



Starting May 25, 2018 all worldwide organizations and companies that process, store or in any other way handle personal information of EU citizens have to comply with the General Data Protection Regulation (GDPR) or face heavy annual fines and penalties. In order to comply with GDPR standard, organizations will have to protect and empower all EU citizens data privacy and reshape their approach to ensure that the security of the personal information is met as per the requirements and have full transparency on any data access, processing or more.
April 20, 2018How to create and optimize SQL Server indexes for better performance
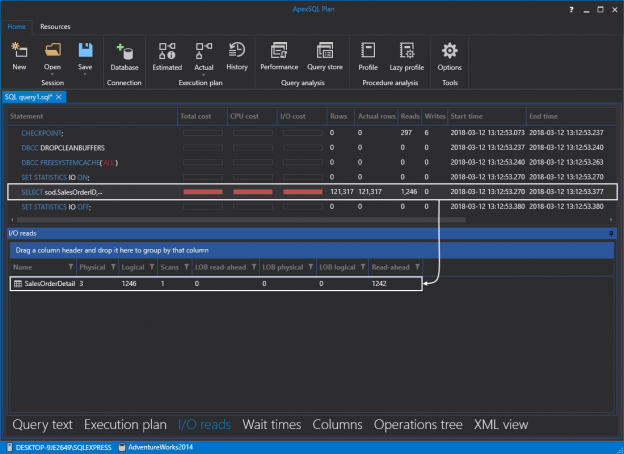
Indexes are paramount to achieving good database and application performance. Poorly designed indexes and a lack of the same are primary sources of poor SQL Server performance. This article describes an approach for SQL server index optimization to increase query performance.
March 19, 2018Visual tools for monitoring SQL Server query performance
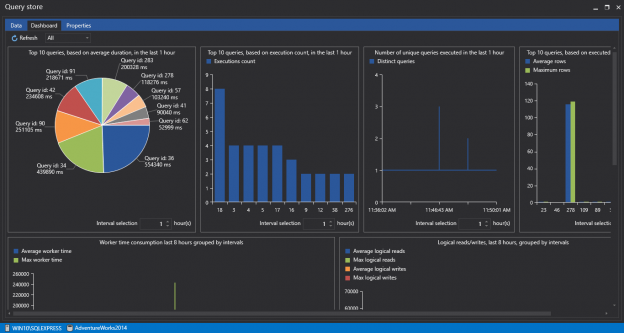
There are several ways (techniques) of monitoring query performance and finding slow queries such as System Dynamic Management Views, SQL Server Profiler, SQL Server Extended Events.
Recent to the scene, are a couple of features (tools) have appeared that make monitoring of query performance make easier than it used to be.
March 5, 2018How to optimize SQL Server query performance – Statistics, Joins and Index Tuning
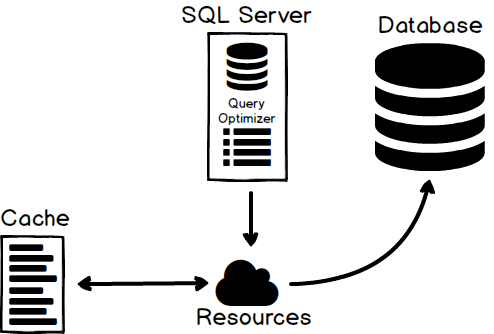
Have you ever gotten a new computer, hooked it up, and said: “this computer is blazing fast, I love it”? I have. A year from then, I was like “this computer is so slow, I need a new one”.
Performance is a big deal and this was the opening line in an article that was written on How to optimize SQL Server query performance. The initial article shows not only how to design queries with the performance in mind, but also shows how to find slow performance queries and how to fix the bottlenecks of those queries. I’d highly recommend reading the above article first because this one would give a lot more meaning but also because it’s an appendix to this topic.
February 28, 2018How to optimize SQL Server query performance
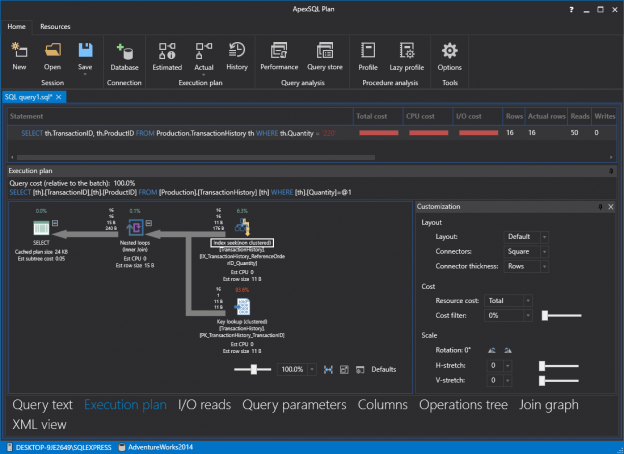
Performance is a big deal. No matter if we’re talking about applications in which users click buttons to display data or if we’re writing a query directly into let’s say SQL Server Management Studio (SSMS). Nobody likes to click a button, go get a coffee, and hope the results are ready. As computers get faster and technology moves forward users get more impatient and want things right now; without having to wait.
