To a proactive database administrator, SQL Server Agent is one of the main tools to monitor different activities continuously happening in SQL Server instances.
February 28, 2019



To a proactive database administrator, SQL Server Agent is one of the main tools to monitor different activities continuously happening in SQL Server instances.
February 28, 2019
This article will review how to get information on your backup SQL database history, including the metadata in MSDB that can be queried, as well as value-added tools and features to group, sort, report, and export this critical information
February 26, 2019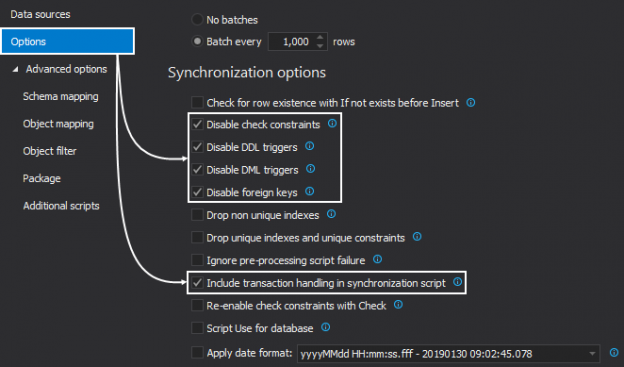
This article will provide an overview of automating the comparison and synchronization the data between a SQL script folder and a live SQL Server database
In the article on how to automatically compare and synchronize SQL Server database objects with a shared script folder, a “poor man’s source control repository” was explained. It was shown how to set up a SQL script folder on a shared network location, in order to “mimic” the work on a SQL source control repository, where all developers will commit their changes, without any cost concerns.
February 7, 2019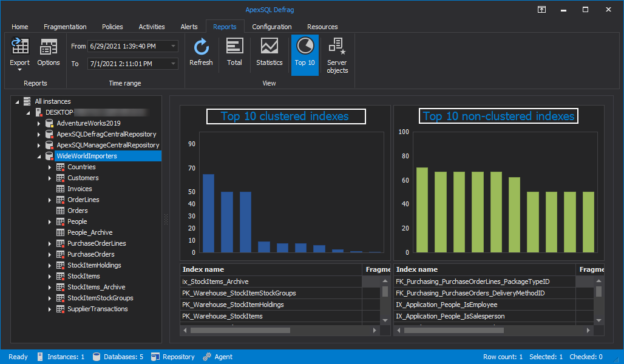
One of the most critical variables for database performance is SQL index fragmentation. If the fragmentation level is not managed properly, blockages, jams, IO problems, and disk ejection problems can occur. A high level of index fragmentation can also lead to improper execution plans.
February 6, 2019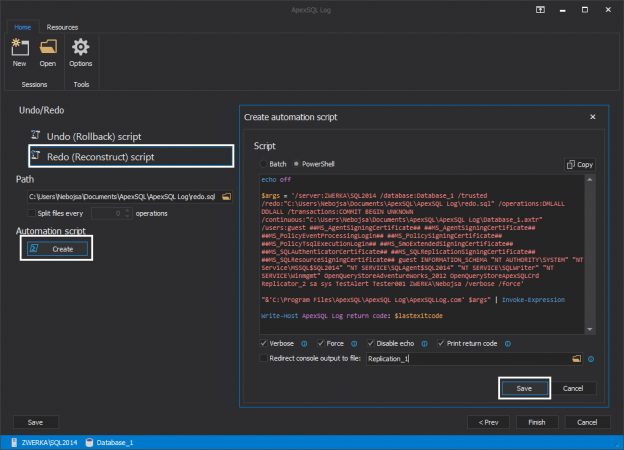
This article will cover using a 3rd party transaction log reader for setting up a bi-directional SQL Server replication implementation
February 4, 2019This article will provide an overview of ad-hoc query use in SQL Server, the potential resulting problems as well as how to detect and remediate them.
