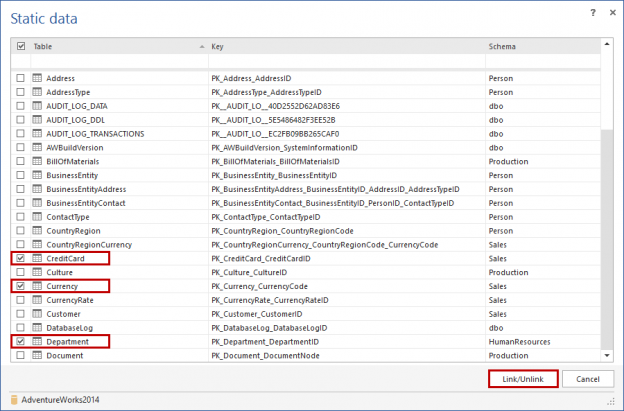
Challenge
Non-transactional data in tables that is never (or rarely) changed, for example currency codes, postal codes or personal ID numbers, is often referred to as “static data” (also known as lookup or reference data). Although static data isn’t part of the database schema, it can be thought of in much the same way. Simply creating test data for static tables, for testing purposes, may allow the tests to be successfully executed, but often won’t render meaningful looking results and in some cases, could result in failure, if the static data was tightly coupled to application/database function. Static data tables also tend to be much smaller than transactional tables.
December 30, 2016How to programmatically monitor system availability
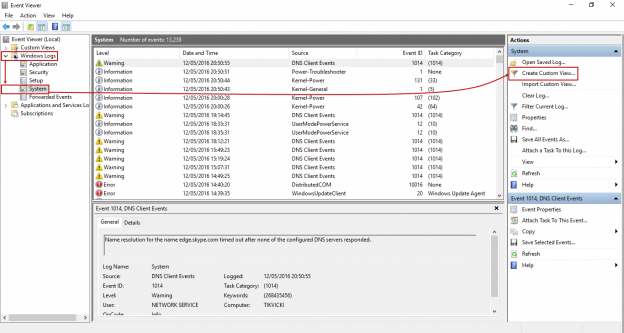
System availability overview
Overall stability and availability of a machine in a specific time range is usually called system uptime. This measurement represents a period (sometimes percentage) when the system is stable and performing without unattended reboots, except for maintenance and administrative purposes, and works without issues. The opposite, system downtime is a period when machine is turned off (on purpose), or encounters experiences problems that result is the system being unavailable to users and processes. The combination of these two measurements is called system availability which is both identified and tracked with Windows Event Viewer (System Log).
December 23, 2016The process of elimination: How to analyze SQL Server performance with baselines and wait statistics
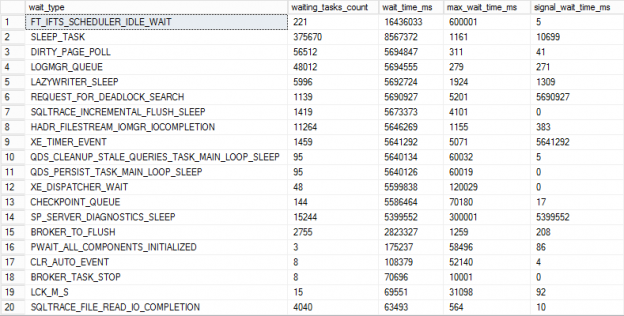
Wait statistics = Data
SQL Server’s built in abilities to track query execution via wait statistics is critical to resolving performance problems. Wait statistics or response time analysis are metrics that provide the ability to measure the time needed for the database to respond to executed queries. It doesn’t simply represent the time needed for a query to complete execution, but the wait statistic is also the measurement of the time the query has taken for each step in its execution. That information becomes the basis for identifying bottlenecks that are affecting the execution time.
December 20, 2016Getting a database under version control: How to link a database to source control and initially commit objects
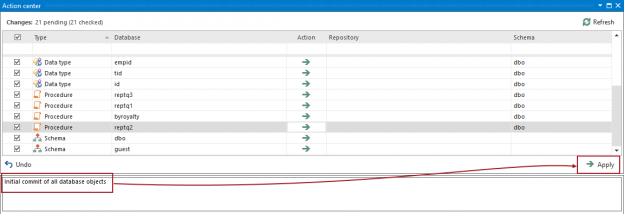
Challenge
For the purpose of versioning a SQL database, there should be a mechanism that allows for quickly linking a database to an existing or to a blank repository and to initially Commit all database objects, or at least a set of objects that needs to be versioned.
December 16, 2016How to commit and/or update SQL Server database static data to a source control repository
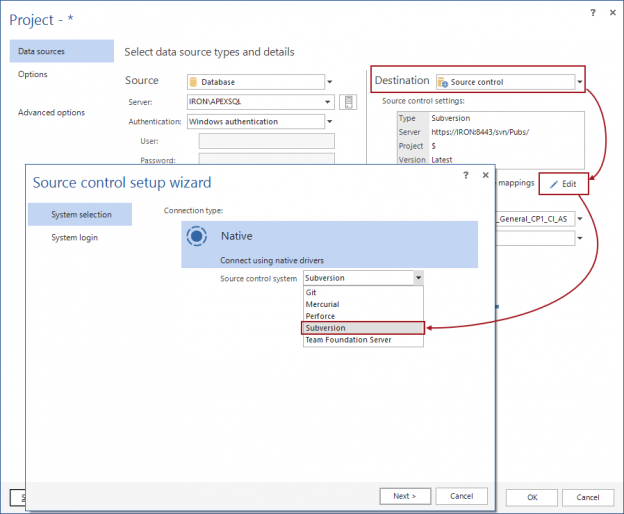
Challenge
In order to version static data, just like database objects e.g. Tables, a mechanism needs to be created to identify only those tables designated as “static” (see below) and to come up with a reproducible process, that will Commit the data in these tables to source control. This article covers this process
December 14, 2016Techniques to identify blocking queries and causes of SQL Server blocks
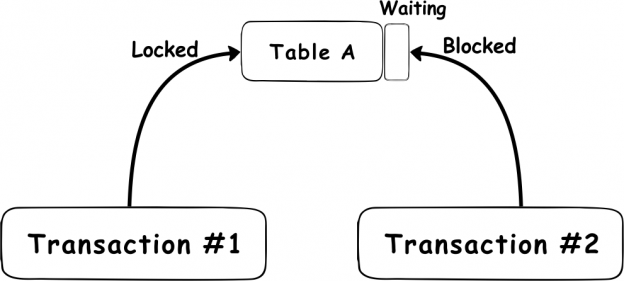
Blocked processes caused by locks on database objects are a common issue. Locking ensures the integrity of data stored within databases by forcing each executed SQL Server transaction to pass the ACID test. which considers that every transaction must meet the following requirements:
December 12, 2016