January 23, 2018Documenting individual build changes (vs an entire database) in a SQL Server continuous integration pipeline
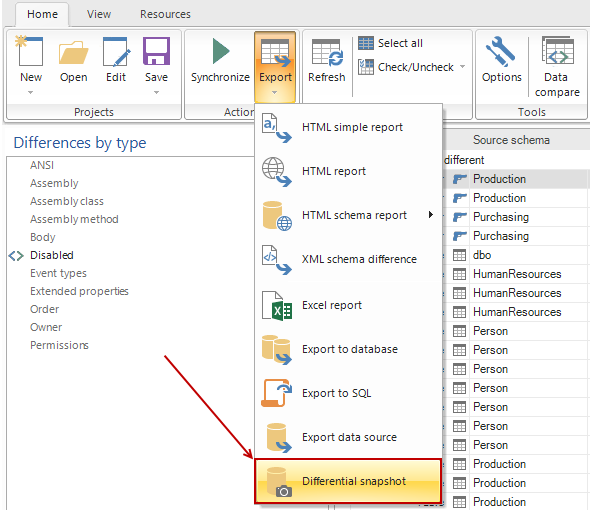
Continuous integration is great, and the more iterations, the greater it is. But with all of those changes being integrated it can be easy to lose track of what has actually changed, and when, not if, something fails reconstructing a documentation trail can be a challenge.
If a label is being created with each build, then the label “image” can be restored, depending on the source control system, or even better, you can use ApexSQL Diff to compare the latest label with the previous and see in detail exactly what changed.
But with more frequent iterations (and CI processes are considered optimal when they are triggered as frequently as possible, even on each commit), creating a label for each individual commit, or even a small group of changes, isn’t practical. As changes pile up, it can be even more difficult sorting through the change logs for auditing or diagnostics purposes.
January 18, 2018How to create and use DML triggers in SQL Server using real world examples
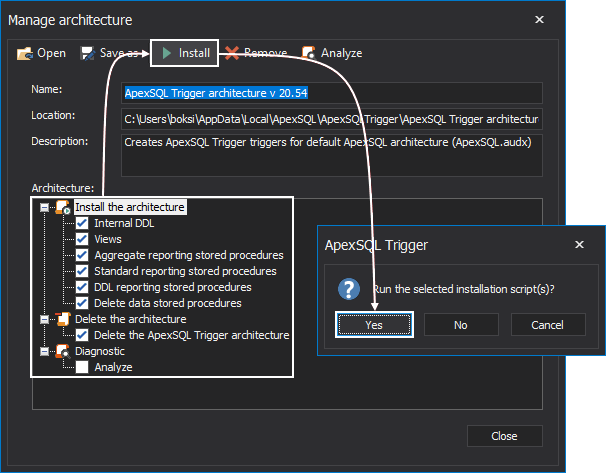
First thing first, a little background on triggers. Although often maligned, in certain circumstances they can be very helpful… once you get to know them. For example, sending an email from SQL Server could be done with a trigger based on some anticipated event.
In this article, we will focus on a case with T-SQL data modification when an Insert, Update or Delete statement hits the data in our table. As the name applies the trigger will fire and then we can make decisions on what next based on new data that is coming in or old data that is getting replaced. This is what triggers are most used for.
January 12, 2018SQL Server true detective – Solving the case of the broken database
In our case, someone has inadvertently dropped a foreign key from the specific table using the following SQL script which has left our database “broken” and it causing problems with client operations:
January 8, 2018How to monitor and detect SQL Server round-trip performance issues using custom designed metrics
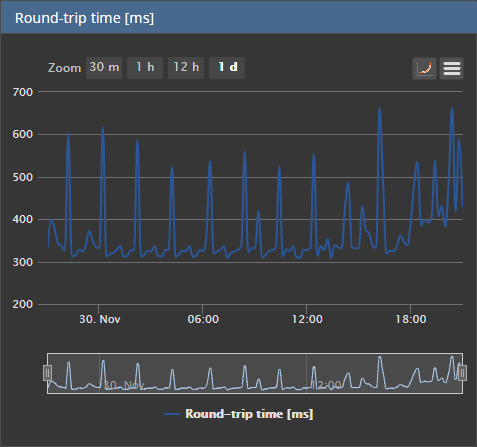
For every query issued by the application, time is needed to reach the SQL Server and then the time needed for results to get back to the application. As all communication between an application and SQL Server goes via some network (LAN or WAN), network performance could be a critical factor affecting overall performance. Two factors affect network performance: latency and throughput.
