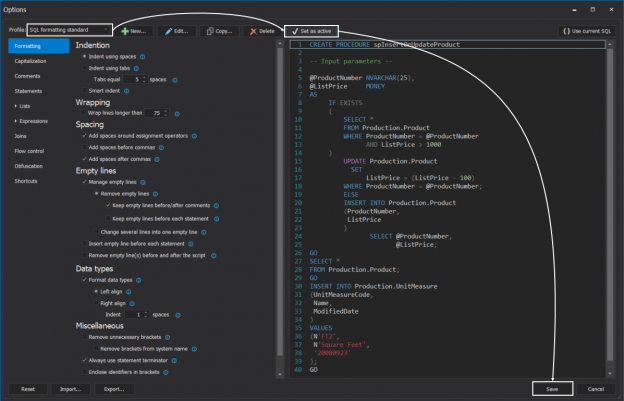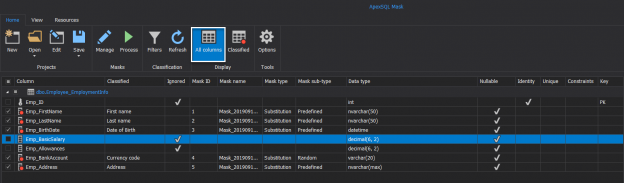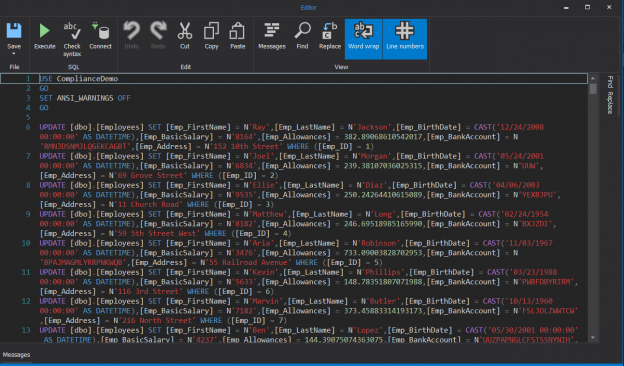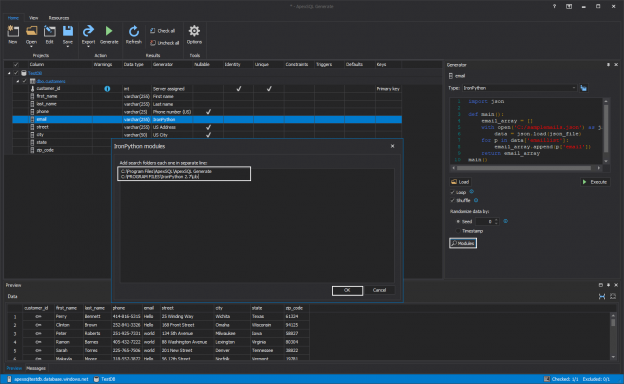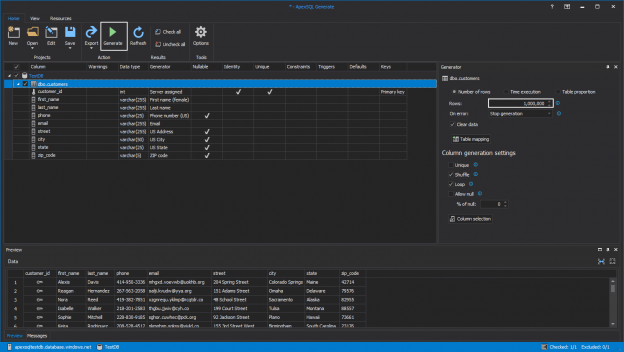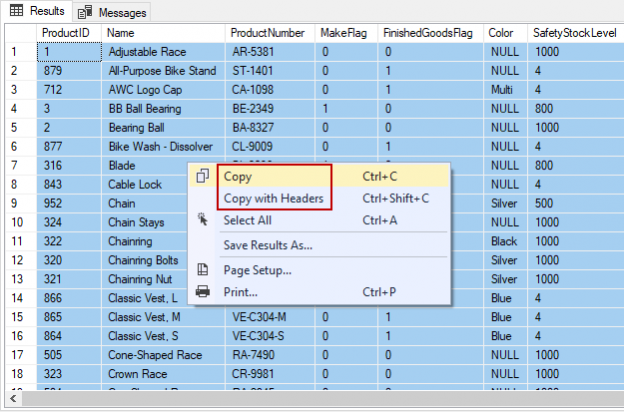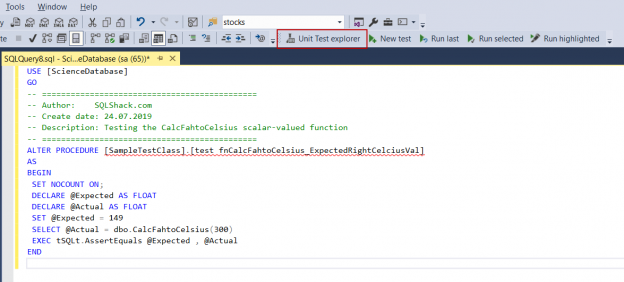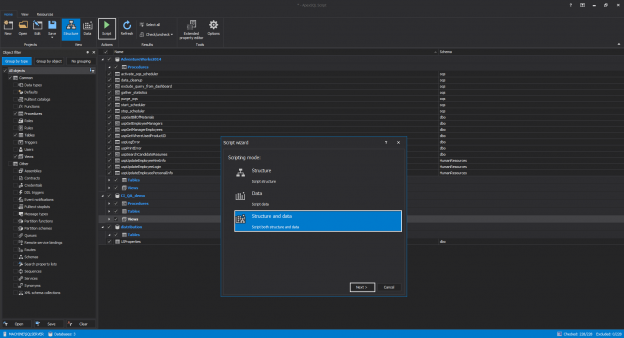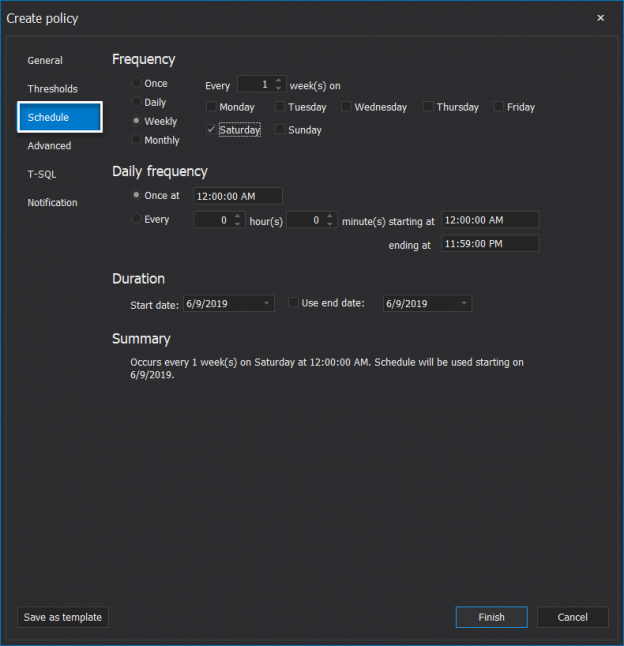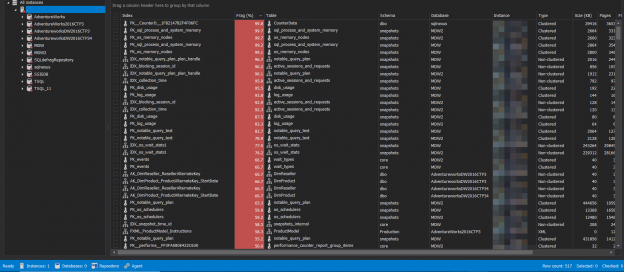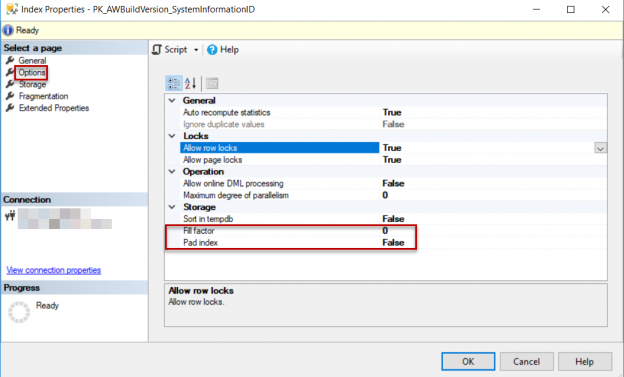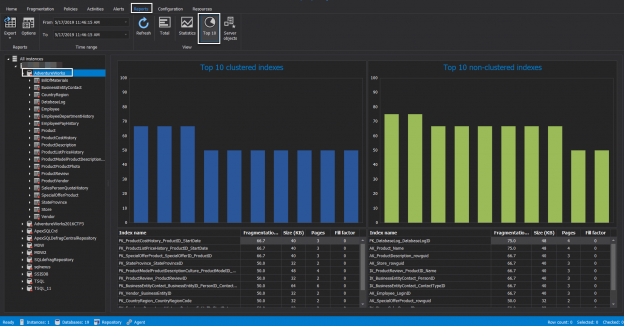