



In various scenarios, DBAs need to write T-SQL queries to check numerous states of their respected SQL Server instances. These queries can be run separately or with a fairly large amount of time invested in optimizing and modifying each one to run as a single power-query that will check a variety of conditions. On top of the time invested in creating such a script, additional time will be required to modify it and add new checks which can cause the whole script to break.
June 18, 2020How to perform a high-level analysis of remote SQL Server instances
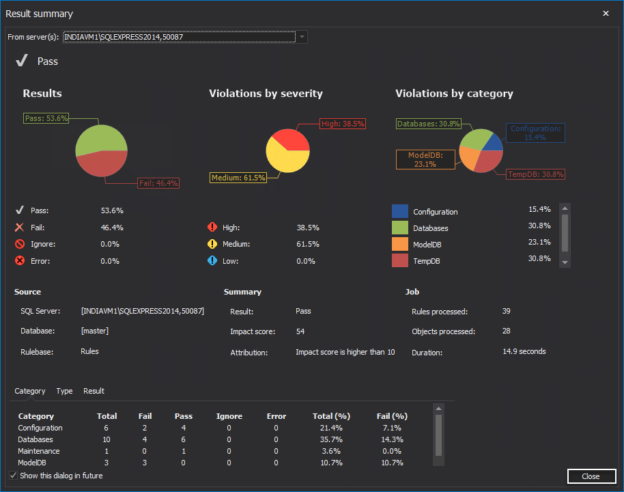
To a proactive DBA, it might be of crucial importance to have its SQL Server instances regularly checked for possible issues as there certainly are the multiple benefits to be gathered from this practice. At the long run and when not addressed timely, these issues might cause a major disaster, slowing or stoppage of production SQL Servers causing an enormous headache to everyone involved, and not to mention the cost of having the production environment down for a few hours or, god forbid, days.
June 10, 2020How to ensure continuous auditing and reporting in SQL Server
Challenge
Organizations are loaded with regulation requirements to audit and report on data access, data changes, login attempts, malicious and inadvertent activity to easier raise awareness on any anomaly behavior, and repeatedly improve controls while eliminating any potential risk-related consequences.
June 1, 2020How to search for column names in SQL Server
How to export MySQL data to CSV
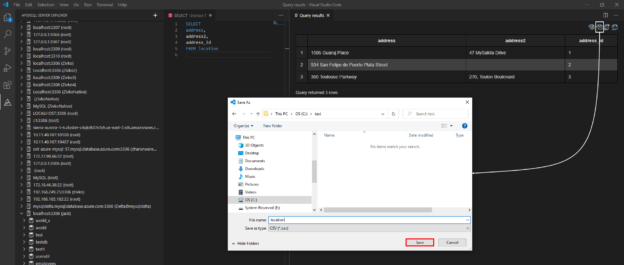
Many database developers want to export MySQL data that they got as the results of an executed query to a CSV, XML, JSON, or HTML file.
May 21, 2020How to perform non-database automated tasks in a database continuous integration pipeline
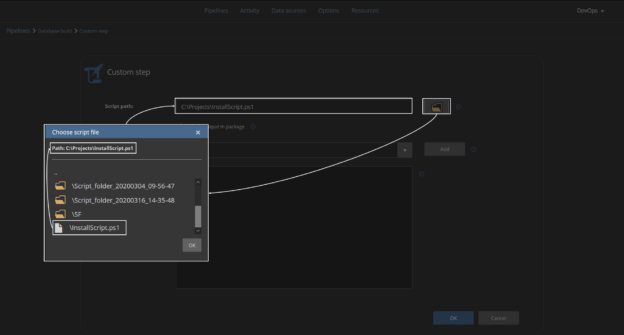
Challenge
In the DevOps world, it is a common practice to set up database continuous integration solutions for project deliveries, with as many steps included in a single workflow as possible. For the SQL Server project types, most of the database continuous integration and continuous delivery use cases are covered with ApexSQL DevOps toolkit solutions, including both standalone and continuous integration servers plugins. Multiple tasks, including building, testing, and deploying SQL database code, can be done through a single pipeline, but the question remains if there is a possibility to perform some non-database project-related tasks within the same pipeline, i.e., without the need for additional intervention.