December 8, 2017How to update a SQL database from source control while avoiding dependency errors
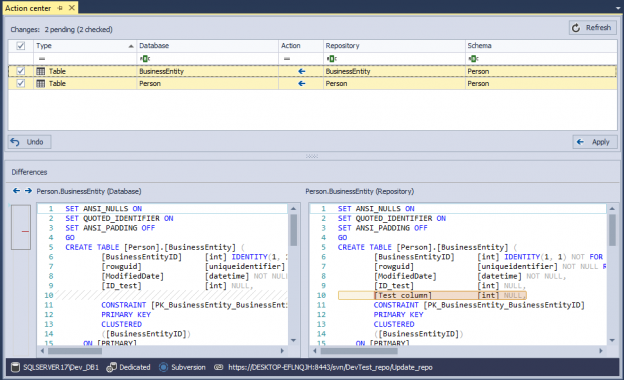
Working with a database under source control has many benefits. Beside tracking all the changes made against a database, including the information what the changes were and who made them, you can also track history of committed versions of all database objects which can be restored on a database at any point.
However, one of the benefits which will be explained in this article is comparing and syncing two copies of the same database. Using ApexSQL Source Control, all objects that are missing in one copy of a database can be created/restored in the second copy of a database, preserving the integrity of both databases.
December 7, 2017How to add self data change auditing capabilities to commercial, shrink-wrapped software with a SQL Server backend
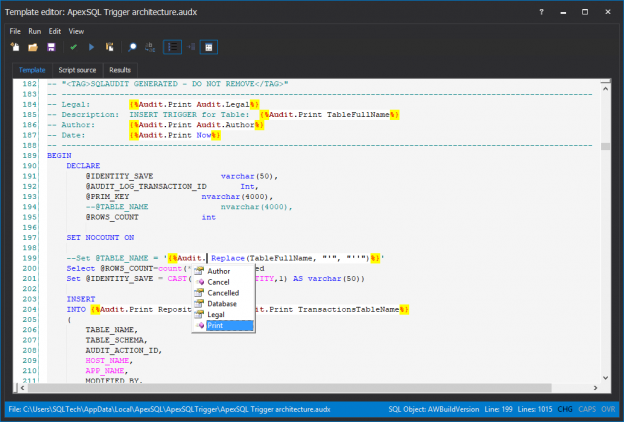
There are thousands of distributed. commercial software applications aka shrink-wrapped, from small shareware apps to large corporations, that use a SQL Server backend. These systems, although distributed, could often benefit from and sometimes require data change auditing at the client location.
Although ApexSQL sells a successful, enterprise auditing tool for SQL Server, ApexSQL Audit, this tool is often not appropriate for distributed, commercial software.
November 29, 2017How to analyze query performance characteristics in SQL Server
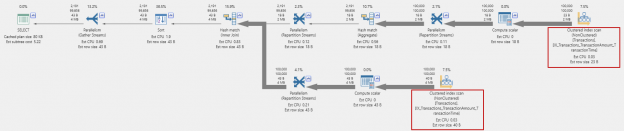
Introduction
There is a maxim that comes from the world of Python programming: “There should be one – and preferably only one – obvious way to do it.” (See The Zen of Python) in the references. While that is a good goal for any language, it is a difficult goal to achieve. T-SQL is no exception here!
Consider a simple problem: You have a customer transaction table with dated rows. You are asked to produce a list of the top transactions per day. “Top” could be defined as the one with the most items, the highest value, the most important customer or a variety of other criteria. However, you define it, at some point, you will want the maximum (or minimum) value of one of the columns. Then you will want to output the entire row (or rows, in the case of a tie) matching that value. Sounds simple, right? Well, it actually is simple, but the number of ways to do it may surprise you!