February 4, 2019
One of the challenges when working with SQL source control systems is to have a sort of a “safe mechanism” that will allow developers to revert any changes made on the destination database. That kind of “mechanism” are source control labels, which are basically snapshots of the SQL source control repository captured at specific time where each object is saved as individual SQL script.
February 4, 2019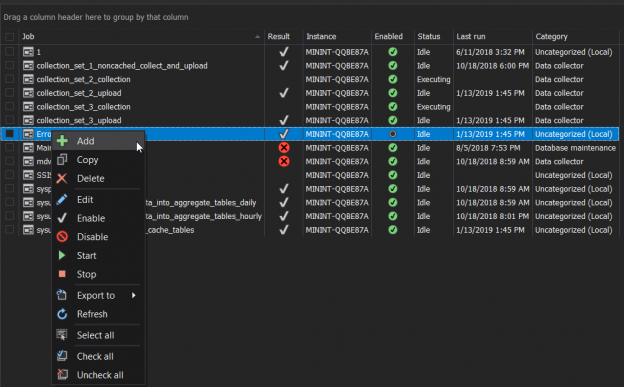
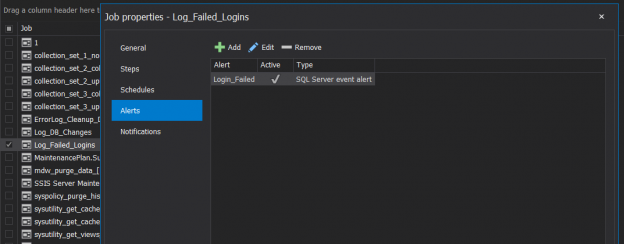
This article will cover SQL Server Agent capabilities and features as well as tools to extend and enhance these core capabilities.
SQL Server provides us with the ability to schedule the different types of administrative tasks, in order to execute it automatically with customizable configurations. These tasks can be simple queries, database maintenance tasks, such as database backup, integrity check, re-indexing or statistics update, command prompt application, Microsoft ActiveX script, Analysis Services command or complex SQL Server Integration Service Packages. The Windows service that is responsible for scheduling and executing these tasks is called the SQL Agent Service.
January 17, 2019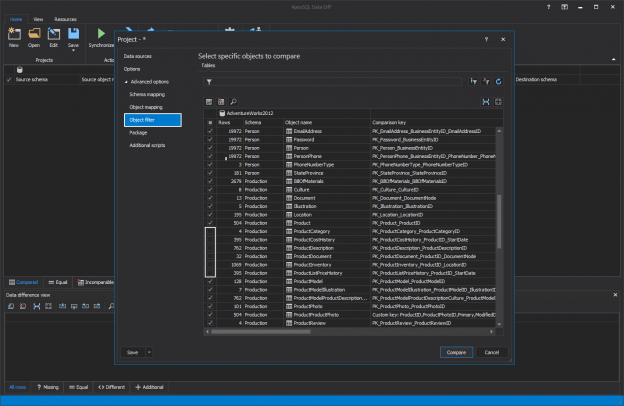
This article will describe a quick, no-coding approach to automating SQL Server database synchronization via a continuous integration.
November 29, 2018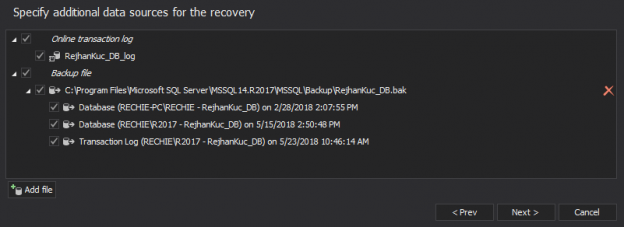
When a disaster hits, recovering lost data and structure is usually paramount. With ApexSQL Recover, the information inside the database (MDF) and transaction log (LDF) files is leveraged in order to create recovery scripts or to perform recovery tasks directly into a database and negate the data/structure loss. Once the recovery task is initiated, inadvertent or malicious changes can be identified, including the who made them and when, and then rolled back to the original state before they were ‘damaged’. Additionally, in many situations users need to extract information from huge backup files which is not always an easy task, and this is where ApexSQL Recover comes into play and simply extracts the data or structure from the backup without requiring or using a tremendous amount of resources used by the restore job which would otherwise be required.
