Introduction
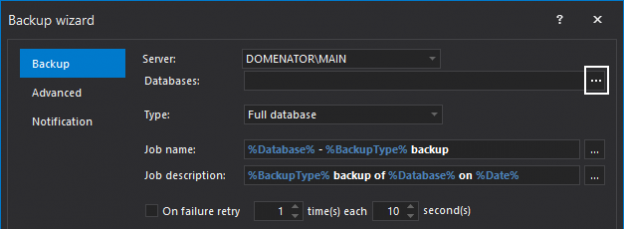
One of the main tasks for every database administrator is creating a reliable disaster recovery plan. The plan always includes multiple backup and restore operations. Usually, opting for conventional, single-file backups should suffice, but in some cases, resources like disk space, backup time, or both could be the issue. This is usually the case when working with large databases.
May 6, 2016