November 22, 2017How to execute an unattended best practices review against a database
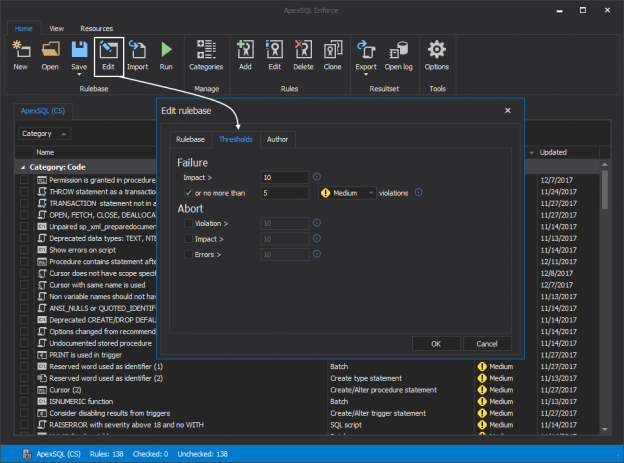
One of the many tasks of the DBA in charge on a development project is to make sure the team stays consistent in their code. Routine checks for SQL best practices such as naming conventions, right data types usage, problematic things like cursors, potentially fatal things like Deletes without Where clauses can cause a lot of headaches.
November 10, 2017How to Detect SQL Server Performance Issues Caused by Incorrect Clustered Indexes
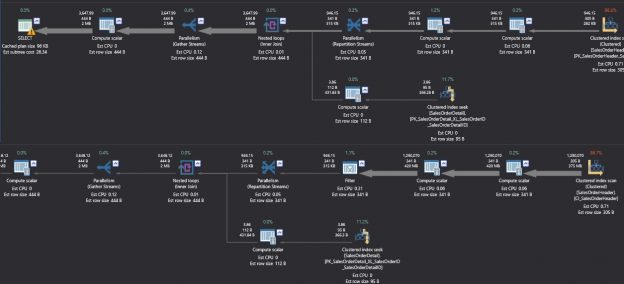
When it comes to monitoring SQL Server performance, there are a few native SQL Server solutions that provide out of the box performance monitoring. We have written about some of them here: A DBA guide to SQL Server performance troubleshooting – Part 2 – Monitoring utilities.
November 9, 2017How to create Copy-Only backups in SQL Server
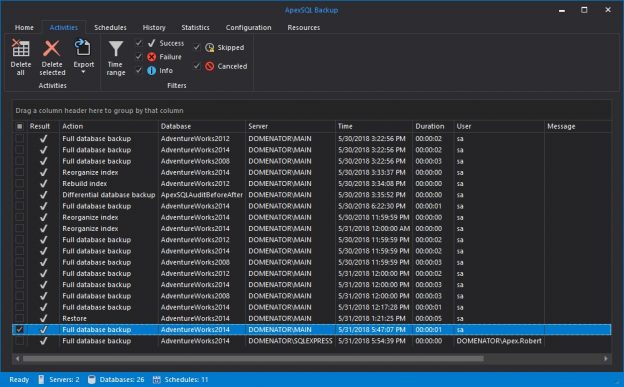
Creating a foolproof disaster recovery solution is imperative for every business. After the Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are defined, a database backup plan should be created to match these objectives. Most DBAs tend to automate the majority of tasks related to database backup plans. Regular database backup schedules are set in order to create continuous backup chains, that can later be used to recover a database in the case of a disastrous event. By setting the backup schedule, the continuity of the backup process is ensured, and most of the job is performed automatically on a regular basis.