November 2, 2018One of the most common tasks for ApexSQL Log is to be used as part of a post-incident investigation, usually involving inadvertently or maliciously changed or damaged data to determine who made the changes, what exactly was changed, when and how. With ApexSQL Log, users can dig into the transaction log files and see the exact values before and after the change has occurred as well as review the complete history of changes on the affected rows.
August 24, 2018
Prevention is one of the most powerful approaches against any inadvertent or malicious events. But it is not always possible to prepare for all different calamities which may take place in SQL Server environments. Inadvertent changes, SQL injection attacks, malicious manipulations are some of the most frequent disasters SQL Server DBAs and engineers encounter. While the recovery process for the specific events which has negatively impacted the database is paramount, the next critical task in all situations is to find out who or what made the changes, what was changed and when. Gathering this information is a key for preventing other similar events which can affect SQL Server databases and endanger the data, as well as the business itself.
August 14, 2018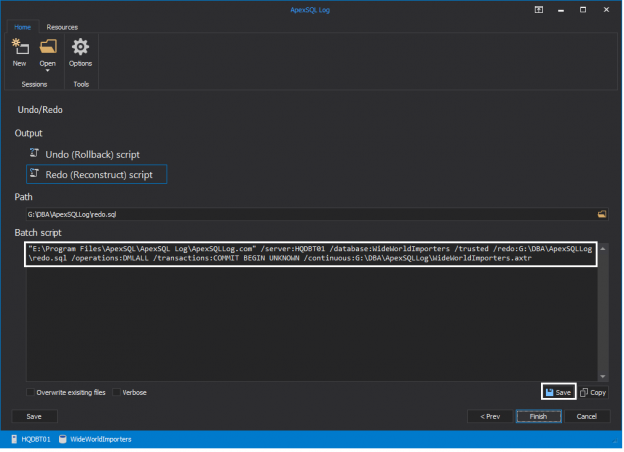
Load testing not always the same as stress testing. Stress testing seeks to maximize the load on a server to see when and where it breaks. In theory, you can escalate the load until you isolate those failure points, even to a point where the stress exerted on the server may far exceed anything that would be experienced on production
August 13, 2018ApexSQL Log is an amazing tool for reading the transaction log and reading the transaction log can form the basis of a lot of great features, functionality. In this case, we’ll look at how you can use ApexSQL Log for transactional replication to keep a reporting database up to date with your production system.
August 7, 2018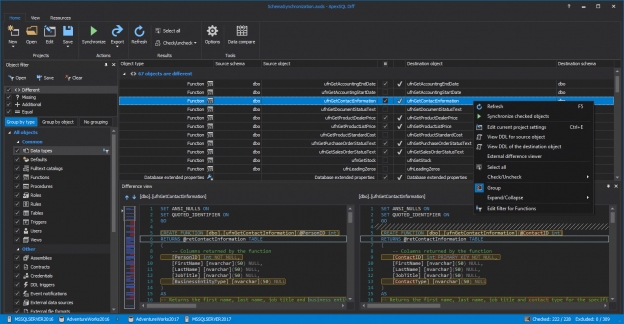
Traditionally the database has always been the bottleneck for full adoption of DevOps. For a variety of reasons continuous integration and delivery of databases is just harder than client applications. The reasons for this include the following
August 7, 2018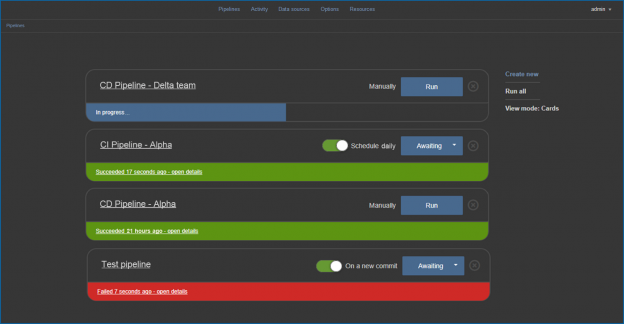
If you’ve never automated builds in SQL Server before and but are still CI-curious, then this quick high-level overview, should introduce to you the basics and maybe even lead to you wading into the water a little deeper
First, continuous integration means that you will rapidly iterate changes, so that each time a change is formally made, usually by a source control commit, then the target system, a database in our case is automatically destroyed and recreated with the change. Furthermore, the entire test environment is recreated with a combination of static and test data, any automated tests and/or reviews are conducted, and the build is fully documented.