May 18, 2020How to protect sensitive data in SQL Server
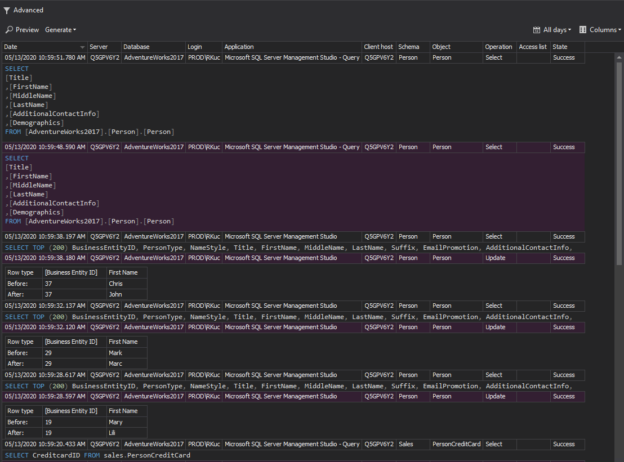
Protecting business data is a relentless task and brings various consequences when mishandled. True costs on security breaches may result in regulatory fines – that are amplified over time, which may result due to non-compliance and also customer confidence. In the process of protecting “something”, the key component is knowing what is that “something” before protecting it, so what is sensitive data after all?
May 15, 2020How to create a database auditing trail
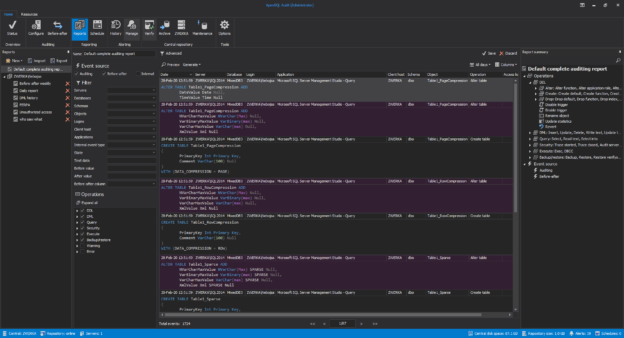
Database auditing has become essential as the compliance regulations requirements and fines have amplified. It is important to address the questions not only on who and when accessed the data in your system or how the data has been changed but also how to prevent data breaches from inappropriate actions performed by different users.
May 6, 2020How to ensure tamper-proof auditing in SQL Server
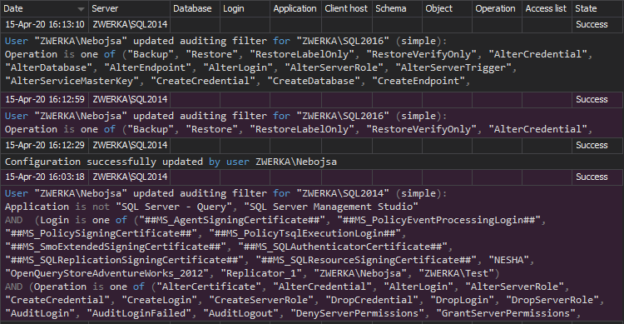
Inability to ensure tamper-proof auditing is a major flaw of many SQL Server auditing solutions available on the market. While there are many solutions and different tools that utilize different mechanics to provide the information on who saw or changed what, when and how, most of Microsoft’s own, as well as the majority of third-party solutions do not provide any mechanisms or features to protect the audited data or to achieve tamper-proof auditing. This immediately raises a red flag because many internal, as well as external auditors, make it a mandatory requirement for auditing solutions to be able to provide certain levels of data protection for the audited data as well as a self-auditing mechanism for the solution itself, which will ensure that the auditing reports for auditors are 100% genuine and that audited data can be identified as true, untampered and uncorrupt.
April 24, 2020How to compare SQL Server database schemas
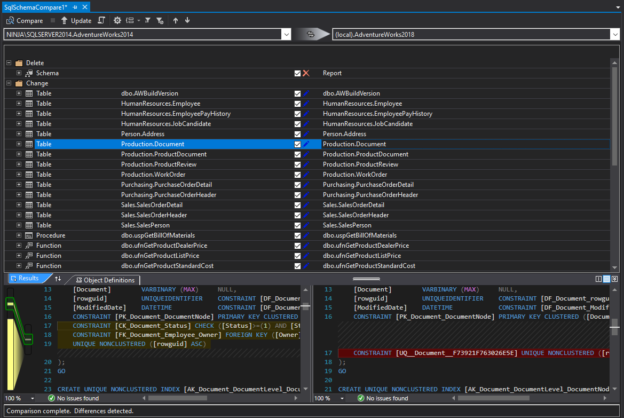
Scenario
When working in a development environment, developers often use Visual Studio for coding, and it also has an option to connect to SQL Server and open a query window in which they can work on creating new objects or updating existing objects directly on their local Dev database, which further requires a way to compare SQL Server database schemas with the QA database.