November 7, 2017How to version control SQL scripts alongside SQL database objects
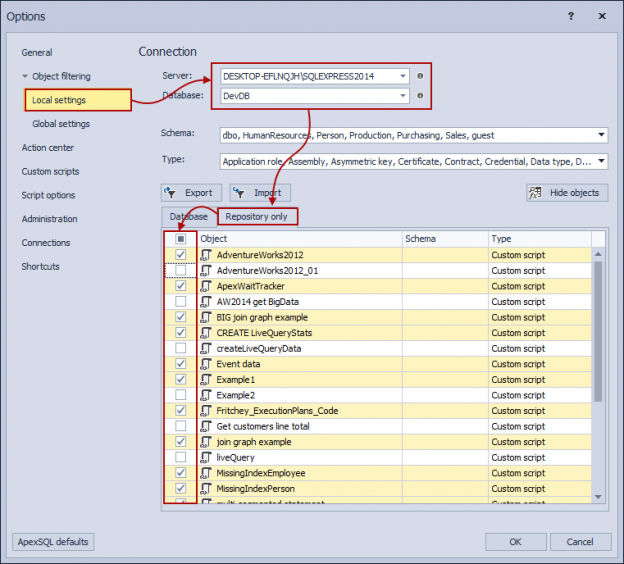
This article explains how SQL database source control can help in version control SQL scripts alongside SQL database objects. Developing a software sometimes requires versioning not only database objects, but custom SQL scripts for migration, configuration, automation or other purposes
November 3, 2017“What broke my database?” Using SQL database source control for forensic auditing and database troubleshooting
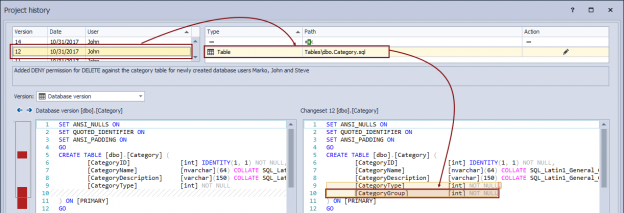
Besides the auditing trail of all the changes made against a database and having the information of who committed what and when, the main benefit of having a database under version control is the fact that the history of all the previously committed versions of any object (or a group of objects) can be used to find the exact version that broke the database at any point. Assuming that a SQL database under source control is being deployed on a daily basis or even more frequently, it is essential to ensure that only tested changes are committed so that a SQL database can be deployed in a working state, without any issues.
November 1, 2017Using SQL source control to track database changes
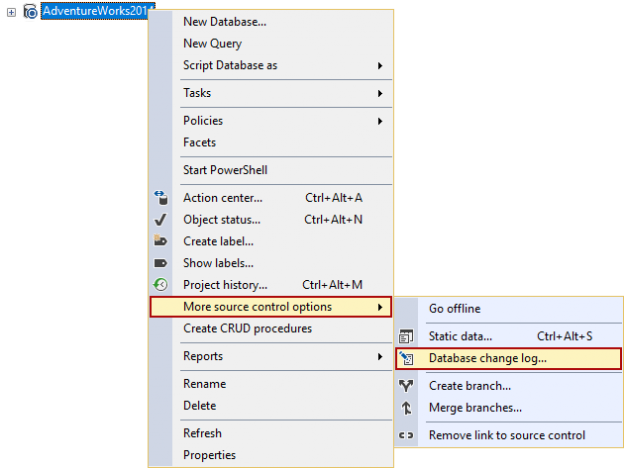
The goal of this article is to explain how SQL database source control can help in auditing database changes. Tracking a change by itself is not the only task required for successful implementation of SQL source control, as we also want to know who made the change, when and why. After all of these inputs are known, any problems and be diagnosed and be fixed efficiently. We’ll see how having a SQL database under version control can help in keeping the auditing trail with a possibility to revert back to any of the previous version of an object.
October 31, 2017Fatal action guard: guarding against inadvertent execution of code that may damage or destroy data in SQL Server
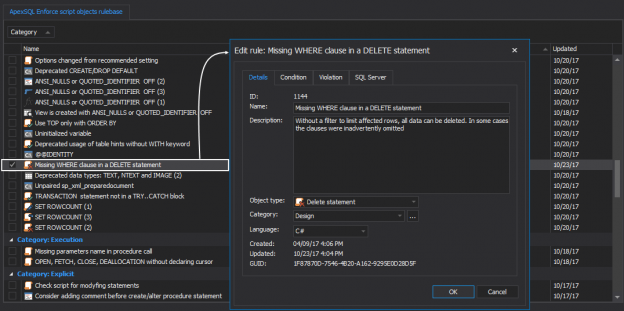
There are many opportunities, before, during, and even after to guard against potentially fatal actions that may damage or destroy data, like executing an Update or Delete statement without a Where clause. Such a fatal action guard can be implemented in different ways and at different times, relative to the incident, for example, before it to prevent it from happening in the first place, or after, to reverse an action that has already been executed.
October 24, 2017How to make SQL database version control safer with branches
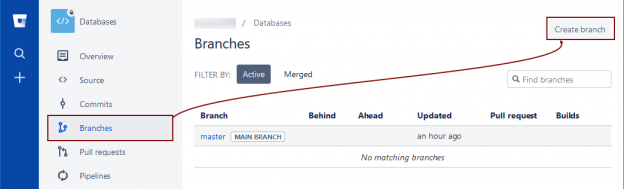
The goal of this article is to explain how to use branches in order to diverge from the main development line aka master branch and leave it unaffected by all the committed changesets that are not yet tested and confirmed as good ones. As long as a separate branch is used to commit changes, a master branch can be used to deploy a working copy of a database from source control for any purposes.
October 23, 2017