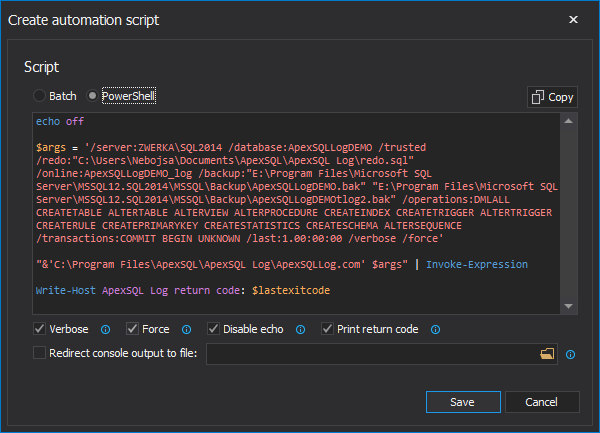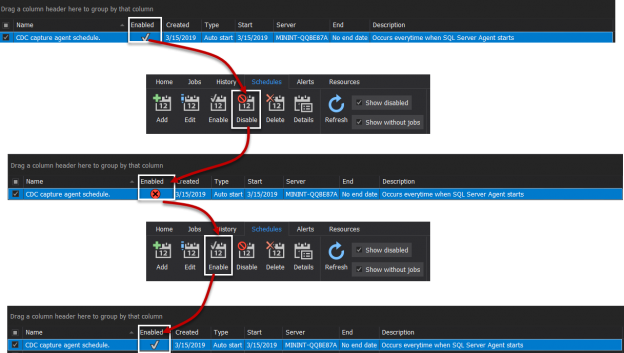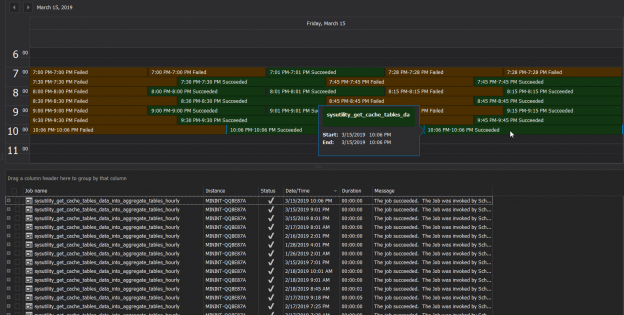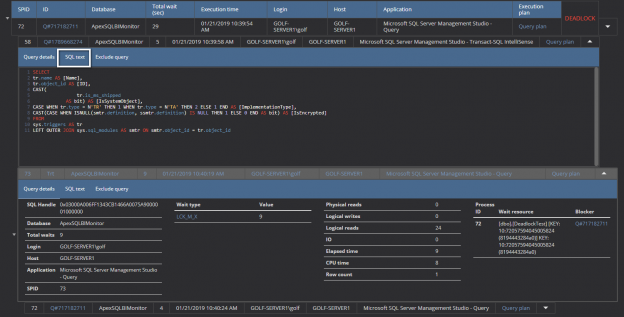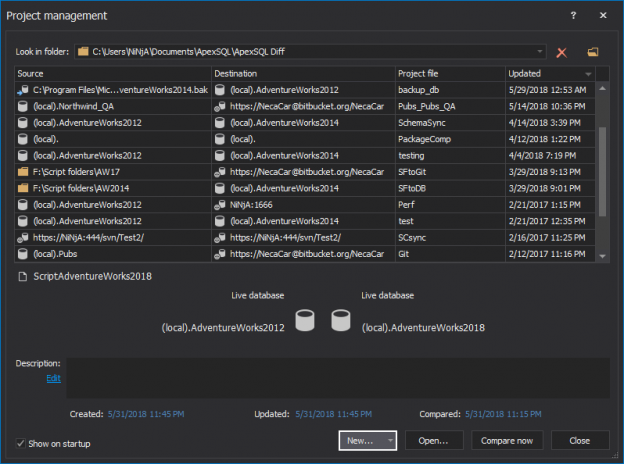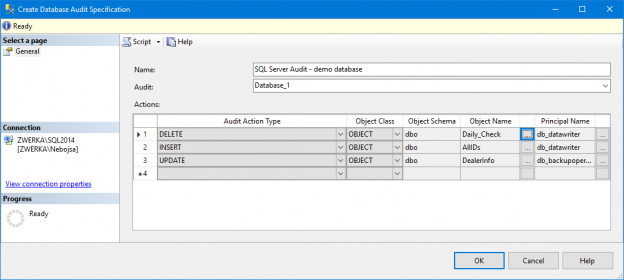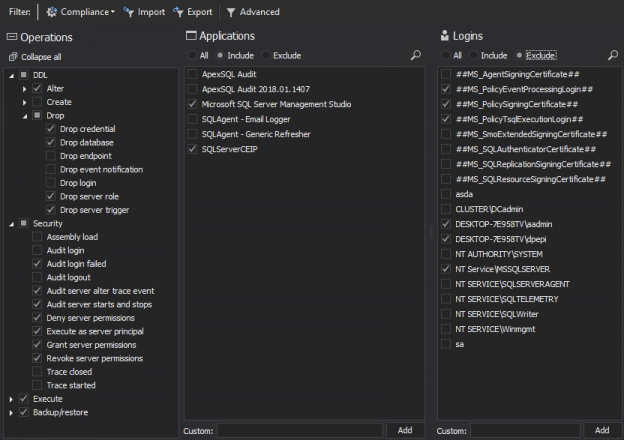
There are many SQL Server auditing solutions available on the market since the audit requirements are building more and more. Over time, we can see the increased number of both internal and external compliance standards which impose numerous auditing requirements for different business areas and models. More often than before, companies have to ensure they comply with two, three or even more SQL Server auditing standards at once, making it paramount to equip themselves with powerful and versatile auditing solutions that will allow many different features and ensure compliance with present requirements.
February 4, 2020