July 26, 2018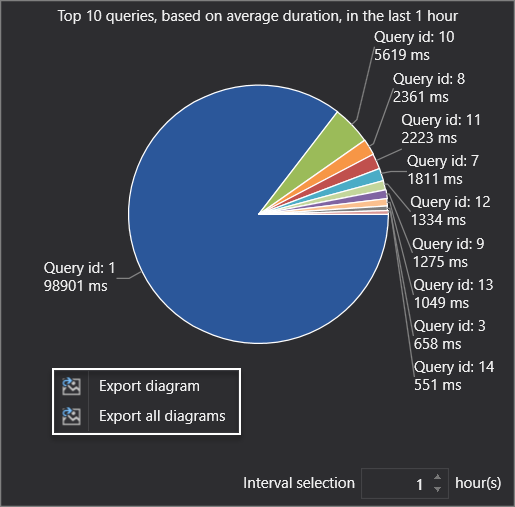
SQL execution plans AKA SQL explain plans are one of the greatest assets when it comes to tuning, optimizing, and troubleshooting our queries. Transact-SQL is a declarative language that can be used to query data without requiring a human interaction to specify an exact SQL execution plan to be followed. This simply means that we are not telling SQL Server how to go and fetch the data, we’re just telling it what data we want it to get. So, think of an execution plan in SQL Server as a map. It is a map that the query optimizer is drawing that represents an efficient SQL execution plan to retrieve the data.
July 13, 2018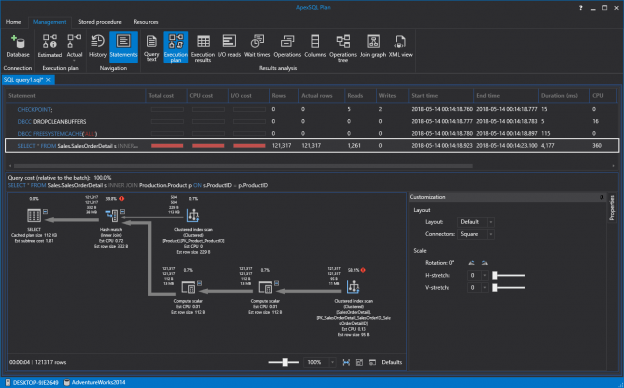
When it comes to SQL Server performance, you might not think of it as a big deal because of today’s modern hardware but every once in a while, your office phone will start ringing off the hook, your email inbox will start blowing up… SQL Server has been brought to its knees. What happened?
That’s what we are going to look at in this article. The main goal is to identify what some of the common problems are and take a close look at the SSMS Performance Dashboard tool. This tool is available out of the box for DBAs allowing them to diagnose and resolve their SQL Server performance issues quickly and easily for all supported versions of SQL Server from SQL Server 2008 to SQL Server 2017.
May 17, 2018Baselining SQL Server metrics have significant advantages over traditional predefined alert thresholds when monitoring SQL Server performance. What’s more, when tracking some wait types statistics, it is a must-have as there is no other way to interpret collected performance data correctly otherwise. However, to be able to learn how to use performance baselining and to understand its full potential some advanced knowledge will be presented first
May 11, 2018






© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy