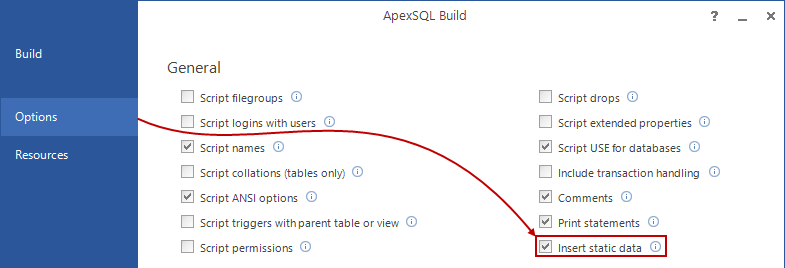
Challenge
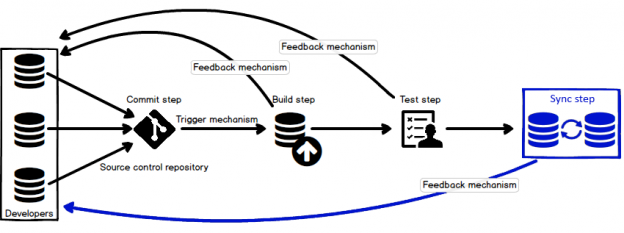
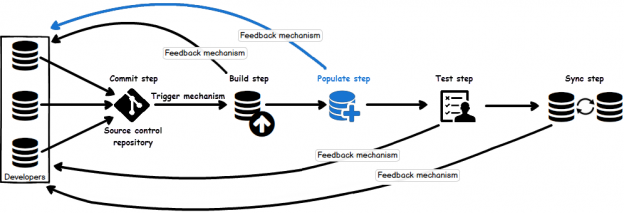
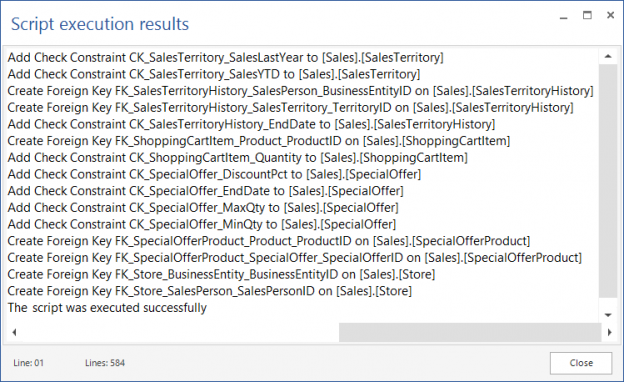
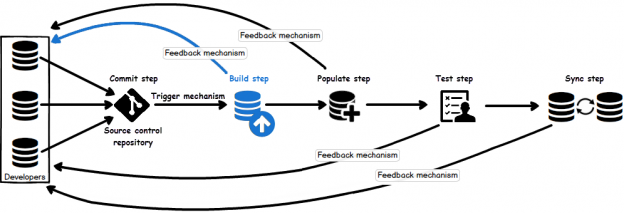
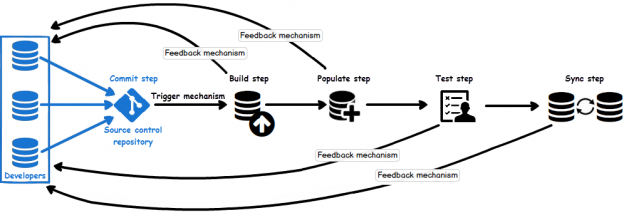
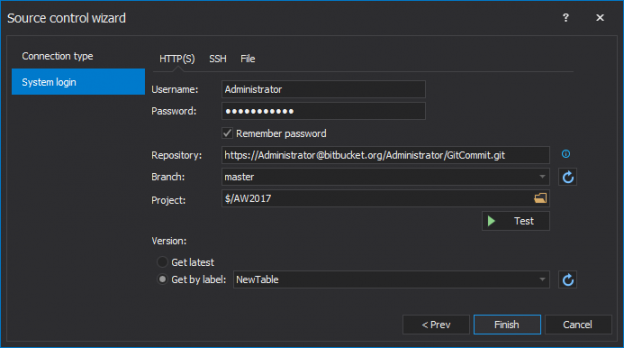
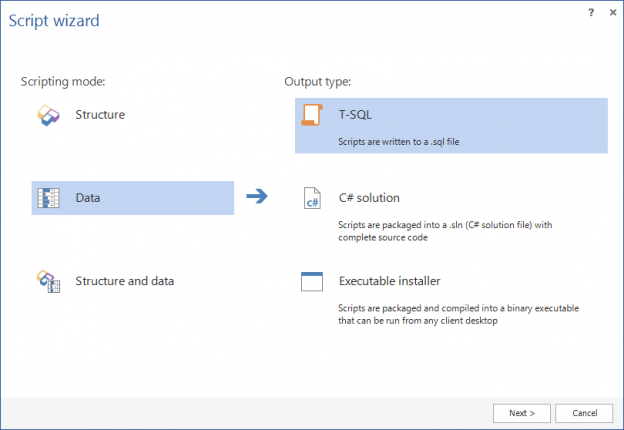
Once a SQL database is committed to a source control repository with all of its objects, the next task is to commit the static data. Static data is non-transactional data from tables that generally don’t change often like postal codes, department names, etc.. Many teams treat this type of data akin to the database structure itself, by versioning it to track changes and deploying it from source control just like database objects. As data is versioned in source control, managing it can be automated as well.
October 7, 2016