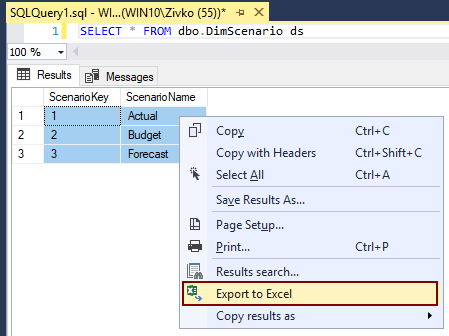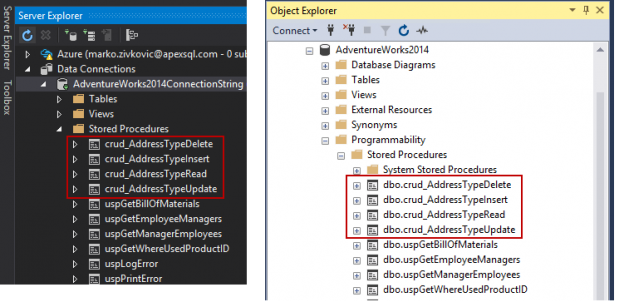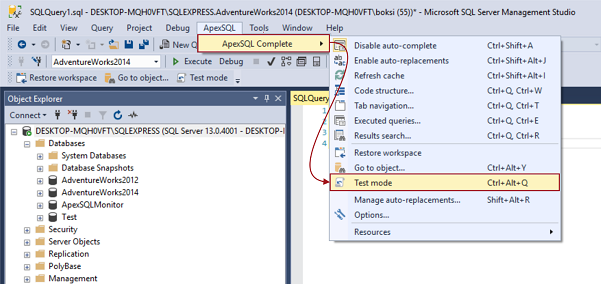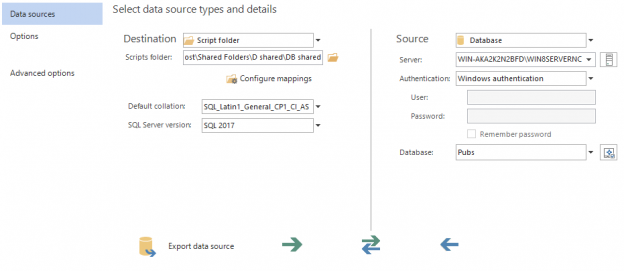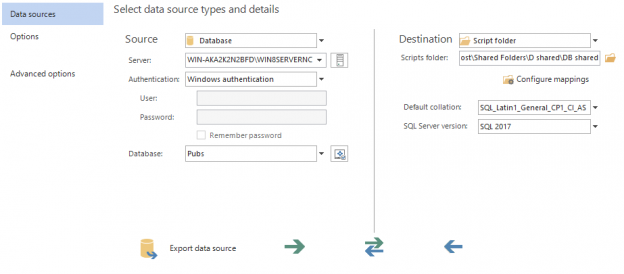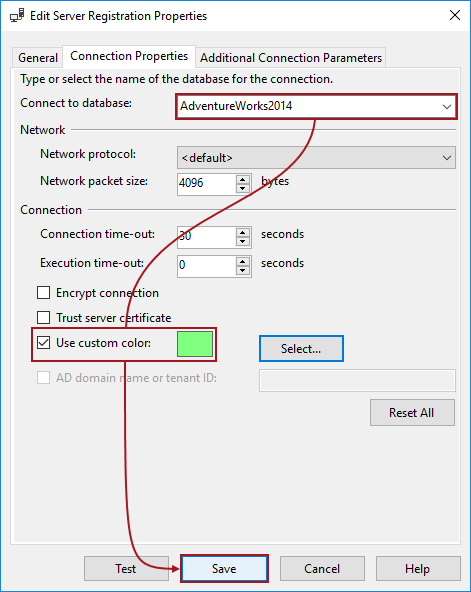
Microsoft introduced a neat feature in SQL Server Management Studio (SSMS) in SQL Server 2008 that helps users quickly determine which connection a tab is currently using by setting custom connection colors in SSMS for different SQL Server nodes.
For database administrators who work on a multiple SQL Servers simultaneously, this feature is a time-saver that allows users to quickly determine which SQL Server are currently used by looking at a color defined for the associated server.
October 18, 2017