April 9, 2020How to monitor the status of index defragmentation jobs
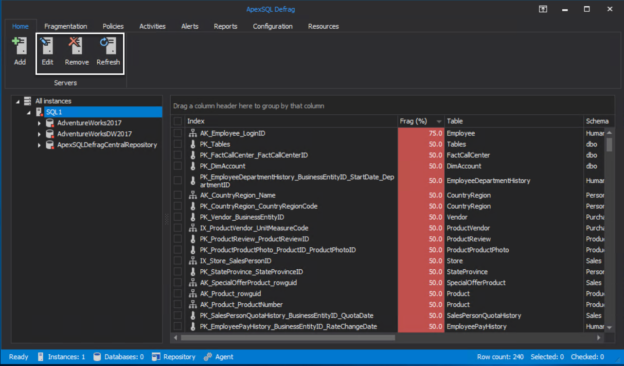
SQL Server Index is one of the most important factors in the SQL Server performance tuning field that is used to enhance the queries’ performance by speeding up the data retrieval process. It is a double-edged sword that can enhance the database performance when designing it properly and performing the index defragmentation maintenance periodically, and degrade the database performance when it is not designed or maintained well.
April 7, 2020Top features you need in a SQL Server transaction log reading solution
Challenge
While a plethora of information on changes made to a database is recorded in transaction log files, SQL Server transaction log reading has always been a big challenge for all SQL Server users since Microsoft never offered a built-in solution which would allow users to immerse themselves and explore the depths of transaction log files. Furthermore, lack of in-house features that would help understand, process, or analyze information within the transaction log files practically made it mandatory for users to turn towards 3rd party solutions.
April 3, 2020How to get a list of available SQL Server instances on your local network
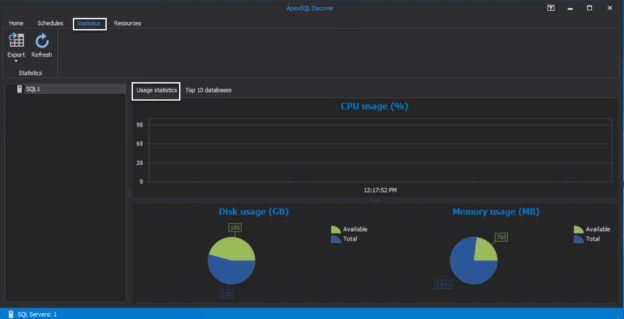
In this article, we will show how to use the ApexSQL Discover tool to list all available SQL Server Engine, SQL Server Reporting Service, SQL Server Integration Service, and SQL Server Analysis Service instances that are installed in the current domain, remote domain or a specific IP addresses or TCP ports range.
March 27, 2020SQL dependency viewer
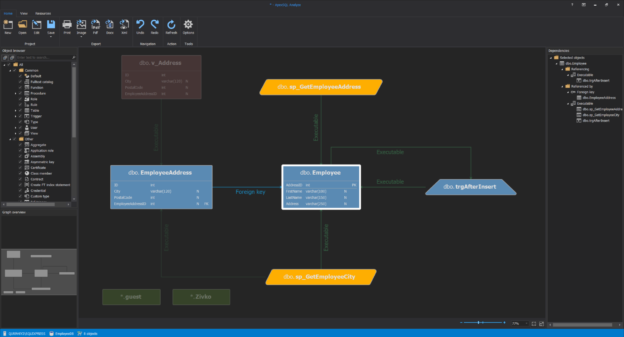
In the relational SQL Server database systems, objects can have different relationships (SQL dependency) with each other. Objects such as views, stored procedures, functions can depend on other objects and understanding SQL dependency between objects can be very important in situations when there is a need to update or delete objects that depend upon other objects.
March 25, 2020How to mask data in SQL for multiple columns and tables
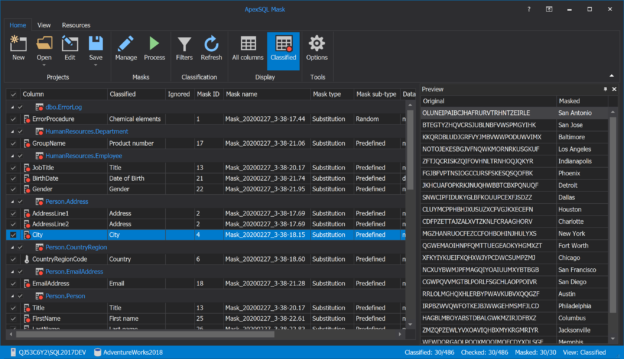
Working with sensitive data raises the need to protect them at all costs. Even though there are many ways to do that, all of them can be time-consuming.
March 16, 2020Audit SQL databases using a SQL Server trigger tool
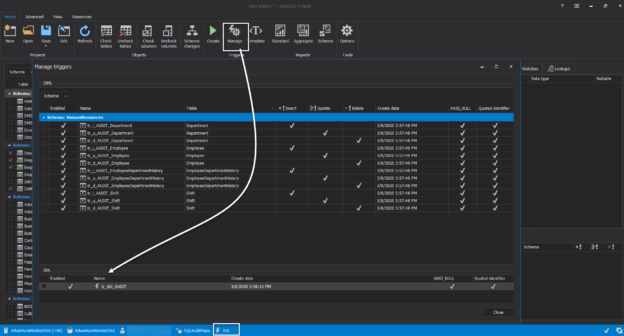
In this article, we will show how to use the ApexSQL Trigger 3rd party tool to audit your SQL Server Database DML and DDL changes, by creating SQL Server Triggers on the audited tables.
March 13, 2020How to easily pass SQL Server audits
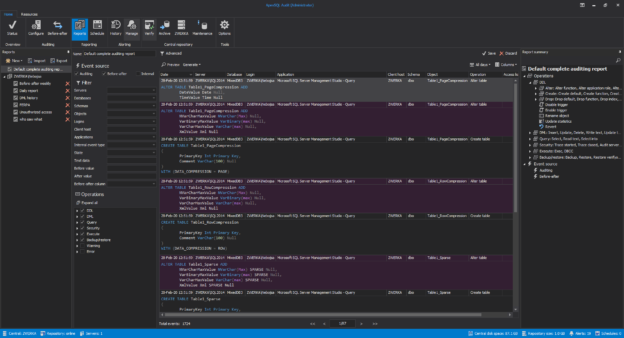
Internal and external audits are becoming a mandatory requirement in companies world-wide, SQL Server audits included. There are many global auditing compliance standards like HIPAA, GDPR, PCI, which require companies to audit numerous events, including data changes, access and more. Furthermore, internal management and auditors often come up with additional auditing requirements, of which, the following are the most frequently represented requirements when performing SQL Server audits:
March 4, 2020Use MySQL information_schema to perform object search
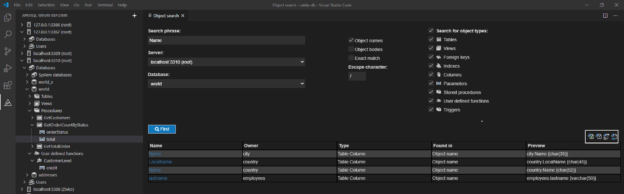
In this article, it will be shown how to find objects using the MySQL information_schema database and retrieve information related to that specific object. In the second part of the article, 3rd party tool will be introduced, ApexSQL Database Power Tools for VS Code and its search capability.
February 28, 2020SQL Server extended properties
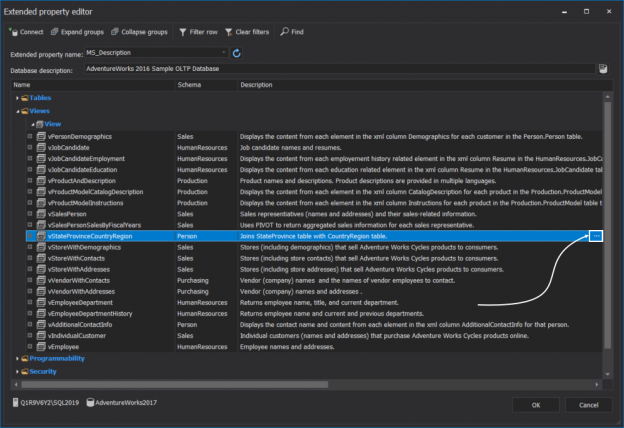
SQL Server extended properties feature can be very handy in SQL Server because it allows us to store additional information about SQL objects. Developers often need to store information about each SQL Server objects, like information about stored procedures, what those procedures do, etc. which is also a way to create a self-documenting database.
February 21, 2020How to format SQL code in SQL Server Management Studio
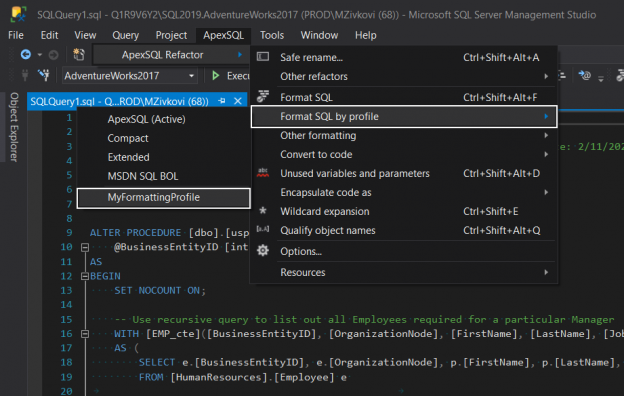
This article will describe how to format SQL code using SQL Server Management Studio (SSMS) native options and how to format SQL code using a third-party SQL formatter tool.
February 20, 2020





